计算机科学导论笔记(十三)
目录
十五、数据压缩
15.1 引言
15.2 无损压缩方法
15.2.1 游程长度编码
15.2.2 哈夫曼编码
15.2.3 Lempel-Ziv编码
15.3 有损压缩方法
15.3.1 图像压缩:JPEG
15.3.2 视频压缩:MPEG
15.3.3 音频压缩
十五、数据压缩
压缩数据通过部分消除数据中的冗余来减少发送或存储的数据量。当我们产生数据的同时,冗余也就产生了。通过数据压缩,提高了数据传输和存储的效率,同时保护了数据的完整性。
15.1 引言
数据压缩意味着发送或是存储更少的位数,一般可以分为两类:无损压缩和有损压缩。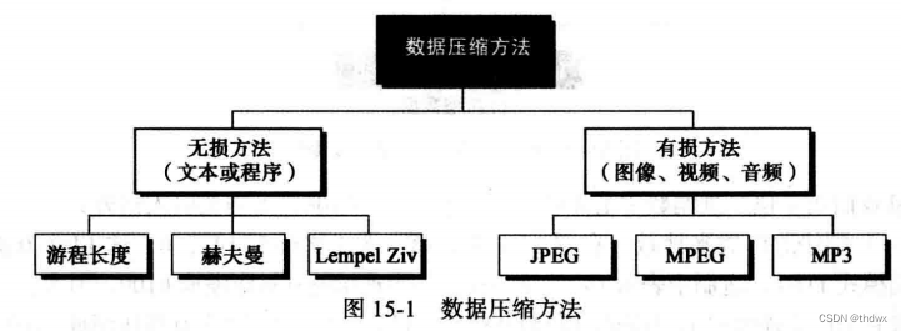
15.2 无损压缩方法
在无损压缩中,数据的完整性受到保护,压缩解压后的数据与原始数据是完全一样的。解压和压缩是完全相反的两个过程。通常这种压缩方法使用在不希望数据损失的地方,如:压缩文档资料或应用程序。无损压缩有3种方法:游程长度编码、哈夫曼编码和Lempel-Ziv编码编码。
15.2.1 游程长度编码
游程长度编码也许是最简单的压缩方法,它可以用来压缩由任何符号组成的数据。
这种编码的大致思想是:将数据中连续重复出现的符号用一个字符和它出现的次数来代替。例如,AAAAAAAA可以使用A08来代替,这里我们使用两位数字来表示重复次数。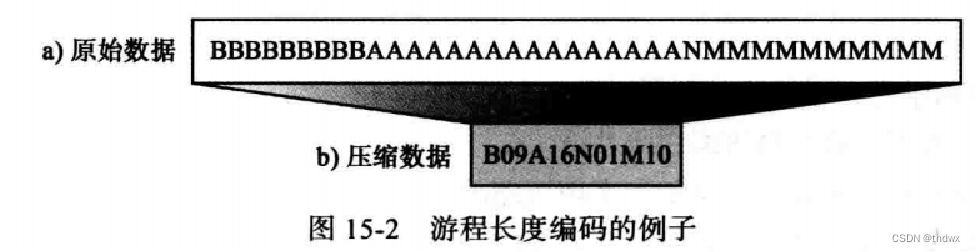
在位模式中,数据只有0和1两种符号,并且一种符号出现频率比另一种符号更高,那么这种压缩方法就更有效。例如,在位模式中,0比1出现的更频繁,那么,就可以在发送时只标记两个1中间有几个0来进行压缩。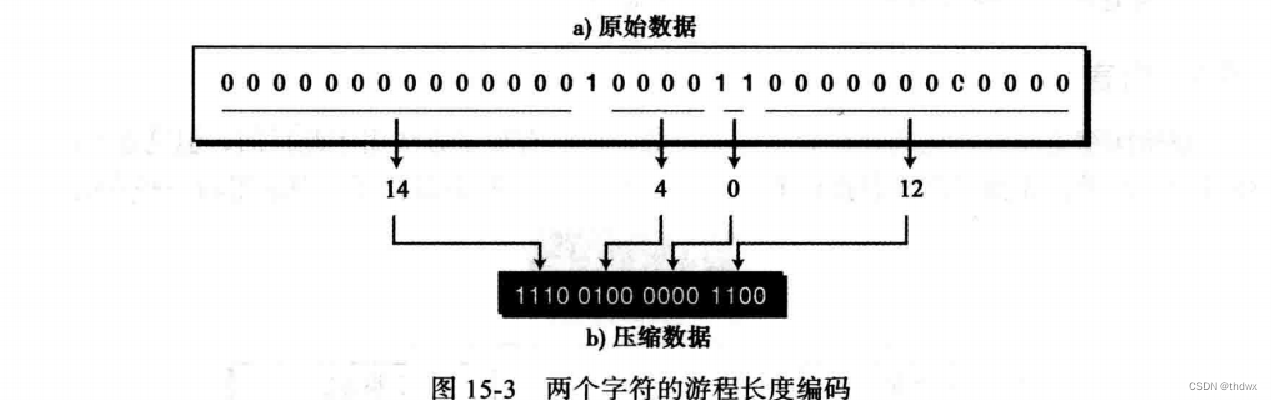
这里使用四位二进制数来表示两个1中间0的个数。在解压时,只需要每四位还原0的个数,然后在后面加上1,重复这个操作就可以还原数据。这里有个疑问,大于15位的0如何表示?解决方法是,当四位二进制数等于15,默认后面四位依然是表示这次的0的个数,例如:25个0表示位(1111 1010)、15表示为(1111 0000)。
15.2.2 哈夫曼编码
哈夫曼编码是一种即时的编码,也就是说,当接收方收到有意义的编码时,他就可以进行译码,这是因为哈夫曼编码是没有二义性的。
下面的文章中有哈夫曼编码的实现:
贪婪算法(Huffman编码)-CSDN博客
15.2.3 Lempel-Ziv编码
LZ编码是一种基于字典的编码,在通信会话的时候它将产生一个字符串字典(一个表)。如果发送者和接收者都有这样的字典,那么字符串就可以由字典中的索引代替,以减少数据传输量。
压缩阶段,有两个工作:建立字典索引和压缩字符串。算法从未压缩的字符串中取出最小的且不存在于字典的子字符串,并在字典中为这个子字符串建立索引。然后,将这个子字符串的最后一位保留,其他部分替换成字典中的索引。最后将索引和最后一位字符添加到压缩字符串中。重复这个过程直到整个字符串被压缩。下图清楚的展示了压缩的过程: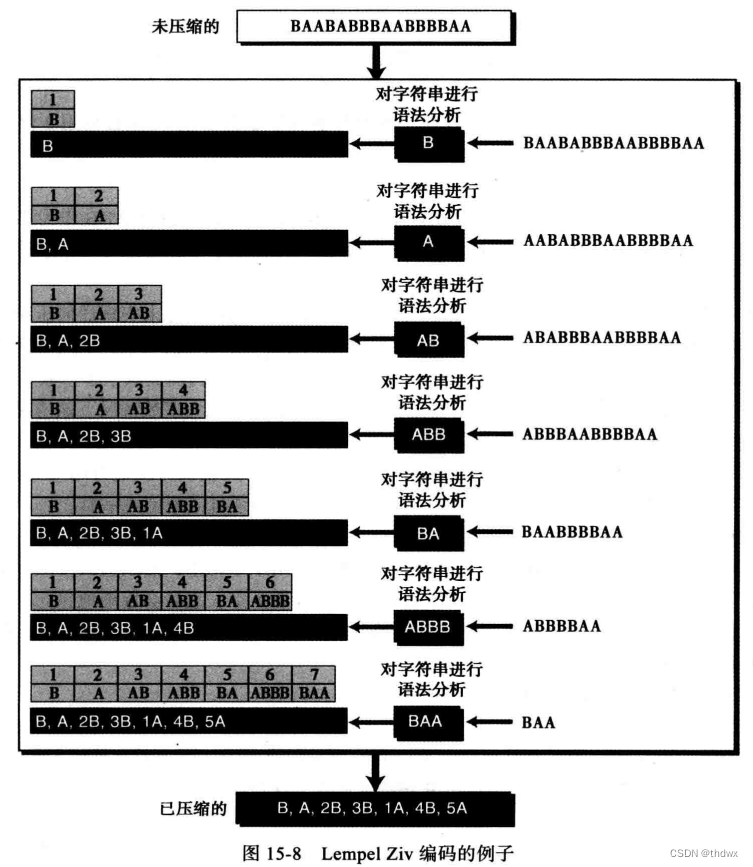
解压阶段,解压是压缩的逆过程,首先从压缩的字符串中取出子字符串(索引和最后一位字符),通过字典将索引还原,再加上最后一位字符插入到还原的字符串中。在这个过程中,每还原一个子字符串,就会向字典中加入新的索引,用于后续的还原,下图清楚的介绍了解压的过程: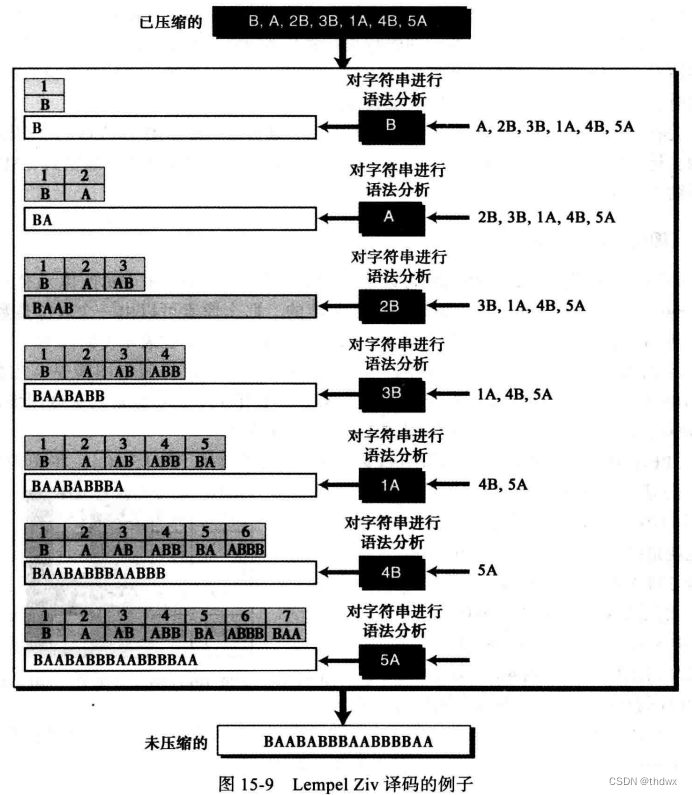
在上面的例子中,我们用数字作为索引号。实际中,使用位模式(长度是变化的)作为索引号来提高效率。LZ编码有一个版本,叫作Lempel Ziv Welch(LZW编码),这个编码将最后一个字符也压缩了。
15.3 有损压缩方法
当我们发送或存储文档或是应用程序时,我们不希望有数据的损失。但在其他一些数据上,损失是可以接收的。在图像、音频和视频等数据中,我们没有办法分辨出一些细微的差别,所以压缩解压过程中的数据损失是可以接受的。也就是说,对于音频、图像和视频,可以使用有损压缩方法。这使得我们在每秒传送数百万位的图像和视频时只需要花费更少的时间和空间以及更廉价的代价。
联合图像专家组(JPEG)用来压缩图像;运动图像专家组(MPEG)用来压缩视频;MPEG第三代音频压缩格式(MP3)用来压缩声音。
这几种压缩原理都比较复杂难懂,下面就简要介绍。
15.3.1 图像压缩:JPEG
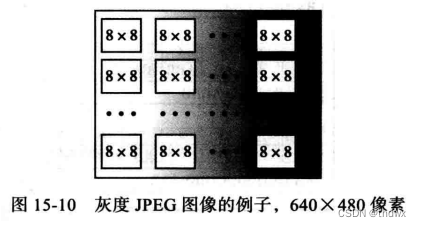
一幅图像可以通过一个二维数组来表示图像元素(像素),例如,640*480=307200像素。如果图像是灰度的,那么每个像素可以使用一个8位整数来表示,如果图像是彩色的,每个像素使用3个8位整数来表示,分别代表RBG颜色系统中的一个颜色。为了讨论简单,假定图像是灰度且有640*480像素。一个有307200像素的灰度图片需要2457600位来表示,彩色图片则需要7372800位来表示。
在JPEG中,一幅灰度图像被分为许多8*8的像素块。将图像划分成块是为了减少计算量。每幅图像的数学运算量是单元数的平方。整个图像需要307200*307200=94371840000次运算,如果使用JPEG,则需要每个块进行64*64次运算,总共需要64*64*80*60=19660800次运算。运算量减少到原来的4800分之一。
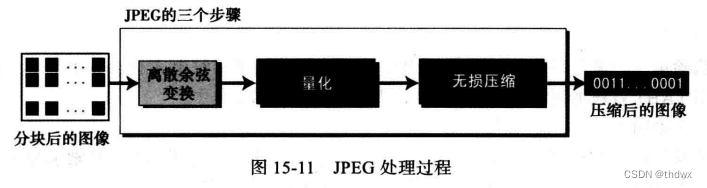
JPEG的整体思路是将图像变换成一个数的线性(矢量)集合来揭示冗余。这些冗余(缺乏变化的)可以通过使用前面的无损压缩方法来除去。下图给出了一个简单的处理过程,DCT是离散余弦变换。
15.3.2 视频压缩:MPEG
原则上,一个运动的图像是一系列快速帧的序列。每个帧都是一副图像。帧是像素在空间上的组合,视频是一幅接一幅发送的帧在时间上的组合。压缩视频,就是对每帧空间上的压缩和一系列帧时间上的压缩。
空间压缩:每一帧的空间压缩使用JPEG(或它的改进版)。每一帧都是一幅图像,可以单独压缩。
时间压缩:在时间压缩中,多余的帧将被丢弃。当我们看电视时,每秒接收30帧。但是大多数连续的帧几乎是一样的。为了压缩时间数据,MPEG把帧分为三类:I-帧(独立于其他帧,不能由其他帧构造)、P-帧(与前面的I-帧或P-帧有关联)和B-帧(与前面和后面的I-帧或P-帧有关系)。
MPEG有很多版本,上面讨论的是MPEG-1相关的,MPEG-2于1991年引入,既能用作视频存储,也能用作电视广播,包括高清电视(HDTV)。MPEG-7(多媒体内容描述接口)大部分使用XML描述元数据(关于数据的数据)和对视频中所含内容的描述的标准。
15.3.3 音频压缩
音频压缩可以用来处理语音和音乐。对于语音,需要压缩一个64 kHz的数字化信号,对于音乐,需要压缩一个1.411 MHz的信号。有两类技术用于音频压缩:预测编码和感知编码。
1. 预测编码
在预测编码中,样本间的差别被编码,而不是对所有的样本值进行编码。这样的压缩方法通常在语音上,。已经定义的标准有:GSM(13 kbps)、G.729(8 kbps)和G.723.3(6.4 kbps或5.3 kbps)。
2. 感知编码:MP3
用来创建CD质量音频最常用的压缩技术是基于感知编码技术的。这种类型的音频至少为1.411 Mbps,如果没有压缩,它是不能送到因特网上去的。MP3使用的就是这种技术。
感知编码是基于心理声学的,心理声学是一门研究人类如何感知声音的科学。掩盖可以发生在频率上和时间上。在频率掩盖中,一个频率范围的高的声音可以部分或完全掩盖另一个频率范围的低的声音,例如,站在音响旁边就可能听不到别人说话的声音。在时间掩盖中,即使高音停止后,它也可以在短时间内降低我们的听觉灵敏度。
MP3使用这两种现象来压缩音频信号。该技术分析音谱并把音谱分成几个组。0位被赋给那些频率范围被完全掩盖的,小数值的位被赋给频率范围被部分掩盖的。大数值被赋给那些不被掩盖的。
MP3有三种速率:96 kbps、128 kbps和160 kbps。速率是基于原始模拟音频的频率范围的。