设计模式之原型模式与建造者模式详解和应用
目录
- 1 原型模式
- 1.1 原型模式定义
- 1.2 原型模式的应用场景
- 1.3 原型模式的通用写法(浅拷贝)
- 1.4 使用序列化实现深度克隆
- 1.5 克隆破坏单例模式
- 1.6 原型模式在源码中的应用
- 1.7 原型模式的优缺点
- 1.8 总结
- 2 建造者模式
- 2.1 建造者模式定义
- 2.2 建造者模式的应用场景
- 2.3 建造者模式的基本写法
- 2.4 建造者模式的链式写法
- 2.5 建造者模式应用案例
- 2.6 建造者模式在源码中的体现
- 2.7 建造者模式的优缺点
- 2.8 建造者模式和工厂模式的区别
1 原型模式
1.1 原型模式定义
原型模式(PrototypePattern)是指原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象,属于创建型模式。
官方原文:Specify the kinds of objects to create using a prototypical instance,and create new objects by copying this prototype.
原型模式的核心在于拷贝原型对象。以系统中已存在的一个对象为原型,直接基于内存二进制流进行拷贝,无需再经历耗时的对象初始化过程(不调用构造函数),性能提升许多。当对象的构建过程比较耗时时,可以利用当前系统中已存在的对象作为原型,对其进行克隆(一般是基于二进制流的复制),躲避初始化过程,使得新对象的创建时间大大减少。下面,我们来看看原型模式类结构图:
从 UML 图中,我们可以看到,原型模式 主要包含三个角色:
客户(Client):客户类提出创建对象的请求。
抽象原型(Prototype):规定拷贝接口。
具体原型(Concrete Prototype):被拷贝的对象。
注:对不通过 new 关键字,而是通过对象拷贝来实现创建对象的模式就称作原型模式。
1.2 原型模式的应用场景
你一定遇到过大篇幅getter、setter赋值的场景。
代码非常工整,命名非常规范,注释也写的很全面,其实这就是原型模式的需求场景。但是,大家觉得这样的代码优雅吗?我认为,这样的代码属于纯体力劳动。那原型模式,能帮助我们解决这样的问题。
原型模式主要适用于以下场景:
1、类初始化消耗资源较多。
2、new产生的一个对象需要非常繁琐的过程(数据准备、访问权限等)
3、构造函数比较复杂。
4、循环体中生产大量对象时。
在 Spring 中,原型模式应用得非常广泛。例如 scope=“prototype”,在我们经常用的**JSON.parseObject()**也是一种原型模式。
1.3 原型模式的通用写法(浅拷贝)
一个标准的原型模式代码,应该是这样设计的。先创建原型IPrototype接口:
public interface IPrototype {T clone();
}
创建具体需要克隆的对象ConcretePrototype
public class ConcretePrototype implements IPrototype {private int age;private String name;public int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic ConcretePrototype clone() {ConcretePrototype concretePrototype = new ConcretePrototype();concretePrototype.setAge(this.age);concretePrototype.setName(this.name);return concretePrototype;}@Overridepublic String toString() {return "ConcretePrototype{" +"age=" + age +", name='" + name + '\'' +'}';}
}
测试代码:
public class Client {public static void main(String[] args) {//创建原型对象ConcretePrototype prototype = new ConcretePrototype();prototype.setAge(18);prototype.setName("Oldlu");System.out.println(prototype);//拷贝原型对象ConcretePrototype cloneType = prototype.clone();System.out.println(cloneType);}
}
运行结果:
ConcretePrototype{age=18, name='Oldlu'}
ConcretePrototype{age=18, name='Oldlu'}
这时候,有小伙伴就问了,原型模式就这么简单吗?对,就是这么简单。在这个简单的场景之下,看上去操作好像变复杂了。但如果有几百个属性需要复制,那我们就可以一劳永逸。但是,上面的复制过程是我们自己完成的,在实际编码中,我们一般不会浪费这样的体力劳动,JDK已经帮我们实现了一个现成的API,我们只需要实现Cloneable接口即可。来改造一下代码,修改ConcretePrototype类:
@Data
public class ConcretePrototype implements Cloneable {private int age;private String name;@Overridepublic ConcretePrototype clone() {try {return (ConcretePrototype)super.clone();} catch (CloneNotSupportedException e) {e.printStackTrace();return null;}}
}
重新运行,也会得到同样的结果。
有了JDK的支持再多的属性复制我们也能轻而易举地搞定了。下面我们再来做一个测试,给ConcretePrototype增加一个个人爱好的属性hobbies:
@Data
public class ConcretePrototype implements Cloneable {private int age;private String name;private List hobbies;@Overridepublic ConcretePrototype clone() {try {return (ConcretePrototype)super.clone();} catch (CloneNotSupportedException e) {e.printStackTrace();return null;}}
}
修改客户端测试代码:
public class Client {public static void main(String[] args) {//创建原型对象ConcretePrototype prototype = new ConcretePrototype();prototype.setAge(18);prototype.setName("Oldlu");List hobbies = new ArrayList();hobbies.add("书法");hobbies.add("美术");prototype.setHobbies(hobbies);//拷贝原型对象ConcretePrototype cloneType = prototype.clone();cloneType.getHobbies().add("技术控");System.out.println("原型对象:" + prototype);System.out.println("克隆对象:" + cloneType);System.out.println(prototype == cloneType);System.out.println("原型对象的爱好:" + prototype.getHobbies());System.out.println("克隆对象的爱好:" + cloneType.getHobbies());System.out.println(prototype.getHobbies() == cloneType.getHobbies());}
}
运行结果:
原型对象:ConcretePrototype(age=18, name=Oldlu, hobbies=[书法, 美术, 技术控])
克隆对象:ConcretePrototype(age=18, name=Oldlu, hobbies=[书法, 美术, 技术控])
false
原型对象的爱好:[书法, 美术, 技术控]
克隆对象的爱好:[书法, 美术, 技术控]
true
我们给,复制后的克隆对象新增一项爱好,发现原型对象也发生了变化,这显然不符合我们的预期。因为我们希望克隆出来的对象应该和原型对象是两个独立的对象,不应该再有联系了。从测试结果分析来看,应该是hobbies共用了一个内存地址,意味着复制的不是值,而是引用的地址。这样的话,如果我们修改任意一个对象中的属性值,prototype 和cloneType的hobbies值都会改变。这就是我们常说的浅克隆。只是完整复制了值类型数据,没有赋值引用对象。换言之,所有的引用对象仍然指向原来的对象,显然不是我们想要的结果。那如何解决这个问题呢?下面我们来看深度克隆继续改造。
扩展知识:String对象在内存中是不可变的(final类型),虽然克隆后,两个对象String的引用指向的是同一个内存地址,但是如果给克隆后的对象的String属性改变值,那么相当于是在内存中重新开辟了一块内存来存储这个改变的值,而此时的String属性对象就指向了该内存值,所以这个时候克隆前和克隆后对象的String属性是不一样的)。
String 每次赋值,相当于new String()。
1.4 使用序列化实现深度克隆
在上面的基础上我们继续改造,来看代码,增加一个deepClone()方法:
@Data
public class ConcretePrototype implements Cloneable,Serializable {private int age;private String name;private List hobbies;@Overridepublic ConcretePrototype clone() {try {return (ConcretePrototype)super.clone();} catch (CloneNotSupportedException e) {e.printStackTrace();return null;}}public ConcretePrototype deepClone(){try {ByteArrayOutputStream bos = new ByteArrayOutputStream();ObjectOutputStream oos = new ObjectOutputStream(bos);oos.writeObject(this);ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());ObjectInputStream ois = new ObjectInputStream(bis);return (ConcretePrototype)ois.readObject();}catch (Exception e){e.printStackTrace();return null;}}
}
来看客户端调用代码:
public class Client {public static void main(String[] args) {//创建原型对象ConcretePrototype prototype = new ConcretePrototype();prototype.setAge(18);prototype.setName("Oldlu");List hobbies = new ArrayList();hobbies.add("书法");hobbies.add("美术");prototype.setHobbies(hobbies);//拷贝原型对象ConcretePrototype cloneType = prototype.deepClone();cloneType.getHobbies().add("技术控");System.out.println("原型对象:" + prototype);System.out.println("克隆对象:" + cloneType);System.out.println(prototype == cloneType);System.out.println("原型对象的爱好:" + prototype.getHobbies());System.out.println("克隆对象的爱好:" + cloneType.getHobbies());System.out.println(prototype.getHobbies() == cloneType.getHobbies());}
}
运行程序,我们发现得到了我们期望的结果:
原型对象:ConcretePrototype(age=18, name=Oldlu, hobbies=[书法, 美术])
克隆对象:ConcretePrototype(age=18, name=Oldlu, hobbies=[书法, 美术, 技术控])
false
原型对象的爱好:[书法, 美术]
克隆对象的爱好:[书法, 美术, 技术控]
false
1.5 克隆破坏单例模式
如果我们克隆的目标的对象是单例对象,那意味着,深克隆就会破坏单例。实际上防止克隆破坏单例解决思路非常简单,禁止深克隆便可。要么你我们的单例类不实现 Cloneable 接口;要么我们重写clone()方法,在clone方法中返回单例对象即可,具体代码如下:
@Override
protected Object clone() throws CloneNotSupportedException {return INSTANCE;
}
1.6 原型模式在源码中的应用
先来JDK中Cloneable接口:
public interface Cloneable {
}
接口定义还是很简单的,我们找源码其实只需要找到看哪些接口实现了 Cloneable 即可。来看ArrayList类的实现。
Object方法
protected native Object clone() throws CloneNotSupportedException;
复制
ArrayList是实现的clone方法
public class ArrayList extends AbstractListimplements List, RandOldluAccess, Cloneable, java.io.Serializable
{public Object clone() {try {ArrayList v = (ArrayList) super.clone();v.elementData = Arrays.copyOf(elementData, size);v.modCount = 0;return v;} catch (CloneNotSupportedException e) {// this shouldn't happen, since we are Cloneablethrow new InternalError(e);}}
}
我们发现方法中只是将List中的元素循环遍历了一遍。这个时候我们再思考一下,是不是这种形式就是深克隆呢?其实用代码验证一下就知道了,继续修改 ConcretePrototype 类,增加一个deepCloneHobbies()方法:
@Data
public class ConcretePrototype implements Cloneable,Serializable {...public ConcretePrototype deepCloneHobbies(){try {ConcretePrototype result = (ConcretePrototype)super.clone();result.hobbies = (List)((ArrayList)result.hobbies).clone();return result;} catch (CloneNotSupportedException e) {e.printStackTrace();return null;}}...
}
修改客户端代码:
public class Client {public static void main(String[] args) {...//拷贝原型对象ConcretePrototype cloneType = prototype.deepCloneHobbies();...}
}
运行也能得到期望的结果。但是这样的代码,其实是硬编码,如果在对象中声明了各种集合类型,那每种情况都需要单独处理。因此,深克隆的写法,一般会直接用序列化来操作。
1.7 原型模式的优缺点
优点:
1、性能优良,Java自带的 原型模式 是基于内存二进制流的拷贝,比直接new一个对象性能上提升了许多。
2、可以使用深克隆方式保存对象的状态,使用原型模式将对象复制一份并将其状态保存起来,简化了创建对象的过程,以便在需要的时候使用(例如恢复到历史某一状态),可辅助实现撤销操作。
缺点:
1、需要为每一个类配置一个克隆方法。
2、克隆方法位于类的内部,当对已有类进行改造的时候,需要修改代码,违反了开闭原则。
3、在实现深克隆时需要编写较为复杂的代码,而且当对象之间存在多重嵌套引用时,为了实现深克隆,每一层对象对应的类都必须支持深克隆,实现起来会比较麻烦。因此,深拷贝、浅拷贝需要运用得当。
1.8 总结
克隆方式:1.序列化 反序列化 2.jsonobject 3浅克隆加赋值
浅克隆:继承Cloneable接口的都是浅克隆。
深克隆两种方式:序列化,转JSON。
2 建造者模式
2.1 建造者模式定义
建造者模式(Builder Pattern)是将一个复杂对象的构建过程与它的表示分离,使得同样的构建过程可以创建不同的表示,属于创建型模式。使用建造者模式对于用户而言只需指定需要建造的类型就可以获得对象,建造过程及细节不需要了解。
官方原文:Separate the construction of a cOldluplex object frOldlu its representation so that the same construction process can create different representations.
建造者模式适用于创建对象需要很多步骤,但是步骤的顺序不一定固定。如果一个对象有非常复杂的内部结构(很多属性),可以将复杂对象的创建和使用进行分离。先来看一下建造者模式的类图:
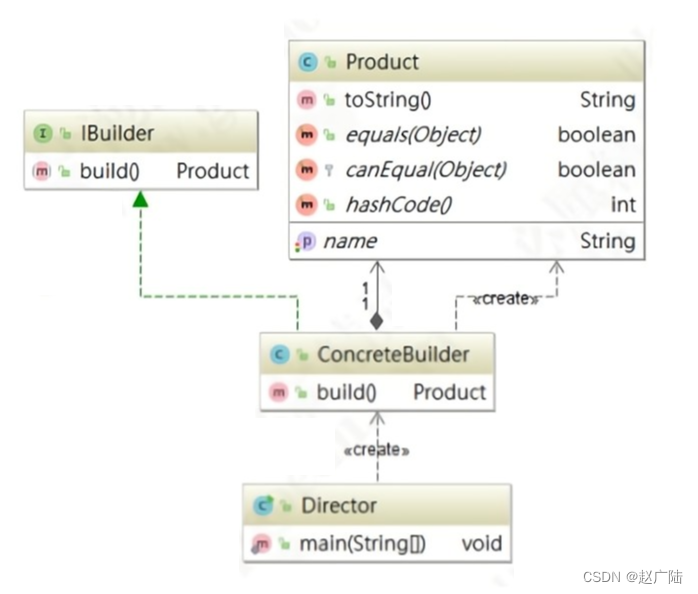
建造者模式的设计中主要有四个角色:
1、产品(Product):要创建的产品类对象
2、建造者抽象(Builder):建造者的抽象类,规范产品对象的各个组成部分的建造,一般由子类实现具体的建造过程。
3、建造者(ConcreteBuilder):具体的Builder类,根据不同的业务逻辑,具体化对象的各个组成部分的创建。
4、调用者(Director):调用具体的建造者,来创建对象的各个部分,在指导者中不涉及具体产品的信息,只负责保证对象各部分完整创建或按某种顺序创建。
2.2 建造者模式的应用场景
建造者模式适用于一个具有较多的零件的复杂产品的创建过程,由于需求的变化,组成这个复杂产品的各个零件经常猛烈变化,但是它们的组合方式却相对稳定。
- 相同的方法,不同的执行顺序,产生不同的结果时
- 多个部件或零件,都可以装配到一个对象中,但是产生的结果又不相同。
- 产品类非常复杂,或者产品类中的调用顺序不同产生不同的作用。
- 当初始化一个对象特别复杂,参数多,而且很多参数都具有默认值时。
建造者模式,只关注用户需要什么,将最少的关键字传过来,生成你想要的结果。
实际顺序是在build方法里面。那是顺序和条件都确定了。每个顺序和条件都分别存储下来了。判断有没有,有就添加到product后面。当然就是先判断条件再判断order顺序了
2.3 建造者模式的基本写法
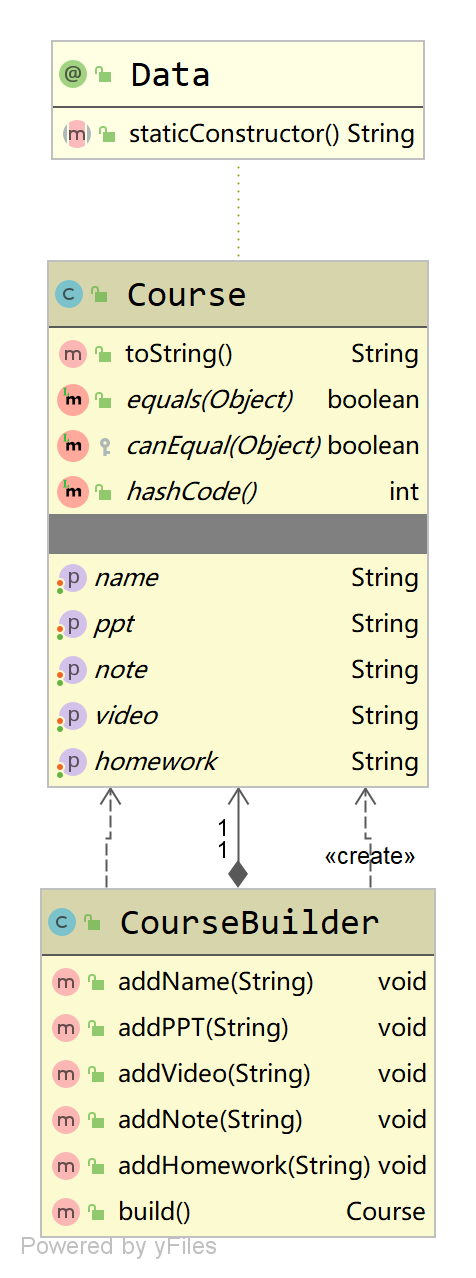
我们还是以课程为例,一个完整的课程需要由PPT课件、回放视频、课堂笔记、课后作业组成,但是这些内容的设置顺序可以随意调整,我们用建造者模式来代入理解一下。首先我们创建一个需要构造的产品类Course:
@Data
public class Course {private String name;private String ppt;private String video;private String note;private String hOldluework;
}
然后创建建造者类CourseBuilder,将复杂的构造过程封装起来,构造步骤由用户决定:
public class CourseBuilder{private Course course = new Course();public void addName(String name) {course.setName(name);}public void addPPT(String ppt) {course.setPpt(ppt);}public void addVideo(String video) {course.setVideo(video);}public void addNote(String note) {course.setNote(note);}public void addHOldluework(String hOldluework) {course.setHOldluework(hOldluework);}public Course build() {return course;}
}
编写测试类:
public class Test {public static void main(String[] args) {CourseBuilder builder = new CourseBuilder();builder.addName("设计模式");builder.addPPT("【PPT课件】");builder.addVideo("【回放视频】");builder.addNote("【课堂笔记】");builder.addHOldluework("【课后作业】");System.out.println(builder.build());}
}
运行结果:
Course(name=设计模式, ppt=【PPT课件】, video=【回放视频】, note=【课堂笔记】, hOldluework=【课后作业】)
来看一下类结构图:
2.4 建造者模式的链式写法
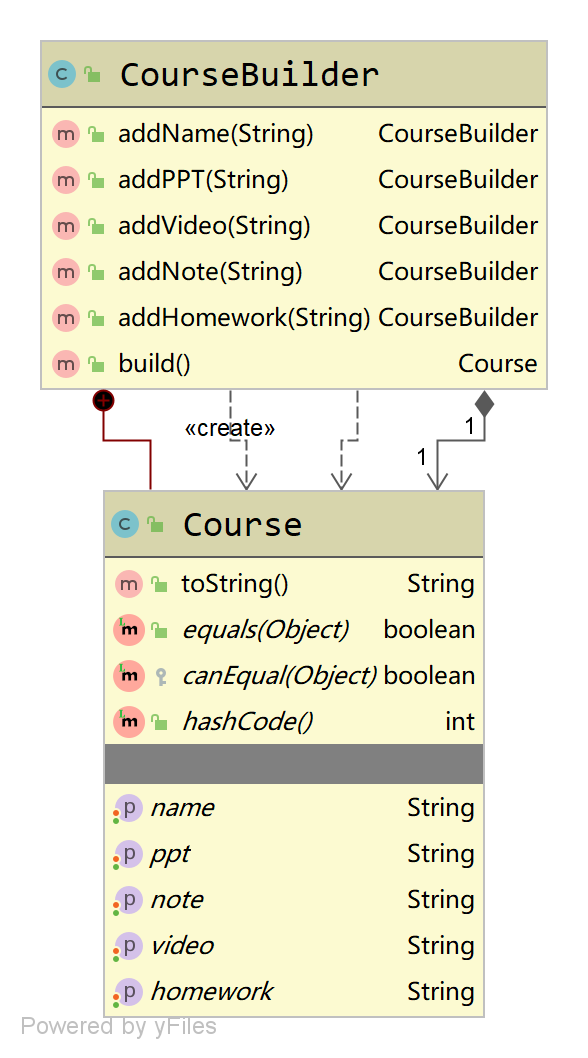
在平时的应用中,建造者模式通常是采用链式编程的方式构造对象,下面我们来一下演示代码,修改CourseBuilder类,将Course变为CourseBuilder的内部类。然后,将构造步骤添加进去,每完成一个步骤,都返回this:
public class CourseBuilder {private Course course = new Course();public CourseBuilder addName(String name) {course.setName(name);return this;}public CourseBuilder addPPT(String ppt) {course.setPpt(ppt);return this;}public CourseBuilder addVideo(String video) {course.setVideo(video);return this;}public CourseBuilder addNote(String note) {course.setNote(note);return this;}public CourseBuilder addHOldluework(String hOldluework) {course.setHOldluework(hOldluework);return this;}public Course build() {return this.course;}@Datapublic class Course {private String name;private String ppt;private String video;private String note;private String hOldluework;}
}
客户端使用:
public class Test {public static void main(String[] args) {CourseBuilder builder = new CourseBuilder().addName("设计模式").addPPT("【PPT课件】").addVideo("【回放视频】").addNote("【课堂笔记】").addHOldluework("【课后作业】");System.out.println(builder.build());}
}
这样写法是不是很眼熟,好像在哪见过呢?后面我们分析建造者模式在源码中的应用大家就会明白。接下来,我们再来看一下类图的变化:
2.5 建造者模式应用案例
下面我们再来看一个实战案例,这个案例参考了开源框架JPA的SQL构造模式。是否记得我们在构造SQL查询条件的时候,需要根据不同的条件来拼接SQL字符串。如果查询条件复杂的时候,我们SQL拼接的过程也会变得非常复杂,从而给我们的代码维护带来非常大的困难。因此,我们用建造者类QueryRuleSqlBuilder 将复杂的构造 SQL 过程进行封装,用 QueryRule 对象专门保存 SQL 查询时的条件,最后根据查询条件,自动生成SQL语句。来看代码,先创建QueryRule类:
/*** QueryRule,主要功能用于构造查询条件*/
public final class QueryRule implements Serializable
{... /*** 添加升序规则* @param propertyName* @return*/public QueryRule addAscOrder(String propertyName) {this.ruleList.add(new Rule(ASC_ORDER, propertyName));return this;}public QueryRule andEqual(String propertyName, Object value) {this.ruleList.add(new Rule(EQ, propertyName, new Object[] { value }).setAndOr(AND));return this;}public QueryRule andLike(String propertyName, Object value) {this.ruleList.add(new Rule(LIKE, propertyName, new Object[] { value }).setAndOr(AND));return this;}...
}
然后,创建QueryRuleSqlBuilder类:
/*** 根据QueryRule自动构建sql语句*/
public class QueryRuleSqlBuilder {... /*** 处理like* @param rule*/private void processLike(QueryRule.Rule rule) {if (ArrayUtils.isEmpty(rule.getValues())) {return;}Object obj = rule.getValues()[0];if (obj != null) {String value = obj.toString();if (!StringUtils.isEmpty(value)) {value = value.replace('*', '%');obj = value;}}add(rule.getAndOr(),rule.getPropertyName(),"like","%"+rule.getValues()[0]+"%");}/*** 处理 =* @param rule*/private void processEqual(QueryRule.Rule rule) {if (ArrayUtils.isEmpty(rule.getValues())) {return;}add(rule.getAndOr(),rule.getPropertyName(),"=",rule.getValues()[0]);}/*** 处理 order by* @param rule 查询规则*/private void processOrder(Rule rule) {switch (rule.getType()) {case QueryRule.ASC_ORDER:// propertyName非空if (!StringUtils.isEmpty(rule.getPropertyName())) {orders.add(Order.asc(rule.getPropertyName()));}break;case QueryRule.DESC_ORDER:// propertyName非空if (!StringUtils.isEmpty(rule.getPropertyName())) {orders.add(Order.desc(rule.getPropertyName()));}break;default:break;}}...
}
创建Order类:
/*** sql排序组件*/
public class Order {private boolean ascending; //升序还是降序private String propertyName; //哪个字段升序,哪个字段降序public String toString() {return propertyName + ' ' + (ascending ? "asc" : "desc");}/*** Constructor for Order.*/protected Order(String propertyName, boolean ascending) {this.propertyName = propertyName;this.ascending = ascending;}/*** Ascending order** @param propertyName* @return Order*/public static Order asc(String propertyName) {return new Order(propertyName, true);}/*** Descending order** @param propertyName* @return Order*/public static Order desc(String propertyName) {return new Order(propertyName, false);}
}
编写测试代码:
public class Test {public static void main(String[] args) {QueryRule queryRule = QueryRule.getInstance();queryRule.addAscOrder("age");queryRule.andEqual("addr","ShanDong");queryRule.andLike("name","Oldlu");QueryRuleSqlBuilder builder = new QueryRuleSqlBuilder(queryRule);System.out.println(builder.builder("t_member"));System.out.println("Params: " + Arrays.toString(builder.getValues()));}
}
这样一来,我们的客户端代码就非常清朗,来看运行结果:
select * frOldlu t_member where addr = ? and name like ? order by age asc
Params: [ShanDong, %Oldlu%]
2.6 建造者模式在源码中的体现
下面来看建造者模式在哪些源码中有应用呢?首先来看JDK的StringBuilder,它提供append()方法,给我们开放构造步骤,最后调用toString()方法就可以获得一个构造好的完整字符串,源码如下:
public final class StringBuilderextends AbstractStringBuilderimplements java.io.Serializable, CharSequence
{public StringBuilder append(StringBuffer sb) {super.append(sb);return this;}
}
在MyBatis中也有体现,比如CacheBuilder类。
同样在 MyBatis 中,比如 SqlSessionFactoryBuilder 通过调用 build()方法获得的是一个SqlSessionFactory 类。
当然,在 Spring中自然也少不了,比如 BeanDefinitionBuilder 通过调用getBeanDefinition()方法获得一个BeanDefinition对象。
2.7 建造者模式的优缺点
建造者模式的优点:
1、封装性好,创建和使用分离;
2、扩展性好,建造类之间独立、一定程度上解耦。
建造者模式的缺点:
1、产生多余的Builder对象;
2、产品内部发生变化,建造者都要修改,成本较大。
2.8 建造者模式和工厂模式的区别
建造者模式和工厂模式的区别
1、建造者模式更加注重方法的调用顺序,工厂模式注重于创建对象。
2、创建对象的力度不同,建造者模式创建复杂的对象,由各种复杂的部件组成,工厂模式创建出来的都一样。
3、关注重点不一样,工厂模式模式只需要把对象创建出来就可以了,而建造者模式中不仅要创建出这个对象,还要知道这个对象由哪些部件组成。
4、建造者模式根据建造过程中的顺序不一样,最终的对象部件组成也不一样。
可以理解为工厂创建过程是静态的,构建者模式创建过程经过外放而变成动态的。