19- CNN进行Fashion-MNIST分类 (tensorflow系列) (项目十九)
创始人
2024-05-28 13:48:09
0次
项目要点
- Fashion-MNIST总共有十个类别的图像。
- 代码运行位置 CPU: cpu=tf.config.set_visible_devices(tf.config.list_physical_devices("CPU"))
- fashion_mnist = keras.datasets.fashion_mnist # fashion_mnist 数据导入
- 训练数据和测试数据拆分: x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
- x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(55000, -1)).reshape( -1, 28, 28, 1) 标准化处理数据 # scaler = StandardScaler() 标准化处理只能处理一维数据
- 创建模型: model = keras.models.Sequential()
- model.add(keras.layers.Conv2D(filters = 64, kernel_size = 3, padding = 'same', activation = 'relu', input_shape = (28, 28, 1))) 添加输入层
- 池化, 常用最大值池化: model.add(keras.layers.MaxPool2D())
- model.add(keras.layers.Conv2D(filters = 32,kernel_size = 3, padding = 'same',activation = 'relu')) # 添加卷积层
- 维度变化, 卷积完后为四维, 自动变二维: model.add(keras.layers.Flatten())
- model.add(keras.layers.Dense(512, activation = 'relu', input_shape = (784))) # 重新调整形状
- 添加卷积层: model.add(keras.layers.Dense(256, activation = 'relu'))
- 添加输出层: model.add(keras.layers.Dense(10, activation = 'softmax'))
- 查看模型: model.summary()
- 模型配置:
model.compile(loss = 'sparse_categorical_crossentropy',optimizer = 'adam',metrics = ['accuracy'])- histroy = model.fit(x_train_scaled, y_train, epochs = 10, validation_data= (x_valid_scaled, y_valid)) 模型训练
- 模型评估: model.evaluate(x_test_scaled, y_test)
- 画图大小设置: pd.DateFrame(history.history).plot(figsize = (8, 5))
- 网格线显示: plt.grid(True)
- y轴设置: plt.gca().set_ylim(0, 1) # plt.gca() 坐标轴设置
- plt.show() 显示图像
一 Fashion-MNIST分类
Fashion-MNIST总共有十个类别的图像。每一个类别由训练数据集6000张图像和测试数据集1000张图像。所以训练集和测试集分别包含60000张和10000张。测试训练集用于评估模型的性能。
每一个输入图像的高度和宽度均为28像素。数据集由灰度图像组成。Fashion-MNIST,中包含十个类别,分别是t-shirt,trouser,pillover,dress,coat,sandal,shirt,sneaker,bag,ankle boot。
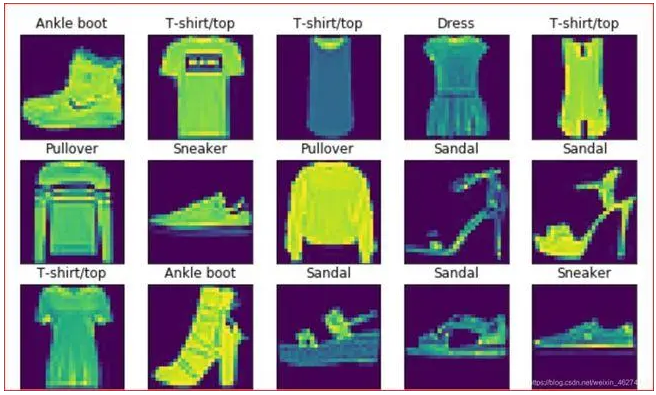
1.1 导包
import numpy as np
from tensorflow import keras
import tensorflow as tf
import pandas as pd
import os
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScalercpu=tf.config.list_physical_devices("CPU")
tf.config.set_visible_devices(cpu)
print(tf.config.list_logical_devices())1.2 数据导入
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]1.3 标准化
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(55000, -1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(5000, -1)).reshape(-1, 28, 28, 1)
x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(10000, -1)).reshape(-1, 28, 28, 1)1.4 创建模型
model = keras.models.Sequential()
# filters 过滤器
# 卷积
model.add(keras.layers.Conv2D(filters = 64,kernel_size = 3,padding = 'same',activation = 'relu',# batch_size, height, width, channels(通道数)input_shape = (28, 28, 1))) # (28, 28, 32)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (14, 14, 32)# 卷积
model.add(keras.layers.Conv2D(filters = 32,kernel_size = 3,padding = 'same',activation = 'relu')) # (14, 14, 64)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (7, 7, 64)# 卷积
model.add(keras.layers.Conv2D(filters = 32,kernel_size = 3,padding = 'same',activation = 'relu')) # (7, 7, 128)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (4, 4, 128)
# 维度变化, 卷积完后为四维, 自动变二维
model.add(keras.layers.Flatten())model.add(keras.layers.Dense(512, activation = 'relu', input_shape = (784, )))
model.add(keras.layers.Dense(256, activation = 'relu'))
model.add(keras.layers.Dense(10, activation = 'softmax'))model.compile(loss = 'sparse_categorical_crossentropy',optimizer = 'adam',metrics = ['accuracy'])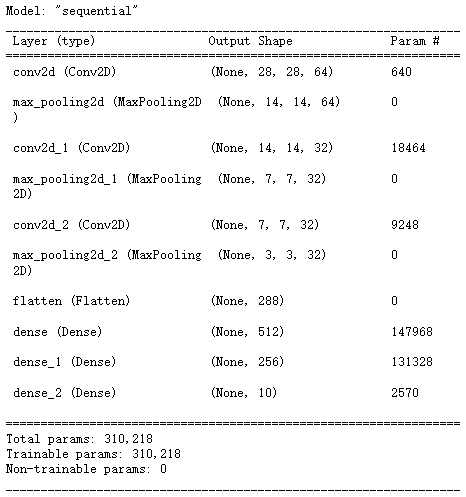
1.5 训练模型
histroy = model.fit(x_train_scaled, y_train, epochs = 10, validation_data= (x_valid_scaled, y_valid))
1.6 模型评估
model.evaluate(x_test_scaled, y_test) # [0.32453039288520813, 0.906000018119812]二 增加卷积
2.1 创建模型
model = keras.models.Sequential()
# filters 过滤器
# 卷积
model.add(keras.layers.Conv2D(filters = 64,kernel_size = 3,padding = 'same',activation = 'relu',# batch_size, height, width, channels(通道数)input_shape = (28, 28, 1))) # (28, 28, 32)
model.add(keras.layers.Conv2D(filters = 32,kernel_size = 3,padding = 'same',activation = 'relu')) # (14, 14, 64)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (14, 14, 32)# 卷积
model.add(keras.layers.Conv2D(filters = 64,kernel_size = 3,padding = 'same',activation = 'relu')) # (14, 14, 64)
model.add(keras.layers.Conv2D(filters = 64,kernel_size = 3,padding = 'same',activation = 'relu')) # (14, 14, 64)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (7, 7, 64)# 卷积
model.add(keras.layers.Conv2D(filters = 128,kernel_size = 3,padding = 'same',activation = 'relu')) # (7, 7, 128)
model.add(keras.layers.Conv2D(filters = 128,kernel_size = 3,padding = 'same',activation = 'relu')) # (14, 14, 64)
# 池化, 常用最大值池化
model.add(keras.layers.MaxPool2D()) # (4, 4, 128)
# 维度变化, 卷积完后为四维, 自动变二维
model.add(keras.layers.Flatten())model.add(keras.layers.Dense(512, activation = 'relu', input_shape = (784, )))
model.add(keras.layers.Dense(256, activation = 'relu'))
model.add(keras.layers.Dense(10, activation = 'softmax'))model.compile(loss = 'sparse_categorical_crossentropy',optimizer = 'adam',metrics = ['accuracy'])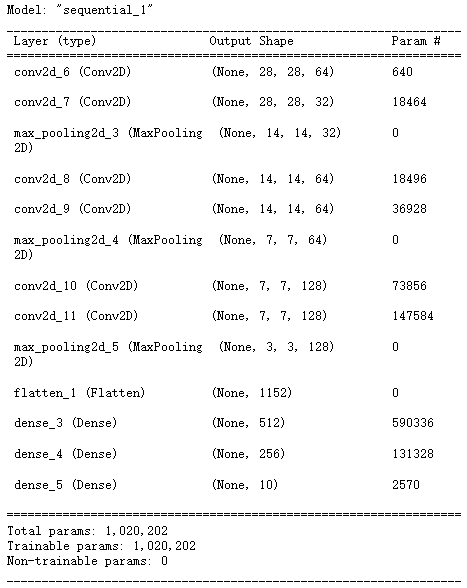
2.2 训练模型
histroy = model.fit(x_train_scaled, y_train, epochs = 10, validation_data= (x_valid_scaled, y_valid))
2.3 评估模型
model.evaluate(x_test_scaled, y_test) # [0.3228122293949127, 0.9052000045776367]相关内容
热门资讯
保存时出现了1个错误,导致这篇...
当保存文章时出现错误时,可以通过以下步骤解决问题:查看错误信息:查看错误提示信息可以帮助我们了解具体...
汇川伺服电机位置控制模式参数配...
1. 基本控制参数设置 1)设置位置控制模式 2)绝对值位置线性模...
不能访问光猫的的管理页面
光猫是现代家庭宽带网络的重要组成部分,它可以提供高速稳定的网络连接。但是,有时候我们会遇到不能访问光...
不一致的条件格式
要解决不一致的条件格式问题,可以按照以下步骤进行:确定条件格式的规则:首先,需要明确条件格式的规则是...
本地主机上的图像未显示
问题描述:在本地主机上显示图像时,图像未能正常显示。解决方法:以下是一些可能的解决方法,具体取决于问...
表格列调整大小出现问题
问题描述:表格列调整大小出现问题,无法正常调整列宽。解决方法:检查表格的布局方式是否正确。确保表格使...
表格中数据未显示
当表格中的数据未显示时,可能是由于以下几个原因导致的:HTML代码问题:检查表格的HTML代码是否正...
Android|无法访问或保存...
这个问题可能是由于权限设置不正确导致的。您需要在应用程序清单文件中添加以下代码来请求适当的权限:此外...
银河麒麟V10SP1高级服务器...
银河麒麟高级服务器操作系统简介: 银河麒麟高级服务器操作系统V10是针对企业级关键业务...
【NI Multisim 14...
目录 序言 一、工具栏 🍊1.“标准”工具栏 🍊 2.视图工具...