如何提高爬虫工作效率
单进程单线程爬取目标网站太过缓慢,这个只是针对新手来说非常友好,只适合爬取小规模项目,如果遇到大型项目就不得不考虑多线程、线程池、进程池以及协程等问题。那么我们该如何提升工作效率降低成本?
学习之前首先要对线程,进程,协程做一个简单的区分吧:
进程是资源单位,每一个进程至少要有一个线程,每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。
线程是执行单位,启动每一个程序默认都会有一个主线程。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
协程是一种用户态的轻量级线程, 协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
了解了进程、线程、协程之间的区别之后,我们就可以思考如何用这些东西来提高爬虫的效率呢?
提高爬虫效率的方法
多线程
要体现多线程的特点就必须得拿单线程来做一个比较,这样才能凸显不同~
单线程运行举例:
def func():for i in range(5):print("func", i)if __name__ == '__main__':func()for i in range(5):print("main", i)
运行结果如下:
# 单线程演示案例result:
func 0
func 1
func 2
func 3
func 4
main 0
main 1
main 2
main 3
main 4
可以注意到在单线程的情况下,程序是先打印fun 0 - 4, 再打印main 0 - 4。
下面再举一个多线程的例子:
需要实例化一个Thread类 Thread(target=func()) target接收的就是任务(/函数),通过.start()方法就可以启动多线程了。
代码提供两种方式:
# 多线程(两种方法)
# 方法一:from threading import Threaddef func():for i in range(1000):print("func ", i)if __name__ == '__main__':t = Thread(target=func()) # 创建线程并给线程安排任务t.start() # 多线程状态为可以开始工作状态,具体的执行时间由CPU决定 for i in range(1000):print("main ", i)
# two
class MyThread(Thread):def run(self): # 固定的 -> 当线程被执行的时候,被执行的就是run()for i in range(1000):print("子线程 ", i)if __name__ == '__main__':t = MyThread()# t.run() #方法调用 --》单线程t.start() #开启线程for i in range(1000):print("主线程 ", i)
运行结果

子线程和主线程有时候会同时执行,这就是多线程吧。
线程创建之后只是代表处于能够工作的状态,并不代表立即执行,具体执行的时间需要看CPU。
感觉线程执行的顺序就是杂乱无章的。
接下来分享一下多进程:
多进程
进程的使用:Process(target=func())
先举一个例子来感受一下多进程的执行顺序:
from multiprocessing import Processdef func():for i in range(1000):print("子进程 ", i)if __name__ == '__main__':p = Process(target=func())p.start()for i in range(1000):print("主进程 ", i)
运行结果:

从结果中可以发出,所有的子进程按照顺序执行之后。就开始打印主进程0-999。进程打印的有序也表明线程是最小的执行单位。
开启多线程打印的时候,出现的数字并不是有序的。
线程池&进程池
在python中一般使用以下方法创建线程池/进程池:
with ThreadPoolExecutor(50) as t:t.submit(fn, name=f"线程{i}")
具体代码:
# 线程池:一次性开辟一些线程,我们用户直接给线程池提交任务,线程任务的调度交给线程池来完成
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutordef fn(name):for i in range(1000):print(name,i)if __name__ == '__main__':# 创建线程池with ThreadPoolExecutor(50) as t:for i in range(100):t.submit(fn, name=f"线程{i}")# 等待线程池中的任务全部执行完毕,才继续执行(守护)print(123)
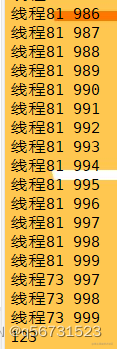
进程池的创建方法类似。
协程
协程:当程序遇见IO操作的时候,可以选择性的切换到其他任务上。
在微观上是一个任务一个任务的进行切换,切换条件一般就是IO操作。
在宏观上,我们能看到的其实就是多个任务一起在执行。
多任务异步操作(就像你自己一边洗脚一边看剧一样~,时间管理带师(bushi)。
线程阻塞的一些案例:
例子1:
time.sleep(30) # 让当前线程处于阻塞状态,CPU是不为我工作的
# input() 程序也是处于阻塞状态
# requests.get(xxxxxx) 在网络请求返回数据之前,程序也是处于阻塞状态
# 一般情况下,当程序处于IO操作的时候,线程都会处于阻塞状态
# for example: 边洗脚边按摩
import asyncio
import timeasync def func():print("hahha")if __name__ == "__main__":g = func() # 此时的函数是异步协程函数,此时函数执行得到的是一个协程对象asyncio.run(g) # 协程程序运行需要asyncio模块的支持
输出结果:
root@VM-12-2-ubuntu:~/WorkSpace# python test.py
hahha
例子2:
async def func1():print("hello,my name id hanmeimei")# time.sleep(3) # 当程序出现了同步操作的时候,异步就中断了await asyncio.sleep(3) # 异步操作的代码print("hello,my name id hanmeimei")async def func2():print("hello,my name id wahahha")# time.sleep(2)await asyncio.sleep(2) # 异步操作的代码print("hello,my name id wahahha")async def func3():print("hello,my name id hhhhhhhc")# time.sleep(4)await asyncio.sleep(4) # 异步操作的代码print("hello,my name id hhhhhhhc")if __name__ == "__main__":f1 = func1()f2 = func2()f3 = func3()task = [f1, f2, f3]t1 = time.time()asyncio.run(asyncio.wait(task))t2 = time.time()print(t2 - t1)
运行结果:
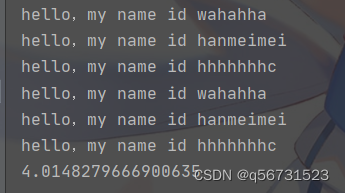
注意到执行await asyncio.sleep(4)后,主程序就会调用其他函数了。成功实现了异步操作。(边洗脚边按摩bushi )
下面的代码看起来更为规范~
async def func1():print("hello,my name id hanmeimei")await asyncio.sleep(3)print("hello,my name id hanmeimei")async def func2():print("hello,my name id wahahha")await asyncio.sleep(2)print("hello,my name id wahahha")async def func3():print("hello,my name id hhhhhhhc")await asyncio.sleep(4)print("hello,my name id hhhhhhhc")async def main():# 第一种写法# f1 = func1()# await f1 # 一般await挂起操作放在协程对象前面# 第二种写法(推荐)tasks = [func1(), # py3.8以后加上asyncio.create_task()func2(),func3()]await asyncio.wait(tasks)if __name__ == "__main__":t1 = time.time()asyncio.run(main())t2 = time.time()print(t2 - t1)
再举一个模拟下载的例子吧,更加形象啦:
async def download(url):print("准备开始下载")await asyncio.sleep(2) # 网络请求print("下载完成")async def main():urls = ["http://www.baidu.com","http://www.bilibili.com","http://www.163.com"]tasks = []for url in urls:d = download(url)tasks.append(d)await asyncio.wait(tasks)if __name__ == '__main__':asyncio.run(main())
# requests.get() 同步的代码 => 异步操作aiohttpimport asyncio
import aiohttpurls = ["http://kr.shanghai-jiuxin.com/file/2020/1031/191468637cab2f0206f7d1d9b175ac81.jpg","http://i1.shaodiyejin.com/uploads/tu/201704/9999/fd3ad7b47d.jpg","http://kr.shanghai-jiuxin.com/file/2021/1022/ef72bc5f337ca82f9d36eca2372683b3.jpg"
]async def aiodownload(url):name = url.rsplit("/", 1)[1] # 从右边切,切一次,得到[1]位置的内容 fd3ad7b47d.jpgasync with aiohttp.ClientSession() as session: # requestsasync with session.get(url) as resp: # resp = requests.get()# 请求回来之后,写入文件# 模块 aiofileswith open(name, mode="wb") as f: # 创建文件f.write(await resp.content.read()) # 读取内容是异步的,需要将await挂起, resp.text()print(name, "okk")# resp.content.read() ==> resp.text()# s = aiphttp.ClientSession <==> requests# requests.get() .post()# s.get() .post()# 发送请求# 保存图片内容平# 保存为文件async def main():tasks = []for url in urls:tasks.append(aiodownload(url))await asyncio.wait(tasks)if __name__ == '__main__':asyncio.run(main())
上一篇:中国没有ChatGPT
下一篇:JavaScript的学习