SCAFFOLD: Stochastic Controlled Averaging for Federated Learning学习
SCAFFOLD: Stochastic Controlled Averaging for Federated Learning学习
- 背景
- 贡献
- 论文思想
- 算法
- 局部更新方式
- 全局更新方式
- 实验
- 总结
背景
传统的联邦学习在数据异构(non-iid)的场景中很容易产生“客户漂移”(client-drift )的现象,这会导致系统的收敛不稳定或者缓慢。
- ps:联邦平均算法相比传统的集中式训练,其loss会更高,并且相关的测试精度也明显低一些。部分研究工作解释为这是一个Client-drift的问题,即客户端漂移,联邦学习每个客户端的数据是非独立同分布的,各个客户端在本地训练的过程中,每个方向要与集中式训练,或者与最优的方向存在一定的偏差。联邦学习只是简单的平均,与理想的优化方向是存在一定的偏差,所以才会导致性能的下降。
贡献
- 提出了考虑到client sampling和数据异构的一个更接近的收敛边界
- 证明即便没有client sampling,使用全批次梯度(full batch gradients),传统的FedAvg依旧会因为client-drift而比SGD收敛速度更慢
- 提出Stochastic Controlled Averaging algorithm(SCAFFOLD),目的便是为了解决client-drift的问题,并证明了SCAFFOLD算法在数据异构的情况下收敛速度至少和SGD一样快
- SCAFFOLD算法还可以利用client之间的相似度来减少通信开销
- 证明了SCAFFOLD算法不会被client sampling所影响,这使得SCAFFOLD算法更适合联邦学习
论文思想
传统联邦学习的方法FedAvg算法在异构数据集上表现不好的原因是有一些client会带偏整个系统的收敛结果,如下图所示:
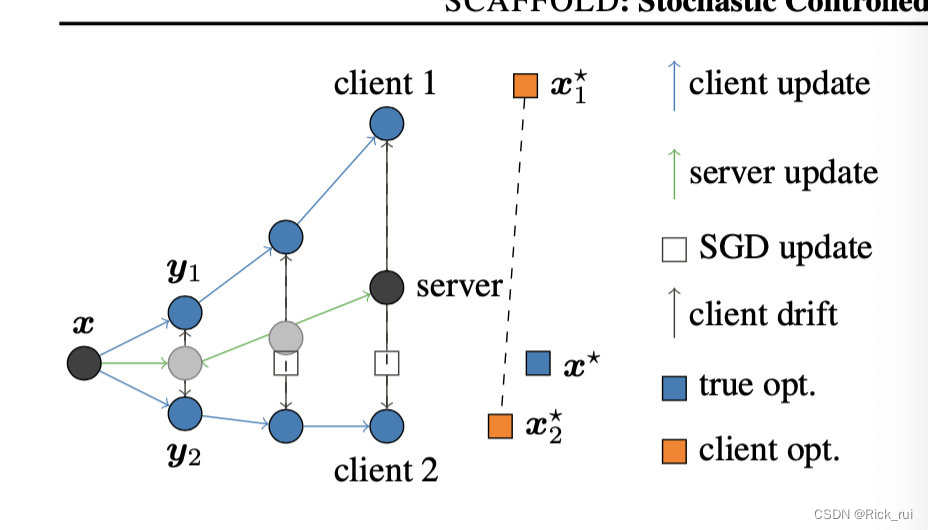
在上图中,黑色点是全局模型,也就是每个训练轮次各个局部模型的“训练起点”,假设在某一轮训练中,服务器选择了client1和client2两个客户端来训练,然后client1是偏离整个系统的客户端,那么在客户端上训练三个轮次中,我们可以看到client1上的局部模型已经偏离了训练的方向(x* 所在的方向),然后聚合得到的server model也会稍微偏离x*,使得系统向着偏离学习模型的方向上收敛。最终的结果不是造成整个系统的性能下降就是导致整个系统收敛缓慢
为了解决这个问题,论文使用一个“控制变量”(control variate)c来“纠正”系统训练的方向,在client对模型进行更新的时候,也会对该变量进行更新
算法
与传统的联邦学习类似,SCAFFOLD算法也分为三个主要的部分:
- 局部更新模型(local updates to the client model)
- 局部更新控制变量(local updates to the client control variate)
- 对局部的更新进行聚合
先给出算法的流程,后面再做出解释:

算法具体流程:

局部更新方式
SCAFFOLD算法在局部的更新方式是:
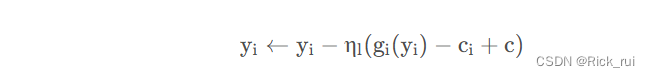
其中控制变量c的作用很明显,便是用全局模型的知识去约束局部模型的训练,以防止其偏离系统的正确训练方向,如下图所示:
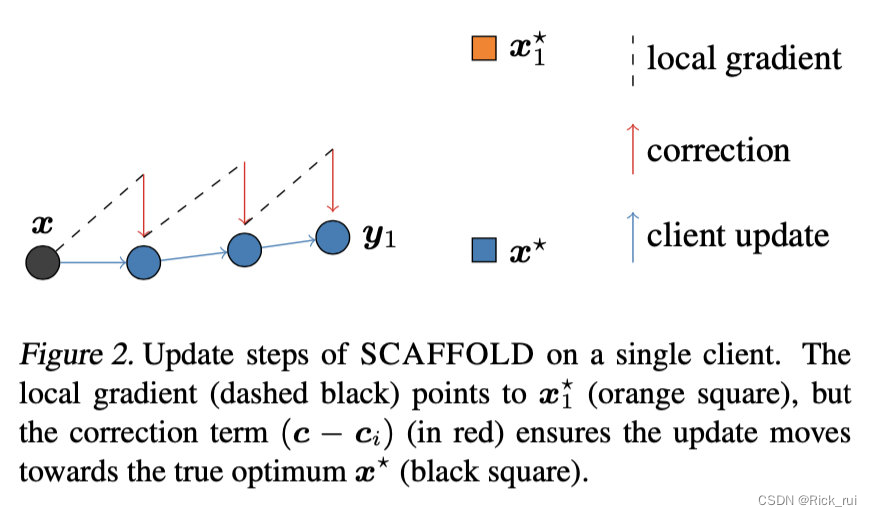
并且该控制变量也会更新,以下面的方式:
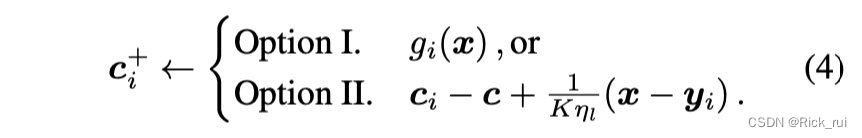
论文给给出了上面两种更新方式的选择,其中第一种是用局部的梯度来更新全局模型中的控制变量c,第二种复用了全局模型的知识,直观上理解是根据全局模型与局部模型的差异来更新c。论文中给出的上面两种选择的区别是第一种方法要更稳定,第二种方法更加取决于应用场景,但是第二种方法更容易计算并且在通常情况下也已经足够优秀
全局更新方式
对于模型的更新与传统联邦并无太大区别:
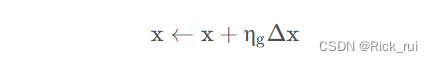
控制变量的更新:
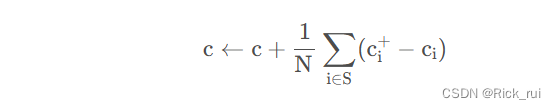
控制变量的更新方法也是和模型的更新方法差不多,本质上都是将局部模型的知识更新传递到全局模型
实验
实验在EMNIST数据集上进行,结果证明了SCAFFOLD算法与FedAvg算法和FedProx算法相比是表现最好的,如下图所示:
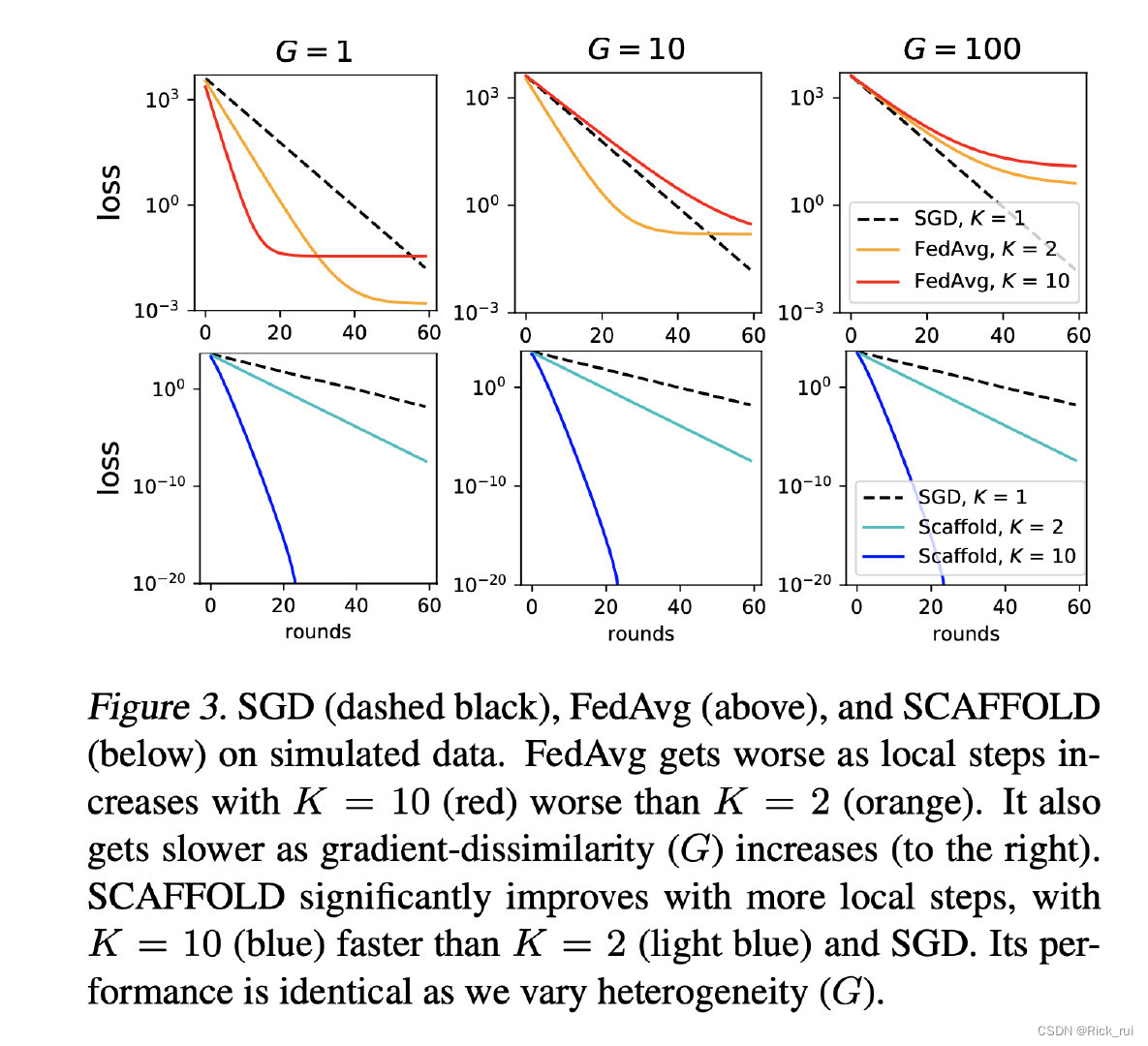
上面的3幅图表示的是SGD和FedAvg的比较实验,可以看到当梯度差异(G)很小是,FebAvg在训练刚刚开始的时候要比SGD好,但是在当G比较大的时候,由于客户容易发生“客户漂移”现象,容易带偏系统的训练方向,因此收敛效果和速度都会变差。下面的3幅图表示的是论文提出的算法Scaffold与SGD的比较,可以看到Scaffold算法无论是收敛速度和效果都比SGD要好
总结
论文的一个基本思想本质上便是用全局模型的知识去限制局部模型的训练方向,以防止那些与全局模型相差较大的局部模型带偏整个系统的训练方向