编码踩坑——MySQL order bylimit顺序不一致 / 堆排序 / 排序稳定性
本篇介绍一个MySQL下SQL查询语句同时包含order by和limit出现的一个问题及原因,其中涉及的知识点包括 :MySQL对limit的优化、MySQL的order排序、优先级队列和堆排序、堆排序的不稳定性;
问题现象
后台应用,有个表单查询接口:
允许用户设置页码的pageNum和页数据大小pageSize;pageSize则作为SQL的limit参数;
查询结果根据参数rank排序输出;rank作为SQL的order by参数;
现象:当用户分别输入不同的pageSize时(pageSize=10和pageSize=20),查询返回的结果集中,存在部分元素在先后两次查询中,相对顺序不一致;
原因分析
分析不同limit N下返回的数据,发现顺序不一致的结果集有一个共同特点——顺序不一致的这几条数据,他们用来排序的参数值rank相同;
也就是说,带limit的order by查询,只保证排序值rank不同的结果集的绝对有序,而排序值rank相同的结果不保证顺序;推测MySQL对order by limit进行了优化;limit n, m不需返回全部数据,只需返回前n项或前n + m项;
上面的推测在MySQL官方文档中找到了相关的说明:
If an index is not used for ORDER BY but a LIMIT clause is also present, the optimizer may be able to avoid using a merge file and sort the rows in memory using an in-memory filesort operation. For details, see The In-Memory filesort Algorithm.
解释:在ORDER BY + LIMIT的查询语句中,如果ORDER BY不能使用索引的话,优化器可能会使用in-memory sort操作;
关于排序方法
思考下对于这种排序问题,如果让我们自己处理,会如何做?——其实本质上就是topN的解决方法;回顾一下排序算法,适用于取前n的算法也只有堆排序了;
那么,MySQL会不会也使用了类似的优化方法呢?
参考The In-Memory filesort Algorithm可知MySQL的filesort有3种优化算法,分别是:
基本filesort
改进filesort
In memory filesort
而上面的提到的In memory filesort,官方文档这么说明:
The sort buffer has a size of sort_buffer_size. If the sort elements for N rows are small enough to fit in the sort buffer (M+N rows if M was specified), the server can avoid using a merge file and performs an in-memory sort by treating the sort buffer as a priority queue.
这里提到了一个关键词——优先级队列;而优先级队列的原理就是二叉堆,也就是堆排序;下面简单介绍下堆排序;
堆排序
什么是堆?
堆是一种特殊的树,它满足需要满足两个条件:
(1)堆是一种完全二叉树,也就是除了最后一层,其他层的节点个数都是满的,最后一个节点都靠左排列;
(2)堆中每一个节点的值都必须大于等于(或小于等于)其左右子节点的值;
对于每个节点的值都大于等于子树中每个节点值的堆,叫作“大顶堆”;
对于每个节点的值都小于等于子树中每个节点值的堆,叫作“小顶堆”;
堆的存储?
用数组来存储完全二叉树是非常节省内存空间的,因为我们不需要存储左右子节点的指针,单纯通过数组的下标,就可以找到一个节点的子节点和父节点;
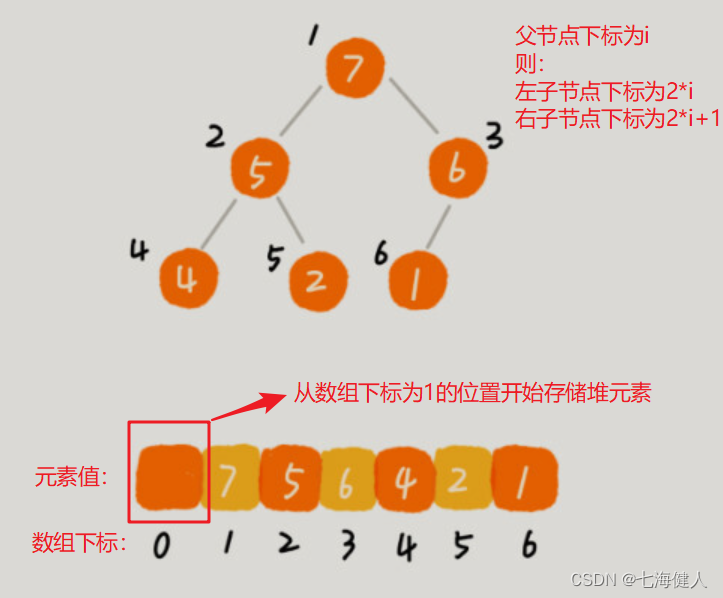
从图中我们可以看到,数组中下标为 i 的节点的左子节点,就是下标为 i∗2 的节点,右子节点就是下标为 i∗2+1的节点,父节点就是下标为i/2的节点;
堆的核心操作
堆尾部插入元素;可用作堆排序的初始化操作,把排序的数组元素按顺序插入堆;
例如:在已经建好的堆中插入值为“22”的结点,这时候就需要重新调整堆结构,过程如下:
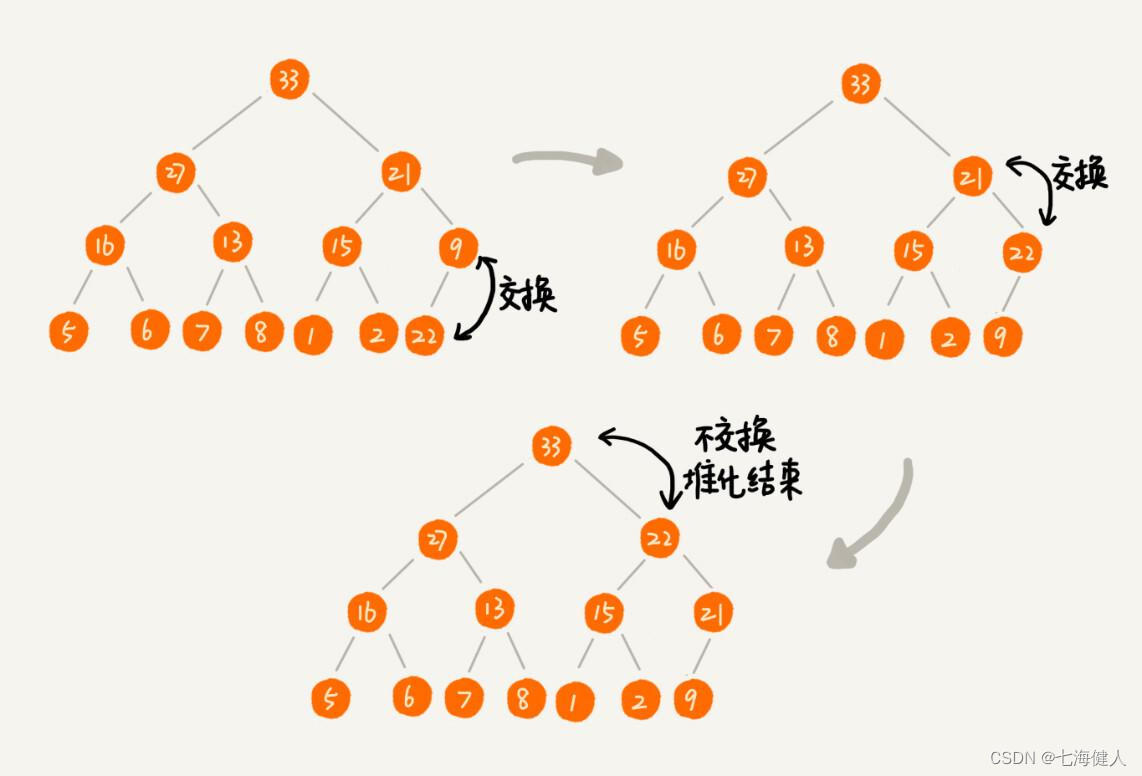
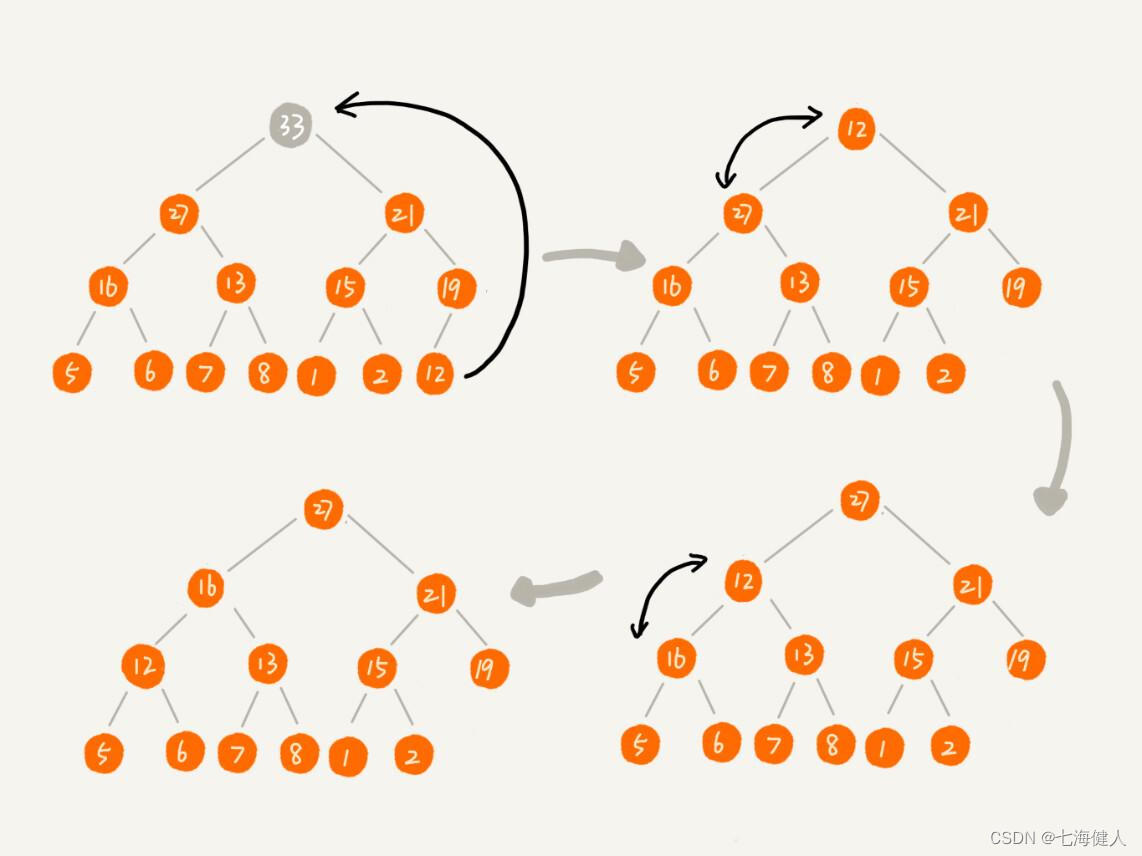
2.堆顶的移出操作;可用作堆排序的取出最大值(大顶堆)操作,把堆尾部元素放到堆顶,从上到下重新做"堆化"操作(对于不满足父子节点大小关系的,互换两个节点,并且重复进行这个过程,直到父子节点之间满足大小关系为止);
例如:删除堆顶的“33”结点,删除步骤如下:
堆排序
堆排序是指利用堆这种数据结构进行排序的一种算法;
排序过程中,只需要个别临时存储空间,所以堆排序是原地排序算法,空间复杂度为O(1);
堆排序的过程分为建堆和排序两大步骤;建堆过程的时间复杂度为O(n),排序过程的时间复杂度为O(nlogn),所以,堆排序整体的时间复杂度为O(nlogn);
堆排序不是稳定的算法,因为在排序的过程中,存在将堆的最后一个节点跟堆顶节点互换的操作(也就是上面提到的"堆顶的移出操作"),所以可能把值相同数据中,原本在数组序列后面的元素,通过交换到堆顶,从而改变了这些值相同的元素的原始相对顺序;因此是不稳定的;
——这也就是为什么当改变SQL的limit的大小,返回的排序结果中,相同排序值rank的记录的相对顺序发生变化的根本原因!
堆排序步骤
(1)建堆:建堆结束后,数组中的数据已经是按照大顶堆的特性组织的;数组中的第一个元素就是堆顶;
(2)取出最大值(类似删除操作):将堆顶元素a[1]与最后一个元素a[n]交换,这时,最大元素就放到了下标为n的位置;
(3)重新堆化:交换后新的堆顶可能违反堆的性质,需要重新进行堆化;
(4)重复(2)(3)操作,直到最后堆中只剩下下标为1的元素,排序就完成了;

堆排序相关代码示例(Java)
ltodo
小结
现象:SQL查询语句同时包含order by和limit时,当修改limit的值,可能导致"相同排序值的元素之间的现对顺序发生改变"
原因:MySQL对limit的优化,导致当取到指定limit的数量的元素时,就不再继续添加参与排序的记录了,因此参与排序的元素的数量变化了;而MySQL排序使用的In memory filesort是基于优先级队列,也就是堆排序,而堆排序时不稳定的,会改变排序结果中,相同排序值rank的记录的相对顺序;
建议:排序值带上主键id,即order by rank 改为 order by rank, id 即可;
本文参考:
https://zhuanlan.zhihu.com/p/49963490
https://www.cnblogs.com/cjsblog/p/10874938.html
https://blog.csdn.net/qq_55624813/article/details/121316293