【SPSS】数据预处理基础教程(附案例实战)

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+

SPSS(Statistical Product and Service Solutions),“统计产品与 服务解决方案”软件。最初软件全称为“社会科学统计软件包” (Solutions Statistical Package for the Social Sciences),但是 随着SPSS产品服务领域的扩大和服务深度的增加,SPSS公司已于 2000年正式将英文全称更改为“统计产品与服务解决方案”,这标志 着SPSS的战略方向正在做出重大调整。SPSS为IBM公司推出的一系 列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软 件产品及相关服务的总称,有Windows和Mac OS X等版本。
目录
基础介绍
1.SPSS数据文件
2.变量
基础操作
1.SPSS数据文件合并
2.数据排序
3.查找重复个案
4.变量计算
5.数据选取
6.计数
7.分类汇总
8.数据分组
9.数据转置
10.加权处理
11. 数据拆分
基础介绍
1.SPSS数据文件

SPSS数据文件的特点 :SPSS数据文件也称数据集(dataset),是一种有结构的数据文件,扩展名是.sav。
SPSS数据的基本组织方式
原始数据的组织方式:如果待分析的数据是一些原始的调查问卷数据,或是一些基本的 统计指标,这些数据就可按原始数据的方式组织。
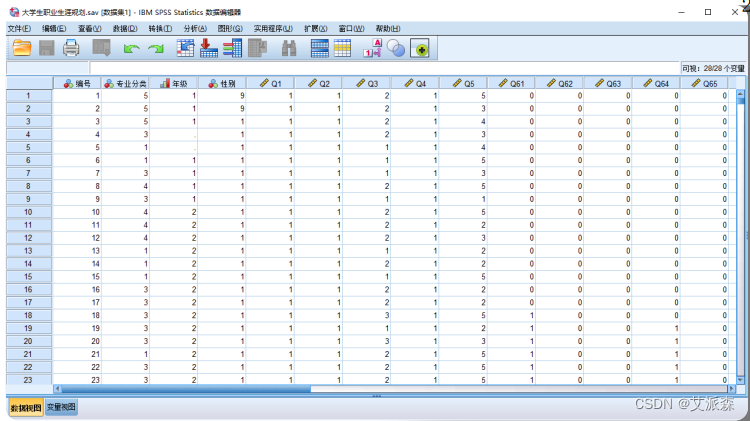
在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个 案(case)或观测,所有个案组成完整的SPSS数据。数据编辑器窗口中的一列称为一个变量。
计数数据的组织方式:当采集的数据是经过分组汇总后的计数数据时,可按计数数据的 方式组织。
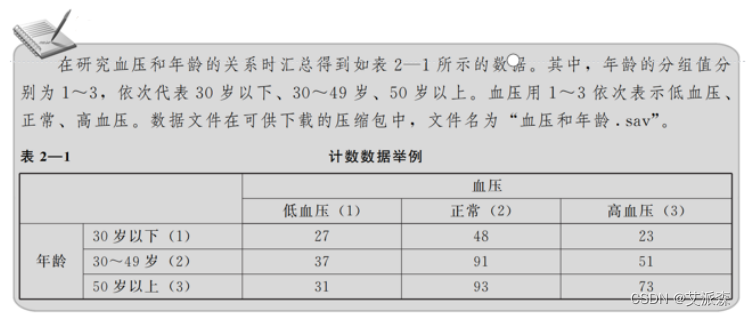
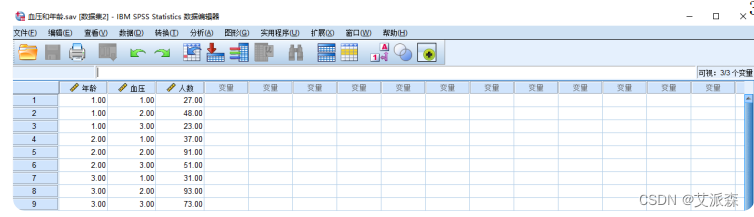
在计数数据的组织方式中,数据编辑器窗口中的一行为变量的 一个分组 (或多变量交叉分组下的一个分组)。所有行囊括了该变量的所有分组情况 (或多变 量交叉下的所有分组情况)。数据编辑器窗口中的一列仍为一个变量,代表某个问题 (或某个方面的特征)以及相应的计数结果。
2.变量
在变量视图中定义变量,在数据视图中输入数据。
变量名
- 首字符以字母或汉字开头,变量名不能包括?,*,!
- 允许汉字作为变量名
- 下划线(不建议)、原点不能作为变量名的最后一个字符
- 不能与SPSS内部的保留字相同(ALL、BY、AND、NOT、OR等)
- 变量名不区分大小写字母
- 在SPSS变量视图的【名称】列下相应行的位置输入变量名即可
变量类型
SPSS中有三种基本变量类型
- 数值型
- 字符串型
- 日期型
- 在SPSS变量视图的【类型】列下相应行的位置单击鼠标,并选择数据类型
变量名标签
- 变量名标签是对变量名含义的进一步说明
- 在SPSS变量视图的【标签】列下相应行的位置输入变量名标签即可
变量值标签
- 变量值标签是对变量取值含义的解释说明信息,对于定类变量和 定序变量尤为重要
- 在SPSS变量视图的【值】列下相应行的位置单击鼠标,并根据 实际数据在弹出窗口中指 定变量值标签
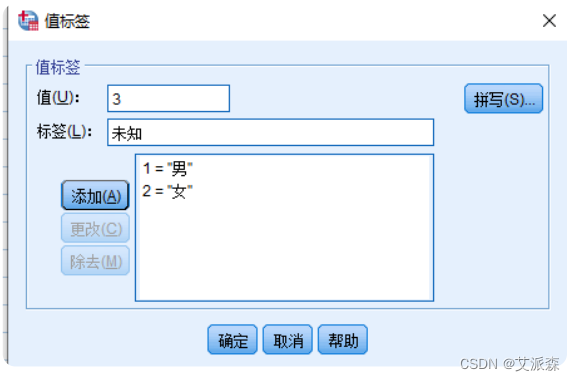
缺失数据
- 明显不合理或漏填的数据都可看做缺失数据
- SPSS中说明缺失数据的基本方法是指定用户缺失值
- 1 在空缺数据处填入某个特定的标记数据(如99999999)
- 2 指明这个特定的标记数据以及那些明显不合理的数据为缺失数据
- 在SPSS变量视图的【缺失】列下相应行的位置单击鼠标,并根 据实际数据在弹出窗口指定缺失值
测量
测量主要用于测量变量的测量标准。有标度、名义、有序三个值。
- 标度指有大小值的数据。
- 有序指有序号的数据比如第一名、第二名,有顺序的。
- 名义指没有次序没有大小的数据如性别中男和女就没有大小也没有次序。
- 在SPSS变量视图的【测量】列下相应行的位置单击鼠标,并选择测量尺度
角色
- 角色指变量有角色分配,是输入变量还是目标变量,或者其他角色
- 在SPSS变量视图的【角色】列下相应行的位置单击鼠标,并选择变量角色
基础操作
1.SPSS数据文件合并

当数据量较大时,经常会把一份大的数据分成几个小的部分,分别录入,录入完毕后, 就必须将若干个小的数据文件合并起来。
纵向合并
将一个SPSS数据文件的内容追加到当前数据编辑器窗口中数据的后面,依据两份数据文件中的变量名进行数据对接。
纵向合并注意: 两个待合并的数据文件的内容合并起来应是有实际意义的不同文件中含义相同的数据项最好取相同的变量名,且数据类型也最好相同,这样将大大简化操作过程。
【案例】—— 职工数据和追加职工数据的合并
①打开“职工数据.sav”
②选择菜单【数据】----> 【合并文件】-----> 【添加个案】
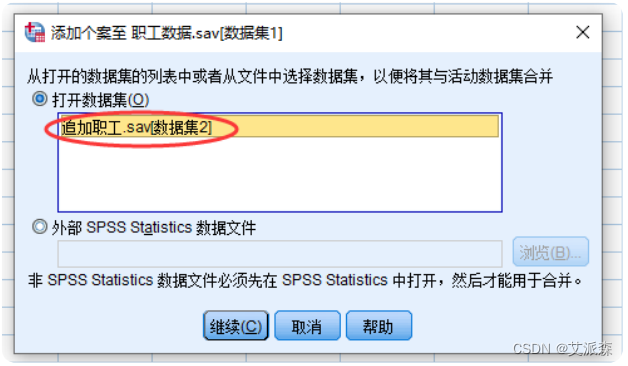
③点击“继续”,进行合并数据的变量设置
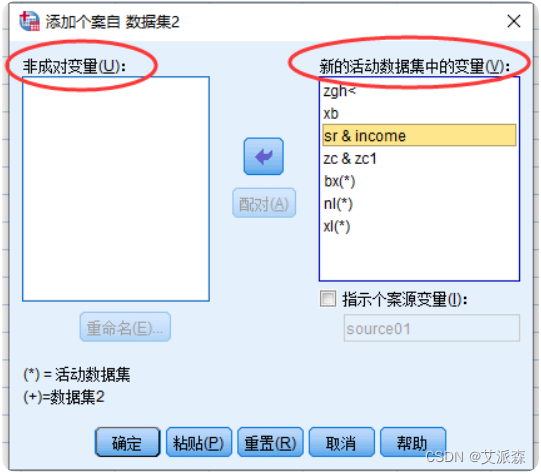
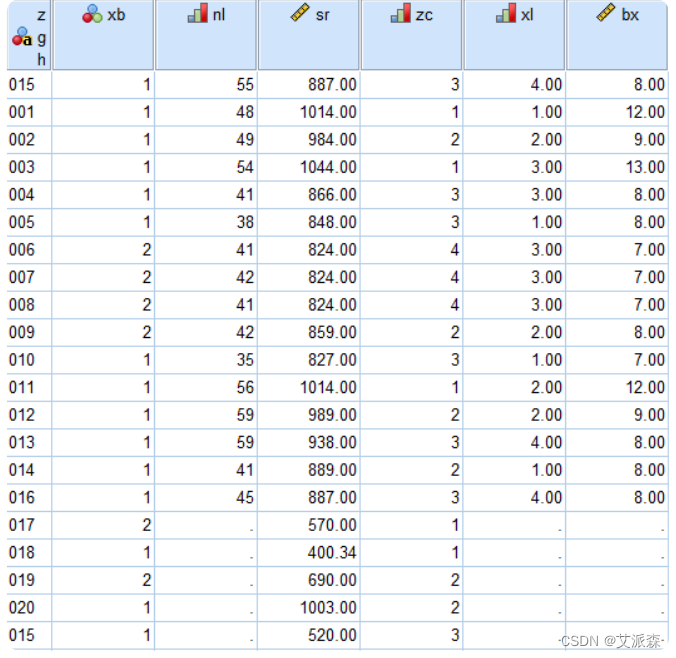
④点击“确定”,最终的合并效果是
横向合并
将一个 SPSS数据文件的内容拼到数据编辑器窗口中当前数据的右边, 依据两个数据文件中的个案进行数据对接。
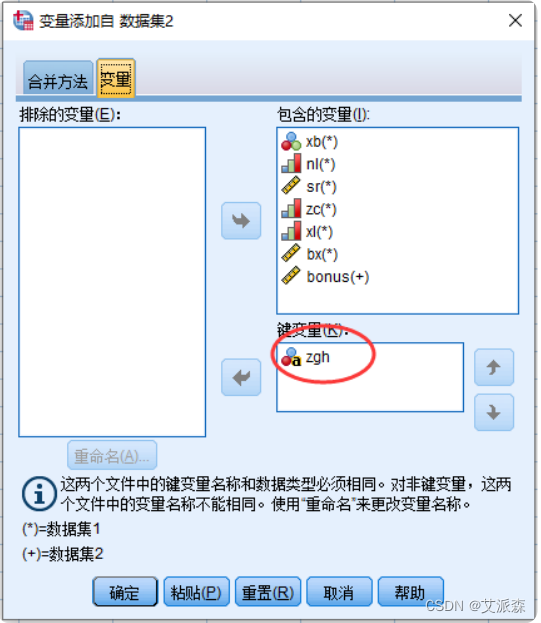
横向合并注意: 两个待合并的数据文件至少有一个名称相同的变量,该变量是两个数据文件横向拼接的依 据,称为关键变量 为方便横向合并,不同数据文件中含义不同的数据项,变量名不应相同。
【案例】—— 职工数据和职工奖金数据的合并
①打开“职工数据.sav”
②选择菜单【数据】----> 【合并文件】-----> 【添加变量】
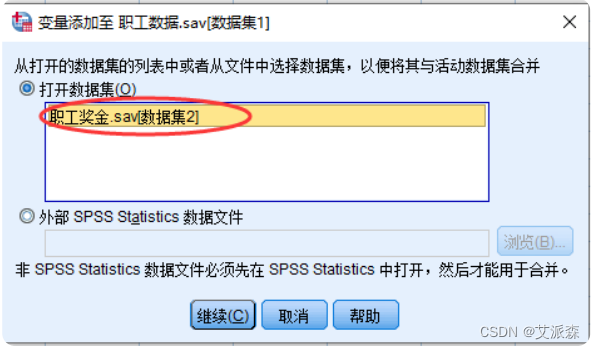
③点击“继续”
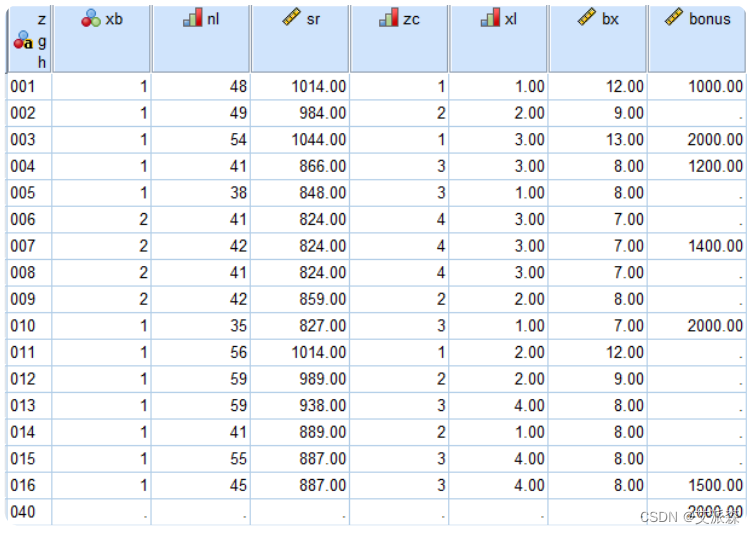
④最终合并效果
2.数据排序

数据排序的目的
- 便于数据的浏览
- 初步把握和比较数据的离散程度
- 快捷地发现数据中可能异常的值
数据排序案例
对职工基本情况数据进行排序,以职称为主排序变量(降序),基本工资为第二排序 变量(升序)进行多重排序。
【操作步骤】:
①选择菜单 【数据(D)】—> 【个案排序】
②依次指定排序变量到【排序依据】框中,并选择【排列顺序】框中的选项指出该变量按升序还是降序排序
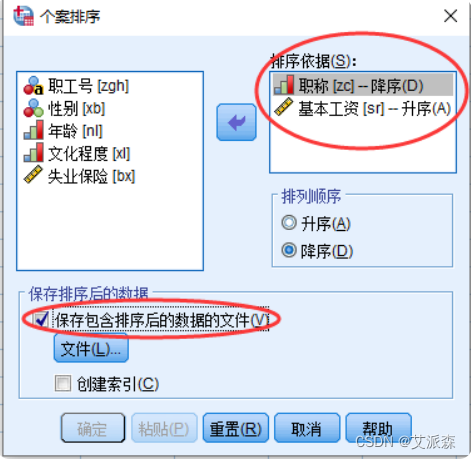
可以通过勾选【保存包含排序后的数据的文件(V)】将排序结 果保存到用户指定的.sav文件中。
注意:
- 数据排序是对整行数据排序,而不是只对某列变量排序
- 多重排序中指定排序变量的次序很关键,先指定的变量优于后指定的变量
3.查找重复个案

SPSS查找重复个案的方法
1.首先按照用户指定的关键变量对所有个案排序,于是关键变量值相同的个案,也即重复个案将被排 在一起(归为同一组)。
2.为便于用户确定具有相同关键变量值的重复个案中哪个个案是正确的,还需要指定重复个案的排序变量。
【案例】—— 找到纵向合并后的职工数据的重复个案
①选择菜单【数据】---> 【标识重复个案】
②在"标识重复个案"对话框中选择对应选项
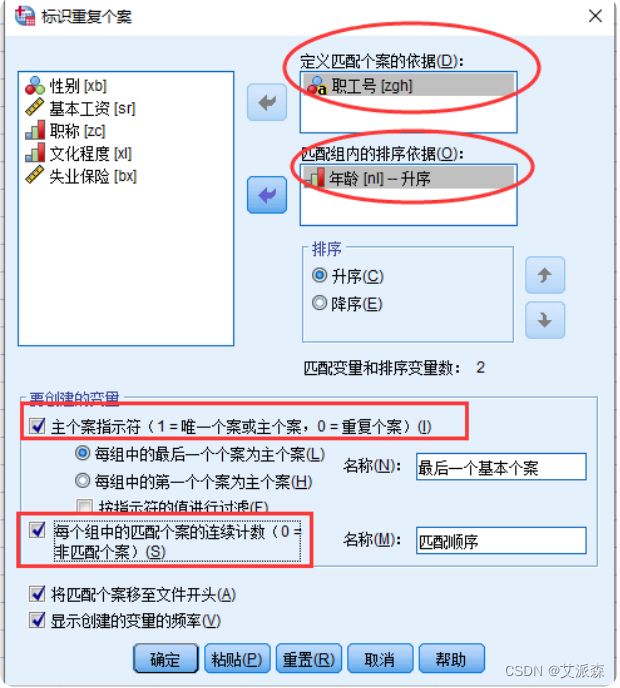
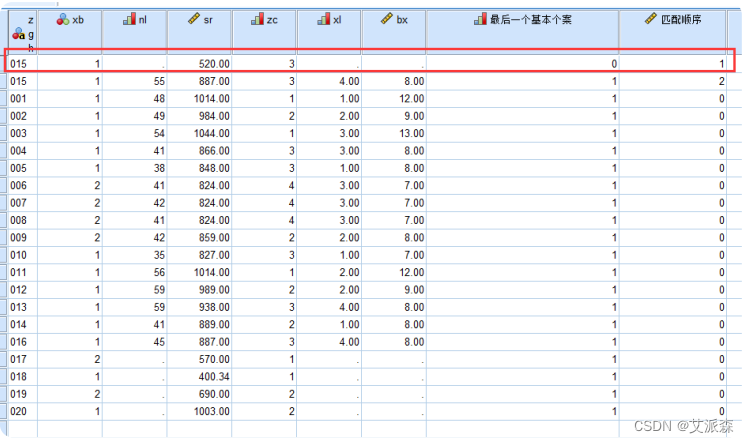
③如下图所示,红色框中的个案被认为是重复的
4.变量计算

变量计算的目的:变量计算是数据分析过程中应用最广泛且最重要的一环。通过变量计算可以处理许多问题:
①派生新变量 在原有数据的基础上,计算产生一些含有更丰富信息的新数据。例如:根据职工的基本工资、失业保险、奖金等数据项,计算实际月收入。
②变换数据的原有分布例如,对非正态变量的对数变换;标准化处理等。
SPSS算术表达式
是由常量、变量、算术运算符、圆括号、函数等组成的式子
- 变量是指那些已存在于数据编辑器窗口中的已有变量
- 算术运算符主要包括:+(加)、-(减)、∗(乘)、/(除)、∗∗ (乘方)
- 操作对象的数据类型为数值型
- 运算的先后次序是:先计算乘方,再计算乘除,最后计算加减。在同级运算中,按从左往右的顺序进行计 算。通过圆括号改变原有的计算顺序
- 在同一算术表达式中的常量及变量,数据类型应该一致,否则无法计算
SPSS条件表达式
条件表达式是一个对条件进行判断的式子。如果判断条件成立,则 结果为真;否则结果为假。
- 简单条件表达式:由关系运算符、常量、变量以及算术表达式等组成的式子。其中, 关系运算符包 括>(大于)、=(大于等于)、<=(小于等于)。
- 复合条件表达式:又称逻辑表达式,是由逻辑运算符、圆括号和简单条件表达式等组成 的式子。其 中,逻辑运算符包括 & 或 AND (并且)、|或OR(或者)、~或NOT (非)。 NOT的运算最优先,其次是 AND,最后是OR。可以通过圆括号改变这种运算次序。
SPSS函数
函数是事先编好并存储在SPSS软件中,能够实现某些特定计算任 务的一段计算机程序。 这些程序段都有各自的名字,称为函数名,执行这些程序段得到的计算结果称为函数值。
几类SPSS函数:
- 算术函数
- 统计函数
- 与分布相关的函数
- 查找函数
- 字符串函数
- 日期函数
- 缺失值函数
- 其他函数
【案例】—— 计算专业和职业的认知得分
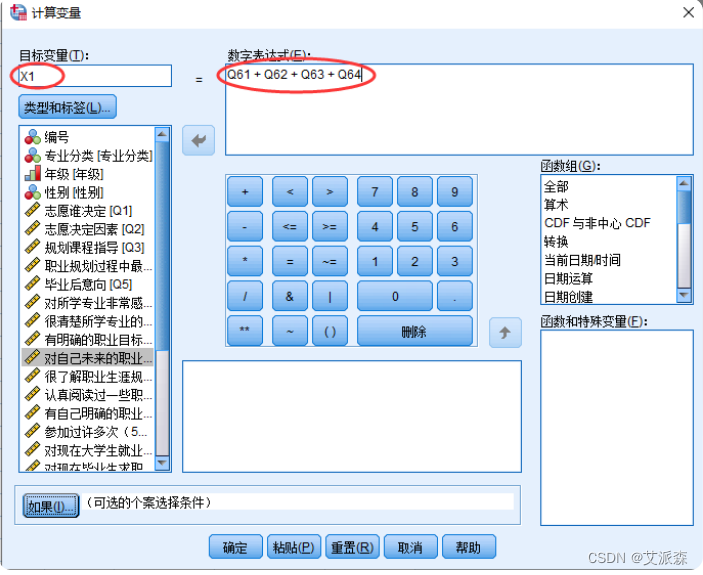
①选择菜单【转换】---> 【计算变量】
②填写数学表达式和目标变量
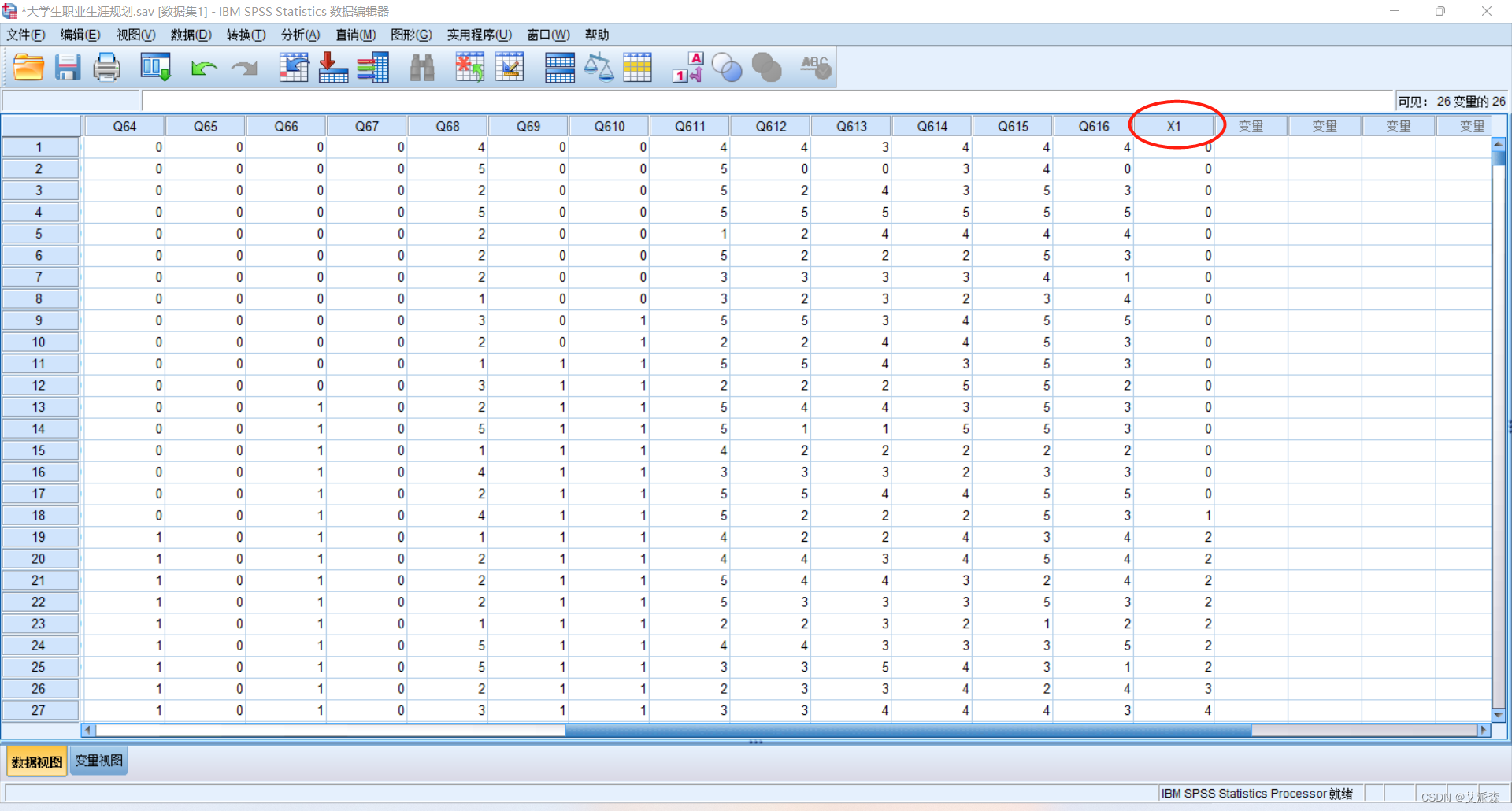
③发现最终多了一列X1,该列是用来存储专业和职业的认知得分的
5.数据选取

数据选取的目的:数据选取就是根据分析的需要,从已收集到的大批量数据 (总 体)中按照一定的规则抽取部分数据 (样本)参与分析。
数据选取方法
- 按指定条件选取
- 随机选取
- 近似选取:SPSS按照指定的百分比数值随机抽取相应百分比数目的个案,可能会有小的偏差
- 精确选取:SPSS会在前若干个个案中随机精确地抽出指定的个案数
- 选取某一区域内的样本
- 使用过滤变量选取
指定一个变量作为过滤变量,变量值为非0或非系统缺失值的个案将被选中。这种方法通常用于排除包含系统缺失值的个案。
【案例】 对大学生职业生涯规划数据,选取听过职业规划课程指导课程的学生
①选择菜单【数据】-----> 【选择个案】
②本案例使用按照指定条件选取的方式选择个案
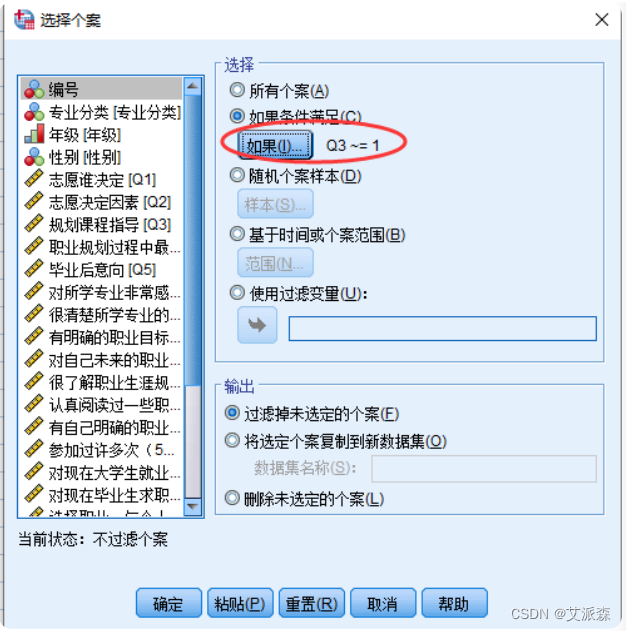
③可以看到,选择的结果
6.计数

数据计数
SPSS实现的计数是对所有个案或满足某条件的部分个案,计算若 干个变量中有几个变量的值落在指定的区间内,并将计数结果存入一 个新变量的过程。
关键步骤: ①指定哪些变量参与计数,计数的结果存入哪个新变量中②指定计数区间
【案例】在大学生职业生涯规划数据中,学生对问卷中Q61~Q616问题感觉 不好回答(对应问题的量表得分为0,说明该问题不好回答)的计数。
①选择菜单【转换】---> 【对个案中的值进行计数】
②在窗口中输入存放计数结果的目标变量名称,并选择相应的数字变量。这里,选择参与计数的变量为Q61~Q616。
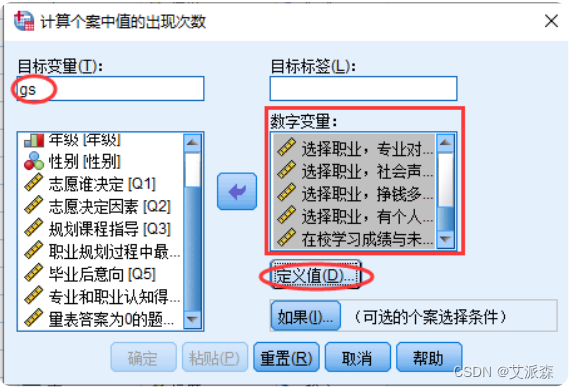
③点击【定义值】按钮定义计数区间
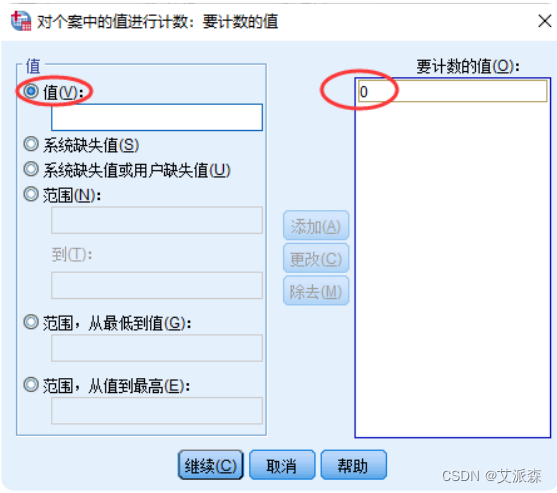
④点击继续,确定,发现最终多了一个计数的新变量gs
至此,SPSS将对所有个案计算Q61~Q616这16个变量中有几个取0,并将结果放在变量gs中。
7.分类汇总

分类汇总概念 :分类汇总是按照一个或多个分类变量进行分类计算。
例如,某企业希望了解本企业不同学历职工的基本工资是否存在较大差距,最简单的做法就是分类汇总,即将职工按学历进行分类,然后分别计算不同学历职工的平均工资,就可对平均工资进行比较;
主要涉及: 1.按照哪个变量进行分类 2.对哪个变量进行汇总,并指定对汇总变量计算哪些统计量
注意:
1.分类汇总中的分类变量可以有多个,此时的分类汇总称为多重分类汇总
2.在多重分类汇总中,多个分类变量的前后次序决定了分类汇总的先后次序
【案例】 大学生职业生涯规划数据,按照专业类别分类对专业和职业认知得分计算平均分
①选择菜单【数据】----> 【汇总】
②在汇总数据框中选择分界变量(分类变量)、变量摘要(汇总变量),并指定分类汇总的结果保存到何处
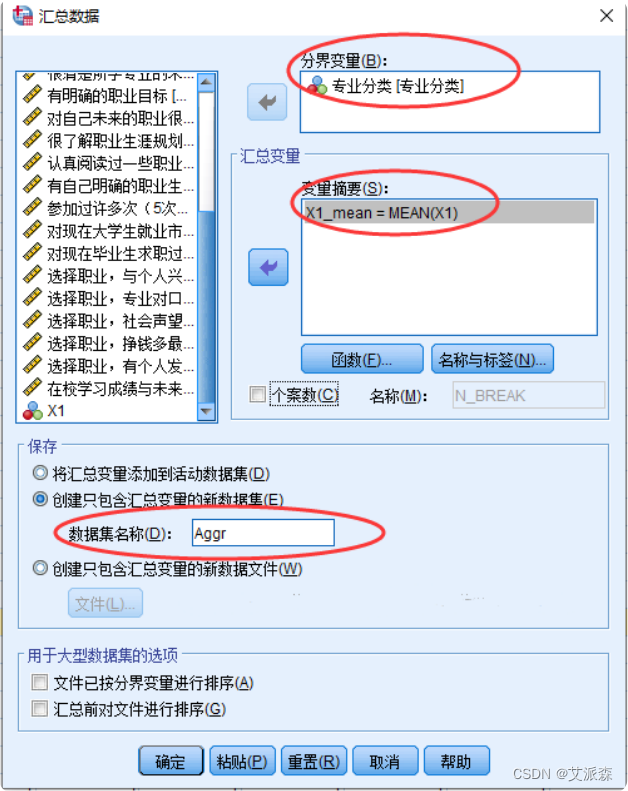
③点击【确定】即可得到分类汇总的结果
8.数据分组

数据分组介绍
有时候,过于细致的数据并不利于展现数据的总体分布特征, 因此,可以将数据进行“粗化”处理,即数据分组。
- 数据分组是对数值型数据进行整理和粗略把握数据分布的重要工具
- 数据分组能够概括和体现数据的分布特征
- 数据分组还能够实现数据的离散化处理
- 组距分组是应用最广泛的数据分组方法
组距分组
组距分组是将全部变量值依次划分为若干个区间,并将同一区间的变量值作为一组组距分组中的两个关键问题。

实际确定组距时,没有那么严格,可以根据计算结果取一个近似值。
【案例】 对大学生职业生涯规划数据,计算专业和职业认知得分,并以5为组距进行分组,以便把握认知得分的分布特征
①选择菜单【转换】---> 【重新编码为不同变量】
②选择分组变量、设置输出变量
③点击上一步的【旧值和新值】按钮定义分组区间,这里,应根据分析要求逐个定义各分组区间
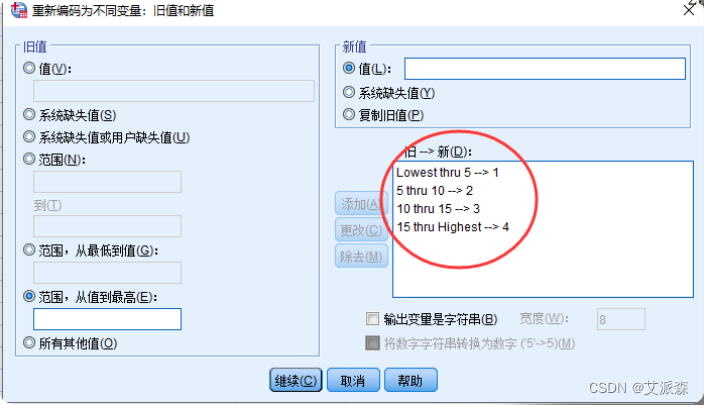
④依次点击上面两个对话框的【继续】、【确定】
至此,SPSS便自动进行组距分组,并在数据编辑器窗口中创建存放分组结果的名为X1_new的新变量。
9.数据转置

数据转置就是将数据编辑器窗口中数据的行列互换
【案例】—— 职工基本情况数据转置
①选择菜单【数据】-----> 【转置】
②在转置对话框中分别设置变量和名称变量
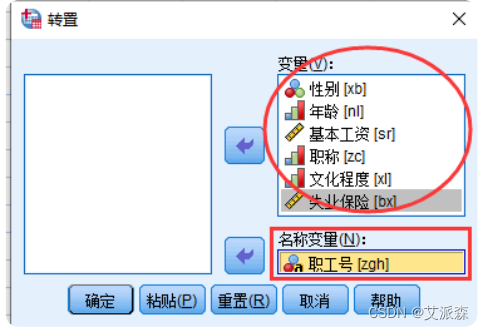
名称变量是一个取值唯一的标记变量,转置后数据各变量取 名为:K_标记变量值(如K_001,K_002等)
③SPSS自动完成数据转置,SPSS还会自动产生一个名为CASE_LBL 的新变量,用来存放原数据文件中的各变量名。最终效果形如:

10.加权处理

为调查观众对春晚是否满意,采用了在线打分的调查形式。假如 10%的观众打了5分,25%的观众打了4分,40%的观众打了3分, 25%的观众打了2分,这里就可以利用加权平均的方法来分析,其中 各百分比作为权数。
【案例】 为了分析血压与年龄的相关性(相关分析后面会讲到),需要根据人数对血压和年龄数据进行加权
①选择菜单【数据】----> 【个案加权】
②选择“个案加权依据”
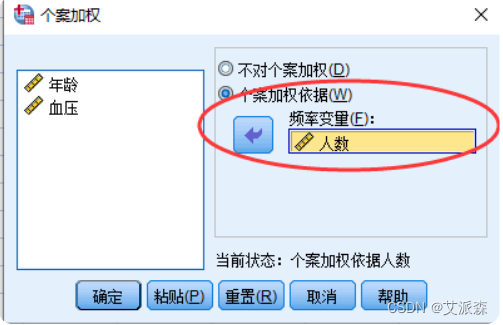
加权操作完毕后,数据编辑器窗口中的数据并没有变化,仅在状态栏中显示“权重开启”
注意:
- 一旦指定了加权变量,在以后的分析处理中加权会一直有效,直到取消加权为止
- 取消加权应在“个案加权”对话框中选择【不对个案加权】
11. 数据拆分

SPSS的数据拆分不仅是按指定变量对数据进行简单排序,更重 要的是根据指定变量对数据进行分组,它为分组统计分析提供了便利。
【案例】—— 通过“职称”拆分职工数据
①选择菜单【数据】----> 【拆分文件】
②选择拆分变量(本例是“职称”)到【分组依据(G)】框中;【比较 组(C)】表示将分组统计结果输出在同一张表格中,便于不同组 之间的比较
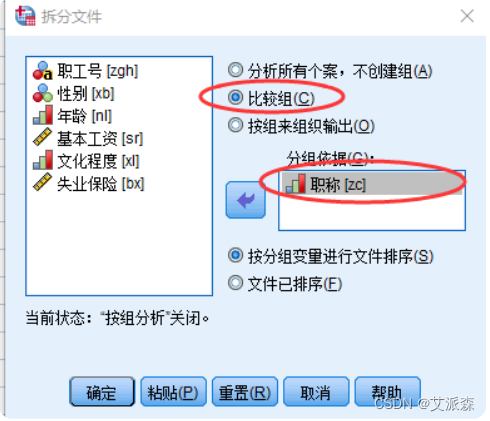
点击“确定”后,发现在数据编辑器窗口右下角的状态栏上显示“拆 分依据zc”提示信息
③选择菜单【分析】-->【描述统计】-->【描述】,选择要统计的变量
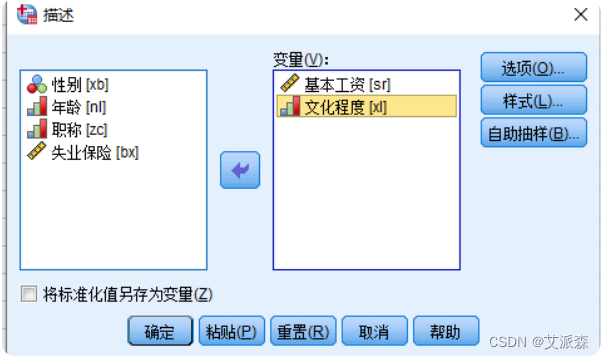
④在输出文件中查看每组(职称)的统计结果
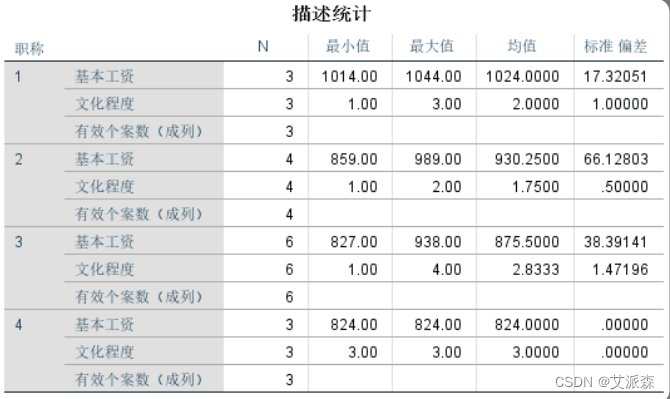
注意:
- 数据拆分后,将对后面的分析一直起作用,即无论进行哪种统计分析,都是按拆分变量的不同组分别进行分析计算
- 对数据可以进行多重拆分,在“拆分文件”对话框中选入多个变量到【分组依据(G)】框中即可
下一篇:使用地理定位来自定义网络钓鱼