面试知识题库
这里写目录标题
- 1.并发编程(高并发、多线程)
- 1.1 并发编程的三个必要因素
- 1.2 Java程序中怎么保证多线程的运行安全?
- 1.3 volatile的作用
- 1.3.1 保证共享变量的可见性
- 1.3.2 禁止指令重排
- 1.4 死锁
- 1.4.1 形成死锁的4个必要条件
- 1.4.2 如何避免线程死锁
- 1.5 线程的状态
- 1.5.1 sleep和wait的区别
- 1.5.2 wait的使用
- 1.5.3 为什么wait、notify、notifyAll跟synchronized一起使用?
- 1.6 创建线程的四种方式
- 1.6.1 runnable和callable的区别
- 1.6.2 为什么Callable需要FutureTask包装一下?
- 1.6.3 在主线程中等待子线程结束的7种方式
- 1.7 线程的 run()和 start()有什么区别?
- 1.8 Future是什么?
1.并发编程(高并发、多线程)
1.1 并发编程的三个必要因素
- 原子性:原子, 即一个不可再被分割的颗粒。原子性指的是一个或多个操作要么全部执行成功, 要么全部执行失败。
- 可见性:一个线程对共享变量的修改,另一个线程能够立刻看到。(synchronized,volatile)
- 有序性:程序执行的顺序按照代码的先后顺序执行。(处理器可能会对指令进行重排序)
1.2 Java程序中怎么保证多线程的运行安全?
- 线程切换带来的原子性问题解决办法:使用多线程之间同步synchronized或使用锁(lock)。
- 缓存导致的可见性问题解决办法:synchronized、volatile、LOCK,可以解决可见性问题
- 编译优化带来的有序性问题解决办法:Happens-Before 规则可以解决有序性问题
1.3 volatile的作用
1.3.1 保证共享变量的可见性
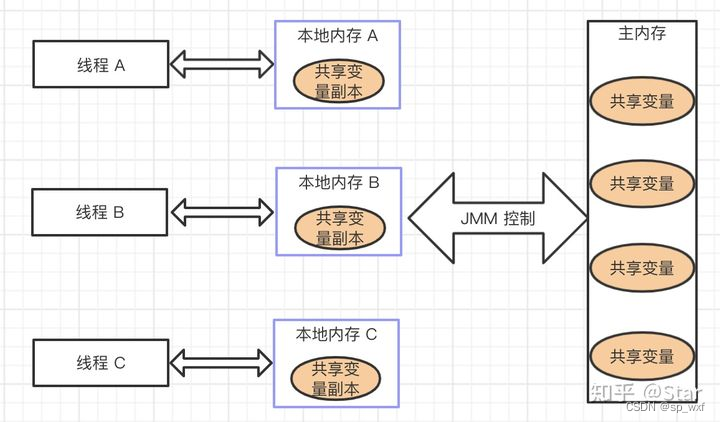
一、共享变量的可见性问题
共享变量存储在主内存中, 各个线程在使用共享变量时都会先将共享变量复制进当前线程的工作内存中, 后续使用到该变量时, 直接从当前线程工作内存中获取变量值,此时如果其他线程更改了该共享变量值, 那么当前线程无法实时更新到该变量的最新值。
二、volatile如何保证变量的可见性(原理)
将共享变量声明为volatile后, 所有对共享变量的写入都会立即写入主内存, 所有对共享变量的读取都从主内存中读取
1.3.2 禁止指令重排
1.4 死锁
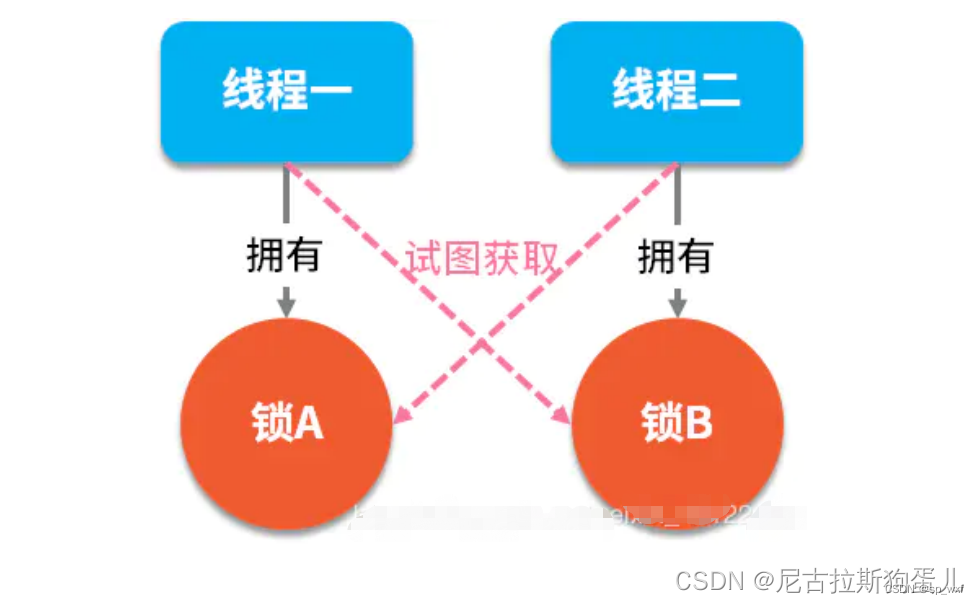
死锁是指两个或两个以上的进程(线程)在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程(线程)称为死锁进程(线程)。
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻
塞,因此程序不可能正常终止。
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
死锁代码:
public class DeadLockDemo {private static String A = "A";private static String B = "B";public static void main(String[] args) {Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {synchronized (A) {// 休眠2秒,等待t2线程锁了Btry {Thread.currentThread().sleep(2000);} catch (Exception e) {e.printStackTrace();}// 等待t2线程释放Bsynchronized (B) {System.out.println("BBBBBBBBBBBBb");}}}});Thread t2 = new Thread(new Runnable() {@Overridepublic void run() {synchronized (B) {// 等待t1线程释放Asynchronized (A) {System.out.println("AAAAAAAA");}}}});t1.start();t2.start();}
}
1.4.1 形成死锁的4个必要条件
- 互斥条件:在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,就只能等
待,直至占有资源的进程用毕释放。 - 占有且等待条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
- 不可抢占条件:别人已经占有了某项资源,你不能因为自己也需要该资源,就去把别人的资源抢过来。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。(比如一个进程集合,A在等B,B在等C,C在等A)
1.4.2 如何避免线程死锁
- 避免一个线程同时获得多个锁
- 避免一个线程在锁内同时占用多个资源,尽量保证每个锁只占用一个资源
- 尝试使用定时锁,使用lock.tryLock(timeout)来替代使用内部锁机制
1.5 线程的状态
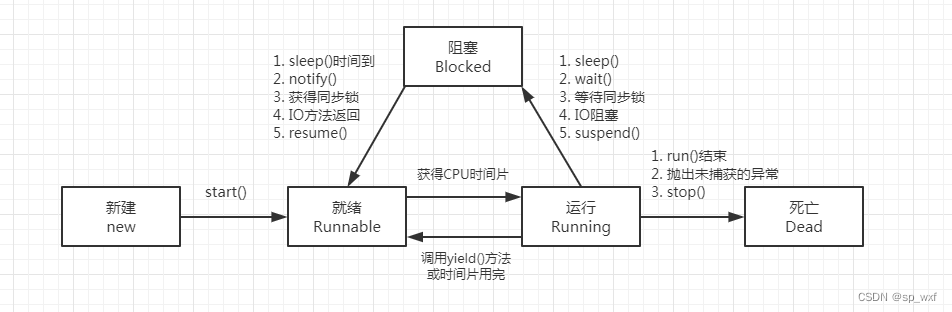
- 新建: 用new关键字创建一个线程时,还没调用start 就是新建状态。
- 就绪: 调用了 start 方法之后,线程就进入了就绪阶段。此时,线程不会立即执行run方法,需要等待获取CPU资源。
- 运行: 当线程获得CPU时间片后,就会进入运行状态,开始执行run方法。
- 阻塞: 当遇到以下几种情况,线程会从运行状态进入到阻塞状态。
- 调用sleep方法,使线程睡眠
- 调用wait方法,使线程进入等待
- 当线程去获取同步锁的时候,锁正在被其他线程持有
- 调用阻塞式IO方法时会导致线程阻塞。
- 调用suspend方法,挂起线程,也会造成阻塞。
- 死亡: 当run方法正常执行结束时,或者由于某种原因抛出异常都会使线程进入死亡状态。另外,直接调用stop方法也会停止线程。但是,此方法已经被弃用,不推荐使用。
其中需要注意:阻塞状态只能进入就绪状态,不能直接进入运行状态。因为,从就绪状态到运行状态的切换是不受线程自己控制的,而是由线程调度器所决定。只有当线程获得了CPU时间片之后,才会进入运行状态。
1.5.1 sleep和wait的区别
sleep和wait都是用来将线程进入阻塞状态的, 但是两者存在很大的差别
一、所属类不同
- wait是Object的方法,任何对象实例都能调用
- sleep是Thread的静态方法
二、释放锁资源不同
- sleep不会释放锁,它也不需要占用锁
- wait会释放锁,但调用它的前提是当前线程占有锁(即代码要在synchronized中)。
-------------------------- 测试 sleep 不释放锁 ----------------------------
public static void main(String[] args) throws InterruptedException {Object lock = new Object();new Thread(() -> {synchronized (lock) {System.out.println("新线程获取到锁:" + LocalDateTime.now());try {// 休眠 2sThread.sleep(2000);System.out.println("新线程获释放锁:" + LocalDateTime.now());} catch (InterruptedException e) {e.printStackTrace();}}}).start();// 等新线程先获得锁Thread.sleep(200);System.out.println("主线程尝试获取锁:" + LocalDateTime.now());// 在新线程休眠之后,尝试获取锁synchronized (lock) {System.out.println("主线程获取到锁:" + LocalDateTime.now());}
}-------------------------- 测试 wait 释放锁 ----------------------------
public static void main(String[] args) throws InterruptedException {Object lock = new Object();new Thread(() -> {synchronized (lock) {System.out.println("新线程获取到锁:" + LocalDateTime.now());try {// 休眠 2slock.wait(2000);System.out.println("新线程获释放锁:" + LocalDateTime.now());} catch (InterruptedException e) {e.printStackTrace();}}}).start();// 等新线程先获得锁Thread.sleep(200);System.out.println("主线程尝试获取锁:" + LocalDateTime.now());// 在新线程休眠之后,尝试获取锁synchronized (lock) {System.out.println("主线程获取到锁:" + LocalDateTime.now());}
}
Thread.Sleep(2000) 意思是在未来的2000毫秒内本线程不参与CPU竞争,2000毫秒过去之后,这时候也许另外一个线程正在使用CPU,那么这时候操作系统是不会重新分配CPU的,直到那个线程挂起或结束,即使这个时候恰巧轮到操作系统进行CPU 分配,那么当前线程也不一定就是总优先级最高的那个,CPU还是可能被其他线程抢占去。另外值得一提的是Thread.Sleep(0)的作用,就是触发操作系统立刻重新进行一次CPU竞争,竞争的结果也许是当前线程仍然获得CPU控制权,也许会换成别的线程获得CPU控制权。
wait(2000)表示将锁释放2000毫秒,到时间后如果锁没有被其他线程占用,则再次得到锁,然后wait方法结束,执行后面的代码,如果锁被其他线程占用,则等待其他线程释放锁。注意,设置了超时时间的wait方法一旦过了超时时间,并不需要其他线程执行notify也能自动解除阻塞,但是如果没设置超时时间的wait方法必须等待其他线程执行notify。
三、唤醒方式不同
- sleep 方法具有主动唤醒功能
- 而不传递任何参数的 wait 方法只能被动的被唤醒。
wait与sleep的讲解(wait有参及无参区别)
1.5.2 wait的使用
一、wait() 与wait( long timeout ) 区别
- wait( long timeout) :当线程超过了设置时间之后,自动恢复执行;
- wait( long timeout): 线程会一直等待, 直到被notify或ontifyAll进行唤醒
public class WaitDemo4 {public static void main(String[] args) {Object lock = new Object();Object lock2 = new Object();new Thread(() -> {System.out.println("线程1: 开始执行" + LocalDateTime.now());synchronized (lock) {try {lock.wait();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("线程1: 执行完成" + LocalDateTime.now());}},"无参wait线程").start();new Thread(() -> {System.out.println("线程2: 开始执行" + LocalDateTime.now());synchronized (lock2) {try {lock2.wait(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("线程2: 执行完成" + LocalDateTime.now());}},"有参wait线程").start();}
}输出:
线程1: 开始执行2023-03-16T19:59:31.246995600
线程2: 开始执行2023-03-16T19:59:31.246995600
线程2: 执行完成2023-03-16T19:59:32.249342200
二、notify、notifyAll唤醒wait的线程
- 无论是有参的wait方法还是无参的wait方法,它都可以使用当前线程进入休眠状态。
- 无论是有参的wait方法还是无参的wait方法,它都可以使用notify / ontifyAll进行唤醒。
测试notify唤醒线程
public class WaitDemo5 {public static void main(String[] args) {Object lock = new Object();Object lock2 = new Object();new Thread(() -> {synchronized (lock2) {System.out.println("线程2: 开始执行" + LocalDateTime.now());try {lock2.wait(60 * 60 * 1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("线程2: 执行完成" + LocalDateTime.now());}},"有参wait线程").start();new Thread(() -> {try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}synchronized (lock2) {System.out.println("唤醒线程2");lock2.notify();}}).start();}
}输出:
线程2: 开始执行2022-04-12T12:28:23.200
唤醒线程2
线程2: 执行完成2022-04-12T12:28:24.169
测试notifyAll唤醒线程
public class WaitDemo6 {public static void main(String[] args) {Object lock = new Object();new Thread(() -> {System.out.println("线程1: 开始执行" + LocalDateTime.now());synchronized (lock) {try {lock.wait();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("线程1: 执行完成" + LocalDateTime.now());}},"无参wait线程").start();new Thread(() -> {System.out.println("线程2: 开始执行" + LocalDateTime.now());synchronized (lock) {try {lock.wait(60 * 60 * 1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("线程2: 执行完成" + LocalDateTime.now());}},"有参wait线程").start();new Thread(() -> {try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}synchronized (lock) {System.out.println("唤醒所有线程");lock.notifyAll();}}).start();}
}输出:
线程1: 开始执行2022-04-12T12:34:34.317
线程2: 开始执行2022-04-12T12:34:34.317
唤醒所有线程
线程2: 执行完成2022-04-12T12:34:35.295
线程1: 执行完成2022-04-12T12:34:35.295
1.5.3 为什么wait、notify、notifyAll跟synchronized一起使用?
- Object.wait():释放当前对象锁,并进入阻塞队列
- Object.notify():唤醒当前对象阻塞队列里的任一线程(并不保证唤醒哪一个)
- Object.notifyAll():唤醒当前对象阻塞队列里的所有线程
为什么这三个方法要与synchronized一起使用呢?解释这个问题之前,我们先要了解几个知识点
JVM 在运行时会强制检查 wait 和 notify 有没有在 synchronized 代码中,如果没有的话就会报非法监视器状态异常(IllegalMonitorStateException),但这也仅仅是运行时的程序表象,那为什么 Java 要这样设计呢?其实这样设计的原因就是为了防止多线程并发运行时,程序的执行混乱问题。
wait和notify问题复现
我们假设 wait 和 notify 可以不加锁,我们用它们来实现一个自定义阻塞队列。这里的阻塞队列是指读操作阻塞,也就是当读取数据时,如果有数据就返回数据,如果没有数据则阻塞等待数据,实现代码如下:
class MyBlockingQueue {// 用来保存数据的集合Queue queue = new LinkedList<>();/*** 添加方法*/public void put(String data) {// 队列加入数据queue.add(data); // 唤醒线程继续执行(这里的线程指的是执行 take 方法的线程)notify(); // 步骤三}/*** 获取方法(阻塞式执行)* 如果队列里面有数据则返回数据,如果没有数据就阻塞等待数据* @return*/public String take() throws InterruptedException {// 使用 while 判断是否有数据(这里使用 while 而非 if 是为了防止虚假唤醒)while (queue.isEmpty()) { // 步骤一 // 没有任务,先阻塞等待wait(); // 步骤二}return queue.remove(); // 返回数据
}
注意上述代码,我们在代码中标识了三个关键执行步骤:①:判断队列中是否有数据;②:执行 wait 休眠操作;③:给队列中添加数据并唤醒阻塞线程。如果不强制要求添加 synchronized,那么就会出现如下问题:
| 步骤 | 线程1 | 线程2 |
|---|---|---|
| 1 | 执行步骤一判断当前队列中没有数据 | |
| 2 | 执行步骤三将数据添加到队列,并唤醒线程1继续执行 | |
| 3 | 执行步骤二线程1进入休眠状态 |
如果 wait 和 notify 不强制要求加锁,那么在线程 1 执行完判断之后,尚未执行休眠之前,此时另一个线程添加数据到队列中。然而这时线程 1 已经执行过判断了,所以就会直接进入休眠状态,从而导致队列中的那条数据永久性不能被读取,这就是程序并发运行时“执行结果混乱”的问题。
然而如果配合 synchronized 一起使用的话,代码就会变成以下这样:
class MyBlockingQueue {// 用来保存任务的集合Queue queue = new LinkedList<>();/*** 添加方法*/public void put(String data) {synchronized (MyBlockingQueue.class) {// 队列加入数据queue.add(data);// 为了防止 take 方法阻塞休眠,这里需要调用唤醒方法 notifynotify(); // 步骤三}}/*** 获取方法(阻塞式执行)* 如果队列里面有数据则返回数据,如果没有数据就阻塞等待数据* @return*/public String take() throws InterruptedException {synchronized (MyBlockingQueue.class) {// 使用 while 判断是否有数据(这里使用 while 而非 if 是为了防止虚假唤醒)while (queue.isEmpty()) { // 步骤一// 没有任务,先阻塞等待wait(); // 步骤二}}return queue.remove(); // 返回数据}
}
这样改造之后,关键步骤 ① 和关键步骤 ② 就可以一起执行了,从而当线程执行了步骤 ③ 之后,线程 1 就可以读取到队列中的那条数据了,它们的执行流程如下:
| 步骤 | 线程1 | 线程2 |
|---|---|---|
| 1 | 执行步骤一判断当前队列没有数据 | |
| 2 | 执行步骤二线程进入休眠状态 | |
| 3 | 执行步骤三将数据添加到队列,并执行唤醒操作 | |
| 4 | 线程被唤醒,继续执行 | |
| 5 | 判断队列中有数据,返回数据 |
总结
本文介绍了 wait 和 notify 的基础使用,以及为什么 wait 和 notify/notifyAll 一定要配合 synchronized 使用的原因。如果 wait 和 notify/notifyAll 不强制和 synchronized 一起使用,那么在多线程执行时,就会出现 wait 执行了一半,然后又执行了添加数据和 notify 的操作,从而导致线程一直休眠的缺陷。
1.6 创建线程的四种方式
- 继承 Thread 类;
- 实现 Runnable 接口
- 实现 Callable 接口
- 使用匿名内部类方式
// 继承 Thread 类
public class MyThread extends Thread {@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + " run()方法正在执行...");
}// 实现 Runnable 接口
public class MyRunnable implements Runnable {@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + " run()方法执行中...");
}// 实现 Callable 接口
public class MyCallable implements Callable {@Overridepublic Integer call() {System.out.println(Thread.currentThread().getName() + " call()方法执行中...");return 1;}
}// 使用匿名内部类方式
public class CreateRunnable {public static void main(String[] args) {//创建多线程创建开始Thread thread = new Thread(new Runnable() {public void run() {for (int i = 0; i < 10; i++) {System.out.println("i:" + i);}}});thread.start();}
}
1.6.1 runnable和callable的区别
- 相同点:
- 两者都需要调用Thread.start()启动线程
- 不同点
- Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,是个泛型,和Future、
FutureTask配合可以用来获取异步执行的结果 - Callable接口的call()方法允许抛出异常;而Runnable接口的run()方法的异常只能在内部消化,不能继续上抛;
- Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,是个泛型,和Future、
一、获取Callable的call()方法的返回值
如果我们想要拿到线程的执行结果(返回值), 就需要等待这个线程执行结束, 需要使用FutureTask的get()方法等待子线程结束后返回结果, 在这个阶段主线程是阻塞的
public class CallableTest implements Callable {private String str;public CallableTest(String str) {this.str = str;}@Overridepublic String call() throws Exception {//任务阻塞5秒,异常向上抛出Thread.sleep(5000);return this.str;}public static void main(String[] args) throws ExecutionException, InterruptedException {Callable callable = new CallableTest("my callable is ok!");FutureTask task = new FutureTask(callable);// 创建线程new Thread(task).start();// 调用get()方法阻塞主线程String str = task.get();System.out.println("hello :" + str);}
}
- 使用了FutureTask中的get方法就可以实现线程的同步等待
- Callable的call()可以throws Exception, 需要配置FutureTask中的get()方法使用, 才能在外部线程中捕获到异常, 不然外部线程都执行结束了, 你再抛异常就没有线程能捕获到这个异常了
- 而runnable的run()方法中是不能抛异常的, 所以只能在run方法中内部处理异常
1.6.2 为什么Callable需要FutureTask包装一下?
因为Thread类的构造方法需要的参数,是Runnable
public Thread(Runnable target) {init(null, target, "Thread-" + nextThreadNum(), 0);
}
- 首先可以通过
FutureTask的构造方法,传入Callable接口的实例,构造FutureTask对象 - 由于
FutureTask间接实现了Runnable接口,同时Thread类的构造方法要求放入一个Runnable,这时候就可以放入当前构造的FutureTask对象
1.6.3 在主线程中等待子线程结束的7种方式
一、while循环
不断的轮巡子线程是否存活
public static void main(String[] args)// 启动线程Thread t = new Thread(() -> {......};t.start();// 当线程结束后, 就会跳出while循环, 也代表了子线程执行结束while(t.isAlive() == true){System.out.println("子线程还在执行");// 加入sleep, 减少对cpu性能的消耗try {Thread.sleep(10);}catch (InterruptedException e){e.printStackTrace();}}System.out.println("子线程执行结束");
}
二、Thread的join方法
作用:join方法会挂起调用线程(当前线程)的执行, 等待被调用的对象完成它的执行
public static void main(String[] args)// 启动线程Thread t = new Thread(() -> {......};t.start();// 等待t线程执行结束t.join();System.out.println("子线程执行结束");
}
1.7 线程的 run()和 start()有什么区别?
- 用 start方法来启动线程, 是真正实现了多线程, 这时此线程处于就绪(可运行)状态, 接着会尝试去获取cpu时间片, 当线程获得CPU时间片后,就会进入运行状态,开始执行run方法。
- run方法,只是类的一个普通方法
1.8 Future是什么?
Future表示一个可能还没有完成的异步任务的结果, 通过实现Callback接口,并用Future可以来接收多线程的执行结果。