leetcode 81~90 学习经历
leetcode 71~80 学习经历
- 81. 搜索旋转排序数组 II
- 82. 删除排序链表中的重复元素 II
- 83. 删除排序链表中的重复元素
- 84. 柱状图中最大的矩形
- 85. 最大矩形
- 86. 分隔链表
- 87. 扰乱字符串
- 88. 合并两个有序数组
- 89. 格雷编码
- 90. 子集 II
- 小结
81. 搜索旋转排序数组 II
已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转 ,使数组变为 [nums[k], nums[k+1], …, nums[n-1], nums[0], nums[1], …, nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,4,4,5,6,6,7] 在下标 5 处经旋转后可能变为 [4,5,6,6,7,0,1,2,4,4] 。
给你 旋转后 的数组 nums 和一个整数 target ,请你编写一个函数来判断给定的目标值是否存在于数组中。如果 nums 中存在这个目标值 target ,则返回 true ,否则返回 false 。
你必须尽可能减少整个操作步骤。
示例 1:
输入:nums = [2,5,6,0,0,1,2], target = 0
输出:true
示例 2:
输入:nums = [2,5,6,0,0,1,2], target = 3
输出:false
进阶:
这是 搜索旋转排序数组 的延伸题目,本题中的 nums 可能包含重复元素。
这会影响到程序的时间复杂度吗?会有怎样的影响,为什么?
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/search-in-rotated-sorted-array-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
哦,二分查找,不过分成前后两段了。貌似在什么地方见到过这个题目。。。。
是我天真了。。。。碰到一个用例 nums = [1,1,1,1,1,1,1,1,1,1,1,1,1,2,1,1,1,1,1],target = 2,自己坑死自己
class Solution:def search(self, nums: List[int], target: int) -> bool:if nums[0] == target:return Truel,r = 0,len(nums) - 1while r > 1 and nums[0] == nums[r]:r -= 1 # 确定右边与前边不重复的位置while l <= r:m = (l + r) // 2if nums[m] == target:return Trueelif nums[m] < target: # 如果中间数小于目标if target <= nums[r]: # 因为是升序排列数组旋转后的结果,所以如果中间数小于右边数,则是后半段l = m + 1else:# 如果中间数小于 target ,但是右边数也小于目标数,所以右边向前收缩r -= 1else:if target >= nums[l]:r = m - 1else:l += 1return False
这个题目体现不出二分查找的优势,我自己用循环迭代,和这个速度基本一致,用例没有给出很长的那种,差评
82. 删除排序链表中的重复元素 II
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
输入:head = [1,1,1,2,3]
输出:[2,3]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/remove-duplicates-from-sorted-list-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
又是链表。。。。我先用数组完成,然后看看大佬们怎么玩的链表
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def deleteDuplicates(self, head: Optional[ListNode]) -> Optional[ListNode]:top = ListNode(0)ans = toparr = {}while head:if head.val not in arr:arr[head.val] = [head]else:arr[head.val].append(head)head = head.nextfor k in arr:if len(arr[k]) == 1:top.next = arr[k][0]top = top.nexttop.next = Nonereturn ans.next
嗯,24ms大佬,直接用一个变量记录出现的重复值,而且没有数组、字典辅助,赞一个
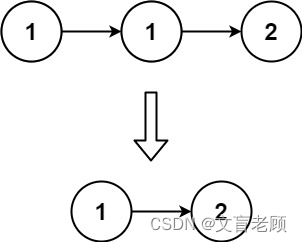
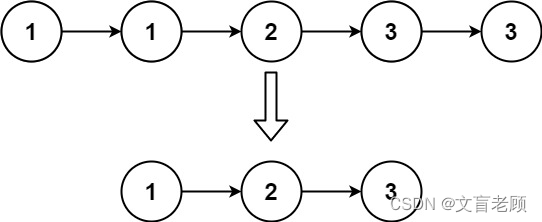
83. 删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
输入:head = [1,1,2]
输出:[1,2]
示例 2:
输入:head = [1,1,2,3,3]
输出:[1,2,3]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/remove-duplicates-from-sorted-list
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
和上边的题感觉重复了,正好学习上一题大佬的方法,不用数组,不用字典
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def deleteDuplicates(self, head: Optional[ListNode]) -> Optional[ListNode]:top = ListNode(0,head)ans = topwhile head:while head.next and head.val == head.next.val:head = head.nextans.next = headans = ans.nexthead = head.nextreturn top.next
额。。。24ms大佬又用双指针滑动。。。。
84. 柱状图中最大的矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
示例 1:
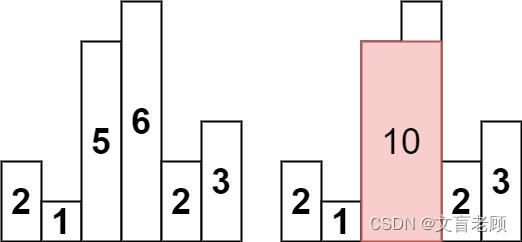
输入:heights = [2,1,5,6,2,3]
输出:10
解释:最大的矩形为图中红色区域,面积为 10
示例 2:
输入: heights = [2,4]
输出: 4
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/largest-rectangle-in-histogram
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
和接雨水的题目很接近啊,嗯,路子是一个路子,思考的方向不一样,仔细又想了想,大家不觉的这个用中心扩散法比较好么
class Solution:def largestRectangleArea(self, heights: List[int]) -> int:n = len(heights)hc = [1 for _ in range(n)]for i,h in enumerate(heights):idx = i - 1while idx >= 0 and heights[idx] >= h:hc[i] += 1idx -= 1idx = i + 1while idx < n and heights[idx] >= h:hc[i] += 1idx += 1hc[i] = h * hc[i]return max(hc)
然后碰到恶心的用例了。。。

后边还有一个10万数据的数组,这。。。。。。感觉掉坑里了然后拿这个用例做了个测试,自己本地spyder 跑了一次,用了26.5秒。。。。
啊。。。。这,法子是能用,但不好用啊,实在想不出什么套路,只好乖乖去看官方题解。只能说,野路子的我,对栈的使用太浅显了,太初级了,思路绕不过来,按照官方的题解,自己抄了一遍。。。ε=(´ο`*)))唉,这个真是没自己的办法了
class Solution:def largestRectangleArea(self, heights: List[int]) -> int:n = len(heights)z,l,r = [],[0] * n,[n] * nfor i,h in enumerate(heights):while z and h < heights[z[-1]]:r[z[-1]] = iz.pop()l[i] = z[-1] if z else -1 # 关于这里为什么是-1的问题,仔细扣了一段时间才弄明白。。。z.append(i)ans = 0for i in range(n):ans = max(ans,heights[i] * (r[i] - l[i] - 1))return ans
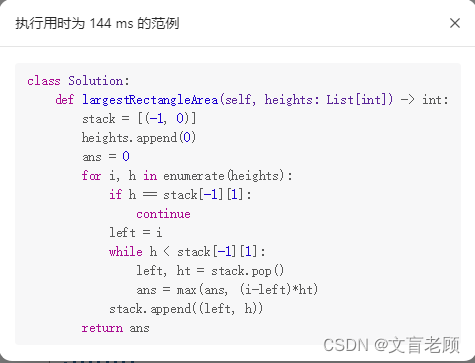
最后翻看大佬的题解,成绩如此优秀
85. 最大矩形
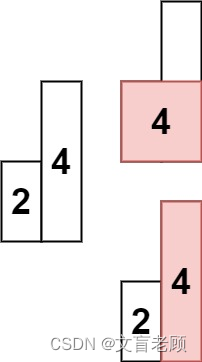
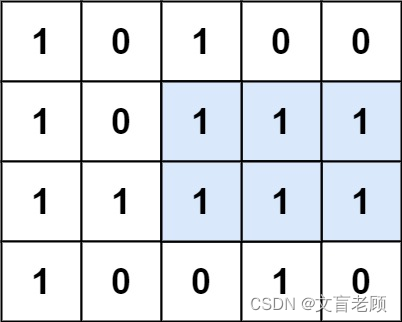
给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
示例 1:
输入:matrix = [[“1”,“0”,“1”,“0”,“0”],[“1”,“0”,“1”,“1”,“1”],[“1”,“1”,“1”,“1”,“1”],[“1”,“0”,“0”,“1”,“0”]]
输出:6
解释:最大矩形如上图所示。
示例 2:
输入:matrix = []
输出:0
示例 3:
输入:matrix = [[“0”]]
输出:0
示例 4:
输入:matrix = [[“1”]]
输出:1
示例 5:
输入:matrix = [[“0”,“0”]]
输出:0
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/maximal-rectangle
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
唔。。。感觉自己能做出来,努努力吧
class Solution:def maximalRectangle(self, matrix: List[List[str]]) -> int:m,n,mx = len(matrix),len(matrix[0]),0dp1 = [[0 for _ in range(n)] for _ in range(m)]dp2 = [[0 for _ in range(n)] for _ in range(m)]dp3 = [[0 for _ in range(n)] for _ in range(m)]for i in range(m):for j in range(n):if matrix[i][j] == '1':dp1[i][j] = 1 if i == 0 else dp1[i - 1][j] + 1dp2[i][j] = 1 if j == 0 else dp2[i][j - 1] + 1dp3[i][j] = max(dp1[i][j],dp2[i][j])if i > 0 and j > 0:rows = dp1[i][j]cols = [dp2[i - row][j] for row in range(rows)][::-1]#print(rows,cols)for z in range(rows - 1):w = cols[z]if w > min(cols[z + 1:]):w = min(cols[z + 1:])dp3[i][j] = max(dp3[i][j],w * (rows - z))mx = max(mx,dp3[i][j])return mx
磕磕绊绊,在几个用例报错之后,终于算是做出来了,效率感人啊。。。。
class Solution:def maximalRectangle(self, matrix: List[List[str]]) -> int:m,n,mx = len(matrix),len(matrix[0]),0dp = [[0 for _ in range(n)] for _ in range(m)]for i in range(m):for j in range(n):if matrix[i][j] == '1':dp[i][j] = 1 if j == 0 else dp[i][j - 1] + 1col,p,mn = [dp[i][j]],i,dp[i][j]while p > 0 and dp[p - 1][j] > 0:p -= 1mn = min(dp[p][j],mn)col.append(mn)row = len(col)z = 0while z < row:while z > 0 and z < row and col[row - z - 1] == col[row - z]:z += 1if z >= row:breakw = col[row - z - 1]mx = max(mx,(row - z) * w)z += 1return mx
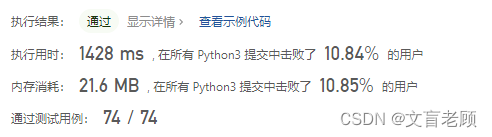
然后就是大动手术,将三个记录数据的数组变成1个,因为可以直接通过行向上追溯到不是0的行,然后,追溯过程中,前一个宽不能大于当前最小的宽,再加一个如果数相同就跳过,效率提高了几倍,但还是没什么名次,继续想,继续优化
然后就想起数据范围,按照提示,给了一个最大的数组matrix = [[‘1’ for _ in range(200)] for _ in range(200)],运行将近7秒了。。。
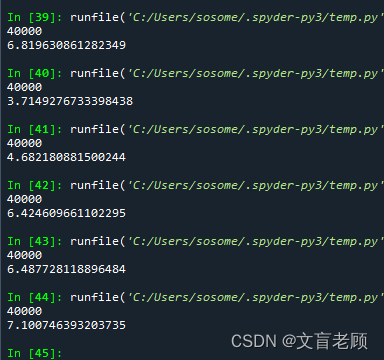
明显是每个单元格都计算产生了无效的耗时,怎么才能更优化,又不漏掉必要的计算呢?实在想不出了,看题解去了。。。。
哦哦哦,把84题的做法移植应用过来啊。。。脑抽了,没想到,从新写一遍代码。。。。另外,官方题解居然没有python版本的代码,差评
class Solution:def maximalRectangle(self, matrix: List[List[str]]) -> int:m,n,mx = len(matrix),len(matrix[0]),0dp = [[0 for _ in range(n)] for _ in range(m)]for i in range(m):for j in range(n):if matrix[i][j] == '1':dp[i][j] = 1 if j == 0 else dp[i][j - 1] + 1for j in range(n):z,l,r = [],[0] * m,[m] * mfor i in range(m):while z and dp[i][j] < dp[z[-1]][j]:r[z[-1]] = iz.pop()l[i] = z[-1] if z else -1z.append(i)for i in range(m):mx = max(mx,dp[i][j] * (r[i] - l[i] - 1))return mx
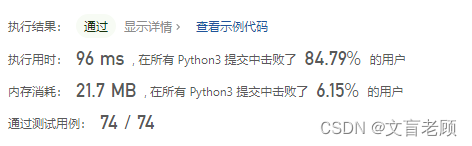
成绩提升一大截啊。。。。。就是内存用的多了点,想想办法,两个for j 有点多余了,再调整下
class Solution:def maximalRectangle(self, matrix: List[List[str]]) -> int:m,n,mx = len(matrix),len(matrix[0]),0col = [0 for _ in range(m)]for j in range(n):z,l,r = [],[0] * m,[m] * mfor i in range(m):if matrix[i][j] == '1':col[i] += 1else:col[i] = 0while z and col[i] < col[z[-1]]:r[z[-1]] = iz.pop()l[i] = z[-1] if z else -1z.append(i)for i in range(m):mx = max(mx,col[i] * (r[i] - l[i] - 1))return mx
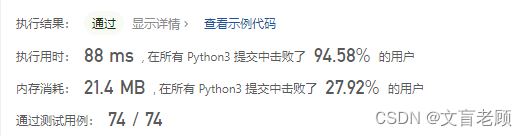
然后发现,大佬的答案如此清奇,看不懂。。。。。
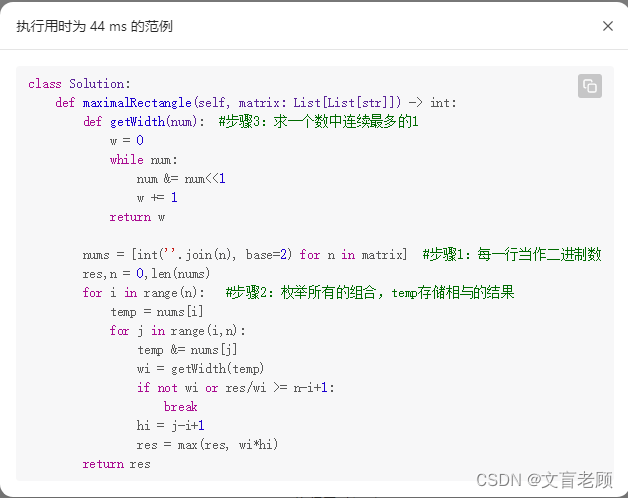
86. 分隔链表
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1,2]
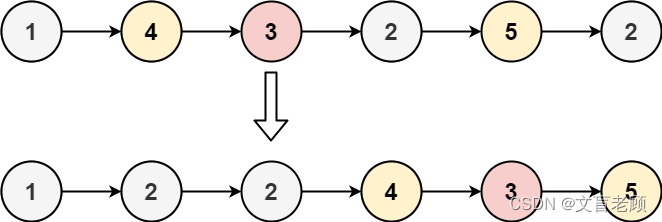
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/partition-list
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
没什么好说的,分成左右两个链表,然后对接就好
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def partition(self, head: Optional[ListNode], x: int) -> Optional[ListNode]:l = ListNode(0)ltop = lr = ListNode(0)rtop = rwhile head:if head.val < x:l.next = headl = l.nextelse:r.next = headr = r.nexthead = head.nextl.next = rtop.nextr.next = Nonereturn ltop.next
87. 扰乱字符串
使用下面描述的算法可以扰乱字符串 s 得到字符串 t :
如果字符串的长度为 1 ,算法停止
如果字符串的长度 > 1 ,执行下述步骤:
在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串 s ,则可以将其分成两个子字符串 x 和 y ,且满足 s = x + y 。
随机 决定是要「交换两个子字符串」还是要「保持这两个子字符串的顺序不变」。即,在执行这一步骤之后,s 可能是 s = x + y 或者 s = y + x 。
在 x 和 y 这两个子字符串上继续从步骤 1 开始递归执行此算法。
给你两个 长度相等 的字符串 s1 和 s2,判断 s2 是否是 s1 的扰乱字符串。如果是,返回 true ;否则,返回 false 。
示例 1:
输入:s1 = “great”, s2 = “rgeat”
输出:true
解释:s1 上可能发生的一种情形是:
“great” --> “gr/eat” // 在一个随机下标处分割得到两个子字符串
“gr/eat” --> “gr/eat” // 随机决定:「保持这两个子字符串的顺序不变」
“gr/eat” --> “g/r / e/at” // 在子字符串上递归执行此算法。两个子字符串分别在随机下标处进行一轮分割
“g/r / e/at” --> “r/g / e/at” // 随机决定:第一组「交换两个子字符串」,第二组「保持这两个子字符串的顺序不变」
“r/g / e/at” --> “r/g / e/ a/t” // 继续递归执行此算法,将 “at” 分割得到 “a/t”
“r/g / e/ a/t” --> “r/g / e/ a/t” // 随机决定:「保持这两个子字符串的顺序不变」
算法终止,结果字符串和 s2 相同,都是 “rgeat”
这是一种能够扰乱 s1 得到 s2 的情形,可以认为 s2 是 s1 的扰乱字符串,返回 true
示例 2:
输入:s1 = “abcde”, s2 = “caebd”
输出:false
示例 3:
输入:s1 = “a”, s2 = “a”
输出:true
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/scramble-string
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
额。。。这题,说实话,没明白题目描述的到底是个什么东西,还带随机?
在一个随机下标处将字符串分割
随机决定是否交换两个切片位置
???????????????????
就拿示例1来说,我随机到这样一个切片 great -> g + reat,那么,后边不管你有多少可能,因为 g 不管是否交换位置,还是在原地,他都无法切片了,按照这个规则,他不就返回 False 了?什么鬼?
class Solution:def isScramble(self, s1: str, s2: str) -> bool:print(s1,s2)if len(s1) == 1:return s1 == s2sp = random.randint(1,len(s1) - 1)n1,n2 = s1[:sp],s1[sp:]m1,m2 = s2[:sp],s2[sp:]if n1 != m1 and n2 != m2:n1,n2 = n2,n1l = self.isScramble(n1,m1)r = self.isScramble(n2,m2)return l and r
所以说,到底随机个什么鬼?这是题意都没理解啊。看官方题解去,都不需要知道算法,我只想知道,他到底要干些什么。

官方题解是什么鬼,说好的随机呢????这个描述绝对有问题,应该是任意位置,而不是随机位置啊亲!
到了这里,大概明白题目的意思了
比如 great,扰动之后,可以是 rgeat
gr eat --> g r eat --> r g eat
可以是 eatgr
gr eat -> eat gr
可以是 tareg
grea t -> t grea -> t g rea -> t rea g -> t re a g -> t a re g
但应该无法成为agrte
gre at -> at gre -> a t gre -> t a gre 失败,t 无法后移
g reat 失败,g 无法移动到中间
gr eat 失败,gr 整体无法移动到中间
grea t 失败,t 无法移动到倒数第二的位置
需要枚举验证这个到底是不是可以通过上述规则变形出来
示例2虽然一定程度上有体现出这一点,但是。。。用随机这个词,干扰性太强了啊。行吧,这次就有思路了。
class Solution:def isScramble(self, s1: str, s2: str) -> bool:if s1 == s2:return Trueif Counter(s1) != Counter(s2):return Falselength = len(s1)for i in range(1,length):ml1 = s1[:i]nl1 = s2[:i]mr1 = s1[i:]nr1 = s2[i:]ml2 = s1[i:]nl2 = s2[:length - i]mr2 = s1[:i]nr2 = s2[length - i:]if self.isScramble(ml1, nl1) and self.isScramble(mr1, nr1):return Trueif self.isScramble(ml2, nl2) and self.isScramble(mr2, nr2):return Truereturn False
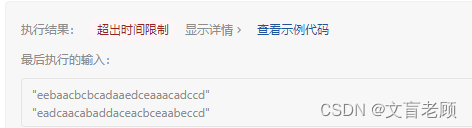
嗯,还是暴力枚举,结果倒在了超时的路上,这是因为,重复判定的地方太多了,需要记录一下已经判定过的,就直接返回已知结果,做下调整就好
class Solution:def isScramble(self, s1: str, s2: str) -> bool:t = set()f = set()def fun(s1,s2):if s1 + s2 in t:return Trueif s1 + s2 in f:return Falseif s1 == s2:t.add(s1 + s2)return Trueif Counter(s1) != Counter(s2):f.add(s1 + s2)return Falselength = len(s1)for i in range(1,length):ml1 = s1[:i]nl1 = s2[:i]mr1 = s1[i:]nr1 = s2[i:]ml2 = s1[i:]nl2 = s2[:length - i]mr2 = s1[:i]nr2 = s2[length - i:]r1 = fun(ml1, nl1)r2 = fun(mr1, nr1)if r1:t.add(ml1 + nl1)else:f.add(ml1 + nl1)if r2:t.add(mr1 + nr1)else:f.add(mr1 + nr1)if r1 and r2:return Truer1 = fun(ml2, nl2)r2 = fun(mr2, nr2)if r1:t.add(ml2 + nl2)else:f.add(ml2 + nl2)if r2:t.add(mr2 + nr2)else:f.add(mr2 + nr2)if r1 and r2:return Truereturn Falsereturn fun(s1,s2)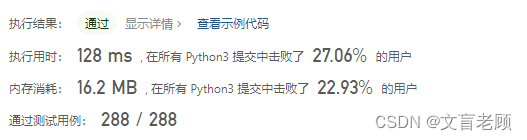
呀,成绩不太理想啊,再看看
class Solution:def isScramble(self, s1: str, s2: str) -> bool:t = set()f = set()def fun(s1,s2):if s1 + s2 in t:return Trueif s1 + s2 in f:return Falseif s1 == s2:t.add(s1 + s2)return Trueif Counter(s1) != Counter(s2):f.add(s1 + s2)return Falselength = len(s1)for i in range(1,length):ml1 = s1[:i]nl1 = s2[:i]mr1 = s1[i:]nr1 = s2[i:]ml2 = s1[i:]nl2 = s2[:length - i]mr2 = s1[:i]nr2 = s2[length - i:]r1 = fun(ml1, nl1)if r1:t.add(ml1 + nl1)else:f.add(ml1 + nl1)if r1:r2 = fun(mr1, nr1)if r2:t.add(mr1 + nr1)else:f.add(mr1 + nr1)if r2:return Truer1 = fun(ml2, nl2)if r1:t.add(ml2 + nl2)else:f.add(ml2 + nl2)if r1:r2 = fun(mr2, nr2)if r2:t.add(mr2 + nr2)else:f.add(mr2 + nr2)if r1 and r2:return Truereturn Falsereturn fun(s1,s2)
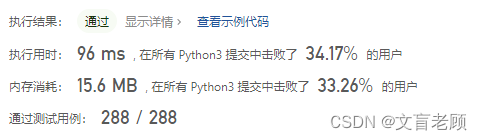
调整了一下判断次数,提高了一点点成绩,还要继续努力
class Solution:def isScramble(self, s1: str, s2: str) -> bool:t = set()f = set()def fun(s1,s2):if s1 + s2 in t or s2 + s1 in t:return Trueif s1 + s2 in f or s2 + s1 in f:return Falseif s1 == s2:t.add(s1 + s2)return Trueif Counter(s1) != Counter(s2):f.add(s1 + s2)return Falselength = len(s1)for i in range(1,length):ml1 = s1[:i]nl1 = s2[:i]mr1 = s1[i:]nr1 = s2[i:]ml2 = s1[i:]nl2 = s2[:length - i]mr2 = s1[:i]nr2 = s2[length - i:]r1 = fun(ml1, nl1)if r1:t.add(ml1 + nl1)else:f.add(ml1 + nl1)if r1:r2 = fun(mr1, nr1)if r2:t.add(mr1 + nr1)else:f.add(mr1 + nr1)if r2:return Truer1 = fun(ml2, nl2)if r1:t.add(ml2 + nl2)else:f.add(ml2 + nl2)if r1:r2 = fun(mr2, nr2)if r2:t.add(mr2 + nr2)else:f.add(mr2 + nr2)if r1 and r2:return Truereturn Falsereturn fun(s1,s2)

又调整了一下已判断过的字符串判断,s1 + s2 和 s2 + s1 都进入判定,减少后续重复判断,快达标了,加油。然后发现前边有大佬并没有用Counter,而是直接sorted了。。。额,python还有这能力啊。。。
class Solution:def isScramble(self, s1: str, s2: str) -> bool:t = set()f = set()def fun(s1,s2):if s1 + s2 in t or s2 + s1 in t:return Trueif s1 + s2 in f or s2 + s1 in f:return Falseif s1 == s2:t.add(s1 + s2)return Trueif sorted(s1) != sorted(s2):f.add(s1 + s2)return Falselength = len(s1)for i in range(1,length):m1 = s1[:i]n1 = s2[:i]if fun(m1, n1):t.add(m1 + n1)m1 = s1[i:]n1 = s2[i:]if fun(m1, n1):t.add(m1 + n1)return Trueelse:f.add(m1 + n1)else:f.add(m1 + n1)m1 = s1[i:]n1 = s2[:length - i]if fun(m1, n1):t.add(m1 + n1)m1 = s1[:i]n1 = s2[length - i:]if fun(m1, n1):t.add(m1 + n1)return Trueelse:f.add(m1 + n1)else:f.add(m1 + n1)return Falsereturn fun(s1,s2)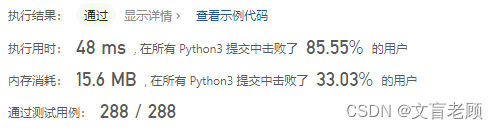
再看头部29ms的答案。。。看不懂了。。。逻辑不太明显,要耐心去读了
88. 合并两个有序数组
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
解释:需要合并 [1,2,3] 和 [2,5,6] 。
合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
解释:需要合并 [1] 和 [] 。
合并结果是 [1] 。
示例 3:
输入:nums1 = [0], m = 0, nums2 = [1], n = 1
输出:[1]
解释:需要合并的数组是 [] 和 [1] 。
合并结果是 [1] 。
注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
进阶:你可以设计实现一个时间复杂度为 O(m + n) 的算法解决此问题吗?
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/merge-sorted-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
没什么好说的,直接合并啊,来个暴力搞笑的
class Solution:def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:"""Do not return anything, modify nums1 in-place instead."""nums1[m:]= nums2nums1.sort()
如果不这么搞,其实也不难,就是需要用一个临时数组,按序列存放结果,最后再返回给 num1,麻烦,不想写了,除非真是考试,有人判卷的那种
class Solution:def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:"""Do not return anything, modify nums1 in-place instead."""#nums1[m:]= nums2#nums1.sort()r = []l = 0p = 0while l < m:if p == n or nums1[l] <= nums2[p]:r.append(nums1[l])l += 1while p < n and nums2[p] <= nums1[l]:r.append(nums2[p])p += 1if p < n:r += nums2[p:n]if l < m:r += nums1[l:m]nums1[:] = r[:m + n]
结果,还是身体很诚实的写了一遍
89. 格雷编码
n 位格雷码序列 是一个由 2n 个整数组成的序列,其中:
每个整数都在范围 [0, 2n - 1] 内(含 0 和 2n - 1)
第一个整数是 0
一个整数在序列中出现 不超过一次
每对 相邻 整数的二进制表示 恰好一位不同 ,且
第一个 和 最后一个 整数的二进制表示 恰好一位不同
给你一个整数 n ,返回任一有效的 n 位格雷码序列 。
示例 1:
输入:n = 2
输出:[0,1,3,2]
解释:
[0,1,3,2] 的二进制表示是 [00,01,11,10] 。
- 00 和 01 有一位不同
- 01 和 11 有一位不同
- 11 和 10 有一位不同
- 10 和 00 有一位不同
[0,2,3,1] 也是一个有效的格雷码序列,其二进制表示是 [00,10,11,01] 。
- 00 和 10 有一位不同
- 10 和 11 有一位不同
- 11 和 01 有一位不同
- 01 和 00 有一位不同
示例 2:
输入:n = 1
输出:[0,1]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/gray-code
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
刚看到这个题目,觉得很简单,不就是 00 01 11 00 吗,然后。。。n = 4 就有点晕了,16个数该怎么排。。。。然后想到了,递归,我直接1的时候给 1 和 0 ,然后2的时候,前边各加一次1,各加一次0,变成 11 10 01 00,嗯。。。顺序不对,那么有一次翻转一下再加就好 11 10 00 01
class Solution:def grayCode(self, n: int) -> List[int]:def fun(n):if n == 1:return ['0','1']r = fun(n - 1)ans = ['0' + v for v in r]ans += ['1' + v for v in r[::-1]]return ansreturn [int(v,2) for v in fun(n)]
嗯,这里全都是用字符串拼出来的,主要是看看返回顺序是否合理,现在,我们把他改成数字的
class Solution:def grayCode(self, n: int) -> List[int]:def fun(n):if n == 1:return [0,1]r = fun(n - 1)ans =r + [v + (1 << (n - 1)) for v in r[::-1]]return ansreturn fun(n)
开始没注意,位移运算优先度居然比加法低, v + 1 << (n - 1) 开始没加括号,得到的结果总是不对。。。晕死
然后,我现在怀疑,用例一共16个,有人直接提交答案。。。。没运算那种,去瞧一眼
一脸怀疑的回来了,大佬的答案如此优秀。。。。我自闭了


是我想多了,递归都可以不要的。。。。
90. 子集 II
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例 1:
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/subsets-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这个没什么好说的了吧,这次你们总不能还用 itertools 了吧
class Solution:def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:ans = []nums.sort()def dfs(dt,arr):ans.append(arr)if len(dt) == 0:returnn = len(dt)pos = 0while pos < n:dfs(dt[pos + 1:],arr + [dt[pos]])pos += 1while pos < n and dt[pos] == dt[pos - 1]:pos += 1if pos >= n:returndfs(nums[:],[])return ans
看了看头部。。。也是传递数组进去,但只传递了一个。。。然后直接用数组添加到答案。。。整体思路没太看明白。。。
小结
下一篇:音频特征提取