每天学一点之关联查询、select七大子句和子查询
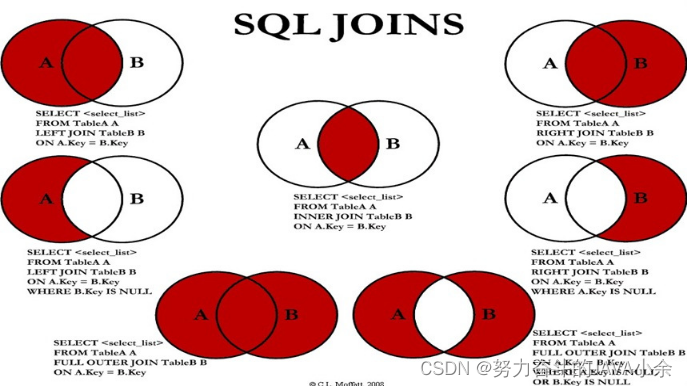
关联查询
关联查询的七种结果
(1)内连接
(2)外连接:左外连接、右外连接、全外连接(mysql使用union代替全外连接)
笛卡尔积现象:当两张表进行连接查询的时候,没有任何条件进行限制,最终的查询结果条数是两张表记录条数的乘积。
- 怎么避免笛卡尔积现象?当然是加条件进行过滤。
- 思考:避免了笛卡尔积现象,会减少记录的匹配次数吗?
不会,次数还是两张表记录条数的乘积,只不过显示的是有效记录。
关于表的别名:
select e.ename,d.dname from emp e,dept d;
表的别名有什么好处?
- 第一:执行效率高。
- 第二:可读性好
内连接:实现A∩B
假设A和B表进行连接,使用内连接的话,凡是A表和B表能够匹配上的记录查询出来,这就是内连接。
AB两张表没有主副之分,两张表是平等的。
格式:
select 字段列表
from A表 inner join B表
on 关联条件
where 等其他子句;或select 字段列表
from A表 , B表
where 关联条件 and 等其他子句;
案例分析:
#查询有部门的员工和有员工的部门
#不使用内连接的写法
select * from t_employee emp,t_department dept where emp.did=dept.did;#使用内连接,内连接和表的顺序无关,通过内连接查询的数据必须满足关联条件
select * from t_employee emp inner join t_department dept on emp.did=dept.did;
SELECT * FROM t_department dept INNER JOIN t_employee emp ON emp.did = dept.did;#查询薪资高于20000的男员工的姓名和他所在的部门的名称
SELECT ename "员工的姓名",dname "部门名称"
FROM t_employee INNER JOIN t_department
ON t_employee.did = t_department.did
WHERE salary>20000 AND gender = '男'左外连接:实现A 和 A - A∩B
外连接:
假设A和B表进行连接,使用外连接的话,AB两张表中有一张表是主表,一张表是副表,主要查询主表中的数据,捎带着查询副表,当副表中的数据没有和主表中的数据匹配上,副表自动模拟出NULL与之匹配。
外连接最重要的特点是:主表的数据无条件的全部查询出来。
格式:
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
案例分析:
#A的情况:
#查询所有员工的姓名和所在的部门 会以左边的表为主表,查询出所有的数据,哪怕不符合关联条件可以有为null的数据. 哪怕该员工没有部门
select ename,dname from t_employee emp left join t_department dept on emp.did=dept.did;#A-A∩B的情况:
#查询所有没有部门的员工
select ename,dname from t_employee emp left join t_department dept
on emp.did=dept.did where emp.did is null;
右外连接:实现B 和 B-A∩B
格式:
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
案例分析:
#查询所有部门,以及所有部门下的员工信息 会以右边的表为主表,查询出所有的数据,哪怕不符合关联条件. 哪怕该部门没有员工
select * from t_employee emp right join t_department dept on emp.did=dept.did;#查询没有员工的部门
select * from t_employee emp right join t_department dept on emp.did=dept.did where emp.did is null;
用union代替全外连接:实现A∪B 或 A∪(B-A∩B) 或B∪(A-A∩B) 和 A∪B - A∩B 或 (A - A∩B) ∪ (B - A∩B)
格式:
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句unionselect 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句
案例分析:
#查询所有的员工和部门
select * from t_employee emp left join t_department dept on emp.did=dept.did
union
select * from t_employee emp right join t_department dept on emp.did=dept.did;或
select * from t_employee emp left join t_department dept on emp.did=dept.did
union
select * from t_employee emp right join t_department dept on emp.did=dept.did where emp.did is null;#查询那些没有部门的员工和所有没有员工的部门
#没有部门的员工
SELECT *
FROM t_employee LEFT JOIN t_department
ON t_employee.did = t_department.did
WHERE t_employee.did IS NULLUNION #所有没有员工的部门
SELECT *
FROM t_employee RIGHT JOIN t_department
ON t_employee.did = t_department.did
WHERE t_employee.did IS NULL
特殊的关联查询:自连接
两个关联查询的表是同一张表,通过取别名的方式来虚拟成两张表
格式:
select 字段列表
from 表名 别名1 inner/left/right join 表名 别名2
on 别名1.关联字段 = 别名2.关联字段
where 其他条件
案例分析:
#查询员工的编号,姓名,薪资和他领导的编号,姓名,薪资
#这些数据全部在员工表中
#把t_employee表,即当做员工表,又当做领导表
#领导表是虚拟的概念,我们可以通过取别名的方式虚拟
SELECT emp.eid "员工的编号",emp.ename "员工的姓名" ,emp.salary "员工的薪资",mgr.eid "领导的编号" ,mgr.ename "领导的姓名",mgr.salary "领导的薪资"
FROM t_employee emp INNER JOIN t_employee mgr
#t_employee emp:如果用emp.,表示的是员工表的
#t_employee mgr:如果用mgr.,表示的是领导表的
ON emp.mid = mgr.eid#表的别名不要加"",给列取别名,可以用"",列的别名不使用""也可以,但是要避免包含空格等特殊符号。select 语句的7大子句
7大子句顺序
(1)from:从哪些表中筛选
(2)on:关联多表查询时,去除笛卡尔积
(3)where:从表中筛选的条件
(4)group by:分组依据
(5)having:在统计结果中再次筛选
(6)order by:排序
(7)limit:分页
必须按照(1)-(7)的顺序编写子句。注意:on后主要跟关联条件,where后跟字段作为条件,having后跟分组函数作为条件
案例分析:
#查询每个部门的男生的人数,并且显示人数超过5人的,按照人数降序排列,
#每页只能显示10条,我要第2页
SELECT did,COUNT(*) "人数"
FROM t_employee
WHERE gender = '男'
GROUP BY did
HAVING COUNT(*)>5
ORDER BY 人数 DESC
LIMIT 10,10
#测试on
SELECT * FROM t_employee ON eid > 10; -- X
SELECT * FROM t_employee emp LEFT JOIN t_department dept ON emp.eid = 10; -- √
#测试where
SELECT * FROM t_employee WHERE eid > 10; -- √
SELECT AVG(salary) FROM t_employee WHERE AVG(salary)>15000 GROUP BY did; -- X
group by与分组函数
(group by单独使用没有任何意义,必须和分组函数结合使用)
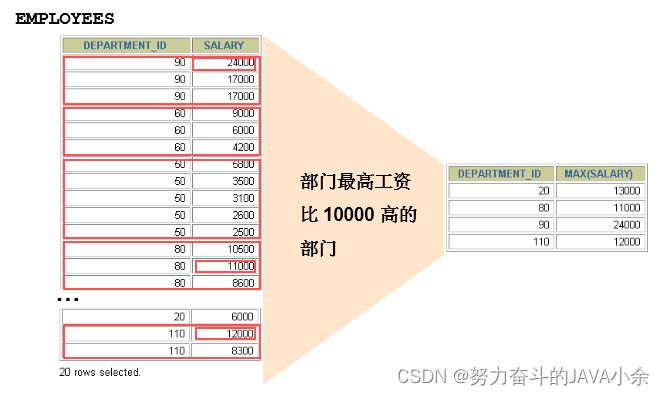
- 可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression];
明确:WHERE一定放在FROM后面GROUP BY 前面
- 在SELECT列表中所有未包含在分组函数中的列都应该包含在 GROUP BY子句中
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id ;
- 包含在 GROUP BY 子句中的列不必包含在SELECT 列表中
SELECT AVG(salary)
FROM employees
GROUP BY department_id ;
- 使用多个列分组
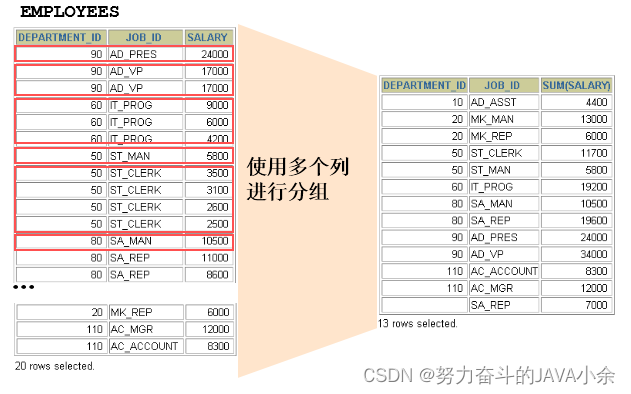
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id ;
having与分组函数
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;
having与where的区别?
(1)where是从表中筛选的条件,而having是统计结果中再次筛选因此后面的条件必须是select后面出现的字段或分组函数
(2)where后面一定不能加“分组/聚合函数”,而having后面可以跟分组函数
#测试having
SELECT * FROM t_employee HAVING eid > 10; -- √
SELECT AVG(salary) FROM t_employee WHERE did IS NOT NULL GROUP BY did HAVING AVG(salary) > 15000;
SELECT did,AVG(salary) FROM t_employee WHERE did IS NOT NULL GROUP BY did HAVING eid > 10; -- X
SELECT did,AVG(salary) FROM t_employee WHERE did IS NOT NULL GROUP BY did HAVING did > 1; -- √
SELECT did,AVG(salary) FROM t_employee WHERE did IS NOT NULL AND did > 1 GROUP BY did; -- √#统计部门平均工资高于8000的部门和平均工资
SELECT department_id, AVG(salary)
FROM employees
WHERE AVG(salary) > 8000 #错误
GROUP BY department_id;

#统计部门平均工资高于8000的部门和平均工资
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id
HAVING AVG(salary)>8000 ;
order by
order by:
-
降序:desc
-
升序:用么默认,要么加asc
limit
limit index,pageSize
index:当前页的起始索引
pageSize:每页显示的条数
pageNum:当前页的页码
index = (pageNum-1)*pageSize
pageNum=1,pageSize=4,limit 0,4
pageNum=4,pageSize=4,limit 12,4
pageNum=8,pageSize=4,limit 28,4
pageNum=4,pageSize=6,limit 18,6
limit 4-->limit 0,4
子查询
嵌套在另一个查询中的查询,根据位置不同,分为:where型,from型,exists型。注意:不管子查询在哪里,子查询必须使用()括起来。
1、where型
where型子查询:将某个SQL语句查询的数据作为SQL的条件查询
- 1、where型子查询中,查询的字段只能有一列,否则:Operand should contain 1 column(s)
- 2、where型子查询中,子查询的SQL若返回了多行数据,则不能使用"=",但是可以使用in
- 3、where型子查询中,子查询的SQL若返回了多行数据,则不能使用">“、”<“、”>=“、”<=",但是可以使用all或any
all(子查询结果):大于最大值
any(子查询结果):大于最小值
< all(子查询结果):小于最小值
< any(子查询结果):小于最大值
#查询薪资最高的员工信息
SELECT eid,ename,MAX(salary) FROM t_employee
WHERE salary = (SELECT MAX(salary) FROM t_employee);#查询每个部门中最高薪资的员工信息
select *from t_employee where salary in(select max(salary) from t_employee where did is not null group by did);
#不加where is not null 会把did为空的分为一个新的组,即不需要显示没有部门的员工信息#查询大于每个部门的平均薪资的员工信息
SELECT * FROM t_employee
WHERE salary > ALL(SELECT AVG(salary) FROM t_employee WHERE did IS NOT NULL GROUP BY did);#查询至少大于一个部门的平均薪资的员工信息
SELECT * FROM t_employee
WHERE salary > ANY(SELECT AVG(salary) FROM t_employee WHERE did IS NOT NULL GROUP BY did);
2、from型
-
子查询的结果是多行多列的结果,类似于一张表格。
-
必须给子查询取别名,即临时表名,表的别名不要加“”和空格。
#查询每个部门的信息以及每个部门的最高薪资,最低薪资,平均薪资
SELECT dept.*,temp.maxSalary,temp.minSalary,temp.avgSalary
FROM t_department dept
LEFT JOIN
(SELECT did,MAX(salary) maxSalary,MIN(salary) minSalary,AVG(salary) avgSalary FROM t_employee GROUP BY did) temp
ON dept.did = temp.did;#查询每个部门的编号,名称,平均工资
select 部门编号, 部门名称, 平均工资
from 部门表 inner join (select 部门编号,avg(薪资) from 员工表 group by 部门编号) temp
on 部门表.部门编号 = temp.部门编号
3、exists型
查询那些有员工的部门
select 部门编号, 部门名称 from 部门表
where exists (select * from 员工表 where 部门表.部门编号 = 员工表.部门编号);
下一篇:go基础语法之关键字