【ONE·Data || 栈和队列】
总言
数据结构基础:栈和队列相关模拟实现。
文章目录
- 总言
- 1、栈
- 1.1、初识栈
- 1.2、各接口分模块实现
- 1.2.1、如何创建一个栈?
- 1.2.2、栈的初始化:StackInit
- 1.2.3、栈的销毁:StackDestroy
- 1.2.4、入栈:StackPush
- 1.2.5、出栈:StackPop
- 1.2.6、提取栈顶元素:StackTop
- 1.2.7、判空:StackEmpty
- 1.2.8、获取栈中有效元素个数:StackSize
- 2、队列
- 2.1、初识队列
- 2.2、各接口分模块实现
- 2.2.1、如何创建一个队列?
- 2.2.2、队列初始化:QueueInit
- 2.2.3、队列销毁:QueueDestroy
- 2.2.4、入队:QueuePush
- 2.2.5、出队:QueuePop
- 2.2.6、获取对头元素:QueueFront
- 2.2.7、获取队尾元素:QueueBack
- 2.2.8、判空:QueueEmpty
- 2.2.9、获取队列中有效元素个数:QueueSize
- 2.3、循环队列
- 2.3.1、初识循环队列
- 2.3.2、如何创建一个循环队列:MyCircularQueue
- 2.3.2、循环队列初始化:myCircularQueueCreate
- 2.3.3、循环队列销毁:myCircularQueueFree
- 2.3.4、判空:myCircularQueueIsEmpty
- 2.3.5、判满:myCircularQueueIsFull
- 2.3.6、获取队头元素:myCircularQueueFront
- 2.3.7、获取队尾元素:myCircularQueueRear
- 2.3.4、入队:myCircularQueueEnQueue
- 2.3.5、出队:myCircularQueueDeQueue
- 3、题目补充
1、栈
1.1、初识栈
1)、基本说明
栈: 一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈: 栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈: 栈的删除操作叫做出栈,出数据也在栈顶。
2)、如何实现一个栈?是用基于数组的顺序表形式,还是类似于链表的模式?
回答:栈的实现使用数组或者链表实现都可以,但相对而言数组的结构实现更优一些,因为数组在尾上插入数据的代价比较小,而链表则需要找尾。如果使用链表实现,一个方法是让链表头作为栈顶,使用头插相比于尾插更方便。
1.2、各接口分模块实现
1.2.1、如何创建一个栈?
1)、基本说明
既然我们选择使用数组的模式实现,那么其相关结构与顺序表类似,但需要注意,在栈中,我们有的是栈顶top。
typedef int STDataType;
typedef struct Stack
{STDataType* s;//数组:用于存储栈中元素int top;//记录栈顶:类似于顺序表中的sizeint capacity;//记录容量:
}ST;
上述是创建一个动态的栈,这是相对常用的类型,以下也举例的静态栈的创建:
//静态的栈
#define N 10
typedef int STDataType;
typedef struct Stack
{STDataType a[N];int top;//栈顶int capacity;
}ST;
2)、接口总览
根据需求,在栈中我们所要实现的接口如下:
//初始化栈
void StackInit(ST* ps);//销毁栈
void StackDestroy(ST* ps);//压栈
void StackPush(ST* ps, STDataType val);//出栈
void StackPop(ST* ps);//提取栈顶元素
STDataType StackTop(ST* ps);//判空
bool StackEmpty(ST* ps);//获取栈中元素个数
int StackSize(ST* ps);
1.2.2、栈的初始化:StackInit
1)、基本说明
初始化的方法不唯一,一种是在初始化时先动态申请一定空间,另一种是初始化时什么也不做,在后续插入数据时再来考虑动态开辟问题。此处采用了后者:
//初始化栈
void StackInit(ST* ps)
{assert(ps);//指向栈的指针不能为空,因为后面需要解引用ps->s = NULL;ps->capacity = ps->top = 0;
}
1.2.3、栈的销毁:StackDestroy
1)、基本说明
在销毁栈时,要注意释放我们开辟的动态空间。
//销毁栈
void StackDestroy(ST* ps)
{assert(ps);free(ps->s);ps->s = NULL;ps->capacity = ps->top = 0;
}
1.2.4、入栈:StackPush
1)、基本说明
压栈其含义就是插入数据,因此需要注意容量问题,即扩容检查。
扩容检查中要注意的事项:①此处使用的函数是realloc,其兼容首次开辟和再次开辟两种使用场景。②扩容后要检查是否扩容成功,若成功了则需要修正原先的容量空间以及存储指针。
完成扩容检查后才是数据插入问题,注意需要修正栈顶。
//压栈
void StackPush(ST* ps, STDataType val)
{assert(ps);//容量检查if (ps->capacity == ps->top){int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;STDataType tmp = (STDataType*)realloc(ps->s, newcapacity * sizeof(STDataType));if (tmp == NULL)//检查是否扩容成功{perror("StackPush::malloc");exit(-1);}//扩容成功后:ps->s = tmp;ps->capacity = newcapacity;}//压栈ps->s[ps->top] = val;ps->top++;
}
1.2.5、出栈:StackPop
1)、基本说明
根据栈先进后出的性质,出栈相当于尾删。而实际中并不需要对栈顶数据做处理,直接修改top值即可。但需要注意栈中数据有下限,需要检查有效数据个数,这里使用了StackEmpty。
//出栈
void StackPop(ST* ps)
{assert(ps);assert(!StackEmpty(ps));ps->top--;
}
1.2.6、提取栈顶元素:StackTop
1)、基本说明
这是栈中需要的接口,需要注意提取元素我们使用的是下标,而实际top值记录的是元素个数。
//提取栈顶元素
STDataType StackTop(ST* ps)
{assert(ps);assert(!StackEmpty(ps));return ps->s[ps->top - 1];
}
1.2.7、判空:StackEmpty
1)、基本说明
//判空
bool StackEmpty(ST* ps)
{assert(ps);return ps->top == 0;
}
1.2.8、获取栈中有效元素个数:StackSize
1)、基本说明
//获取栈中元素个数
int StackSize(ST* ps)
{assert(ps);return ps->top;
}
2、队列
2.1、初识队列
1)、基本说明
队列: 只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out) 的特性。
入队列: 进行插入操作的一端称为队尾
出队列: 进行删除操作的一端称为队头
2)、如何实现一个队列?
与栈类似,队列可以用数组实现,也能用链表实现。只是因为其队尾进队头出的特性,出队列相当于需要进行头删,数组头删需要挪动数据,故使用链表的结构实现更优一些。
2.2、各接口分模块实现
2.2.1、如何创建一个队列?
1)、基本说明
如果使用链表来实现队列,需要一个什么样的链表?
虽然带头双向循环链表可实现任意位置处插入删除,此处队列只要求从队头出队(头删),从队尾入队(尾插),故使用单链表即可。不过需要借助一个指向队头的指针和指向队尾的指针。
typedef int QDataType;
typedef struct QueueNode
{QDataType* data;//当前结点用于存储有效数据的变量struct QueueNode* next;//指向下一个结点的指针
}QNode;typedef struct Queue
{QNode* head;//头指针QNode* tail;//尾指针
}Queue;
加入尾指针是为了方便后续入队时,省去找尾环节。要注意理解这里的两层结构体嵌套使用。
2)、接口总览
根据需求,在队列中我们所要实现的接口如下:
//初始化队列
void QueueInit(Queue* pq);//销毁队列
void QueueDestroy(Queue* pq);//入队:尾插
void QueuePush(Queue* pq, QDataType val);//出队:头删
void QueuePop(Queue* pq);//取队头数据
QDataType QueueFront(Queue* pq);//取队尾数据
QDataType QueueBack(Queue* pq);//判空
bool QueueEmpty(Queue* pq);//获取队列有效元素个数
int QueueSize(Queue* pq);
2.2.2、队列初始化:QueueInit
1)、基本说明
//初始化队列
void QueueInit(Queue* pq)
{assett(pq);pq->head = pq->tail = NULL;
}
关于二级指针的说明:在单链表中,我们进行插入删除大多使用的是二级指针,此处为什么只使用一级指针就可以达到效果?
回答:之前我们提到,如果不使用二级指针,一种方法是函数带有返回值,由于空间的动态开辟在堆上,函数销毁后对应空间仍旧在,返回指针是为了找到该动态空间。
此处是另一种解决方案:注意看2.2.1中关于队列的创建,我们使用的pq指针,其类型为Queue*,该结构体成员是指向链表结点QNode*的指针,实际上这样做效果等同于使用二级指针。
typedef struct Queue
{QNode* head;//头指针QNode* tail;//尾指针
}Queue;
2.2.3、队列销毁:QueueDestroy
1)、基本说明
类比于单链表的销毁,需要一个一个遍历结点进行空间释放。
//销毁队列
void QueueDestroy(Queue* pq)
{assert(pq);QNode* cur = pq->head;while (cur){QNode* next = cur->next;free(cur);cur = next;}pq->head = pq->tail = NULL;
}
2.2.4、入队:QueuePush
1)、基本说明
说明:
队列中,数据入队相当于尾插。分为两种情况,其一为链表(队列)为空时,其二为链表(队列)中有结点时。
当链表为空时,对头尾指针tail、head都要进行处理;
当链表中已经存在结点时,head已有确切指向,只需要对tail进行处理(需要注意:每链接一个结点,tail指向需要跟随变动)
//入队:尾插
void QueuePush(Queue* pq, QDataType val)
{assert(pq);//创建新结点QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("QueuePush:malloc");exit(-1);}//处理新结点中的数据newnode->next = NULL;newnode->data = val;//改变链表链接关系:分队列有无数据两情况if (pq->head == pq->tail)//pq->head=NULL pq->tail=NULL{pq->head = pq->tail = newnode;}else{pq->tail->next = newnode;pq->tail = newnode;}
}
关于开辟新结点: 单链表中使用一个BuyListNode函数,是因为相关接口包括头插、尾插、pos位置插入,它们都涉及到新结点开辟,而队列入队只有一种方式,因此动态申请节点不必单独拎出,在入队时直接开辟即可(非强制性要求)。
2.2.5、出队:QueuePop
1)、基本说明
说明: 队列出队,类似于单链表头删,由于结点个数有限,头删有下限值,不能无限删除。此外,为方便寻找头删后的链表头结点,可以先保存下一个结点。若不断进行头删,则最终头指针将指向NULL,而此时尾指针tail指向NULL前的尾结点,该结点已经被free,则存在tail指向为野指针的问题,需要注意考虑。
//出队,头删
void QueuePop(Queue* pq)
{assert(pq);//用于检查函数传参进入的指针是否为空(即它可能不指向链表,而指向NULL)assert(!QueueEmpty(pq));//用于检查链表本身是否为空(即pq指针指向链表,但这是一个空链表)if (pq->head->next == NULL)//链表中只剩一个结点的情况,即链表头指针和尾指针此处重合,该结点next指向NULL{free(pq->head);pq->head = pq->tail = NULL;//此时为了防止tail为野指针,需要将二者置空}else//当链表中存在多个结点时(此处如果使用带哨兵位的头结点时,头删到下限即只剩下哨兵位,则细节有些区别){QNode* next = pq->head->next;//保存头结点后一个结点free(pq->head);//头删pq->head = next;//新的头结点}
}
2.2.6、获取对头元素:QueueFront
1)、基本说明
//取队头数据
QDataType QueueFront(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->head->data;
}
2.2.7、获取队尾元素:QueueBack
1)、基本说明
//取队尾数据
QDataType QueueBack(Queue* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->tail->data;
}
2.2.8、判空:QueueEmpty
1)、基本说明
//判空
bool QueueEmpty(Queue* pq)
{assert(pq);return pq->head == NULL;
}
2.2.9、获取队列中有效元素个数:QueueSize
1)、基本说明
//获取队列有效元素个数
int QueueSize(Queue* pq)
{assert(pq);QNode* cur = pq->head;int count = 0;while (cur){count++;cur = cur->next;}return count;
}
2.3、循环队列
2.3.1、初识循环队列
该部分内容基于此题进行循环队列的学习,相关链接:题源

1)、关于循环队列的介绍
根据题目描述: 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。
注意事项: 题目描述普通队列数据满后就不能插入,但循环队列可以重复利用空间。这里告诉我们题目要求的是静态队列,后续MyCircularQueue(k): 构造器,设置队列长度为 k 。这里也提醒我们队列有具体长度限制。
如何设计一个静态的循环队列?
这里我们给定一个队头和队尾,能做到如下效果:插入数据,变动队尾tail所在位置,删除数据,变动队头head所在位置。
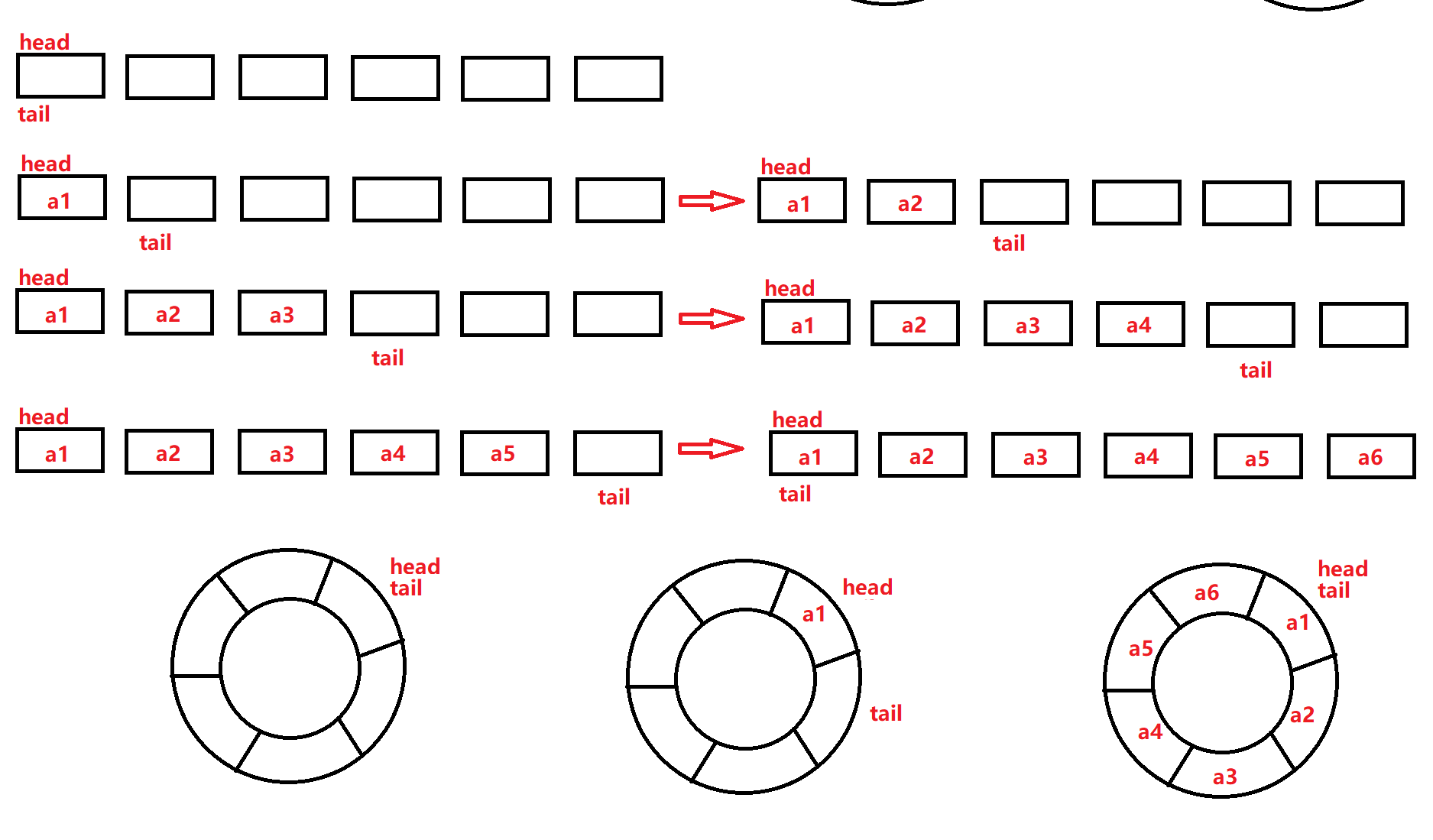
如何判断静态队列中元素已满?
如图所示,在循环队列中入队和出队有如下情况:插入数据,变动队尾tail所在位置,删除数据,变动队头head所在位置。
当 head==tail 时,一圈结束,但这不能作为队列元素插满的依据。因为此时可能出现的情况为二:其一是当队列都为空时,其二是当队列数据存满时。
上述问题有无解决方案?
一种方案是:增加一个size变量,用于计数队列有效元素,当size==k(元素个数等于队列长度),则队列已满。
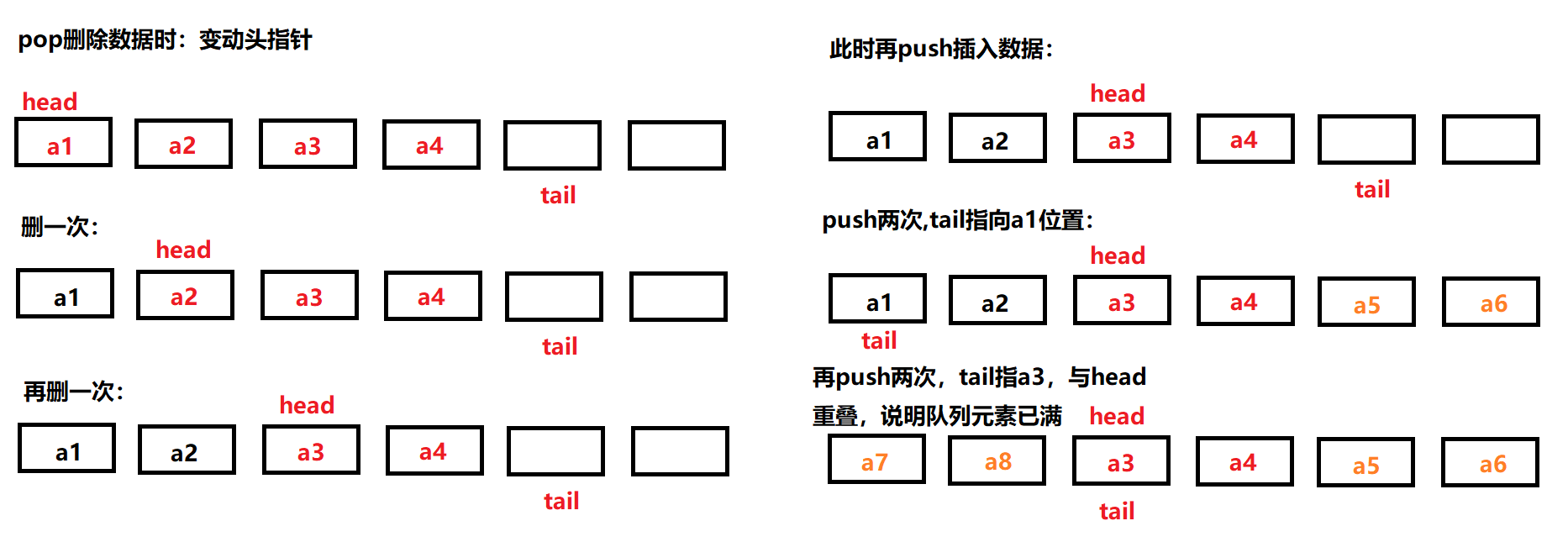
另一个解决方案是:在队列中空出一个位置,作为预留结点,不存储有效数据,通过tail -> next ==head来判断队列是否已经存满,这样就可以与空队列的情况区分开。
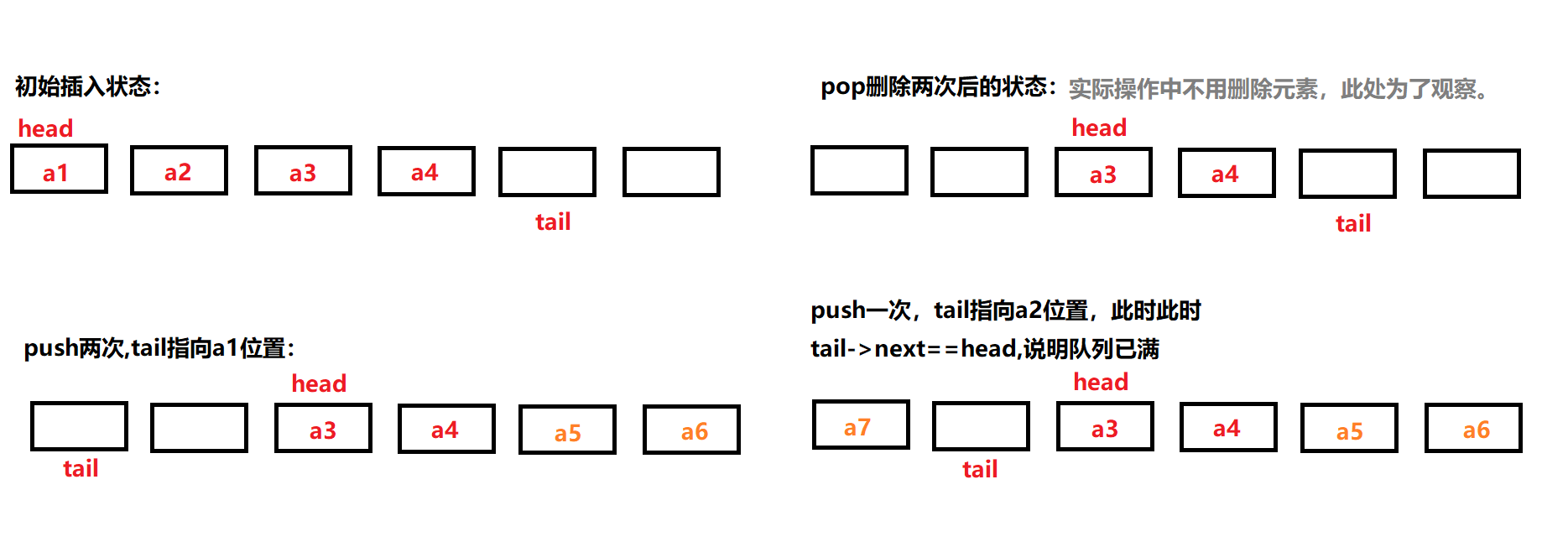
使用什么样的结构来创建循环队列?数组?链表?
若使用链表,初始时tail==head,之后不断插入数据,tail实际指向为尾结点的下一个。这会带来一个问题,获取队尾数据时,我们需要遍历链表找尾结点。
若使用数组,tail、head为数组下标,获取队尾数据只需要tail-1即可,且入队、出队也方便。但同时会引出新问题,数组长度为K,插入删除数据存在越界情况。且链表达成循环是浑然天成的,因为依托于next指针指向关系,而数组的连续性使得它要达成循环要做一定的处理,例如:使用余数、手动复位等。
接下来分布说明各接口实现:
2.3.2、如何创建一个循环队列:MyCircularQueue
1)、基本说明
如下,根据2.3.1中内容,我们选择使用数组的方式创建此处的循环队列,需要注意队列中所具有的成员。
typedef struct {int *a;//数组int head;//队头,此处为下标int tail;//队尾,此处为下标int k;//队列长度K
} MyCircularQueue;
2.3.2、循环队列初始化:myCircularQueueCreate
MyCircularQueue* myCircularQueueCreate(int k)
1)、基本说明
根据函数提供接口,此处要动态申请一个长度为K的静态队列,并将申请后的队列返回。
代码如下:
MyCircularQueue* myCircularQueueCreate(int k) {MyCircularQueue* obj=(MyCircularQueue*)malloc(sizeof(MyCircularQueue));assert(obj);obj->a=(int*)malloc(sizeof(int)*(k+1));assert(obj->a);obj->tail=obj->head=0;obj->k=k;return obj;
}
虽然出了函数后,obj变量会销毁,但申请出来的空间仍旧保存,并被我们的实参接受到。
此外,还需要对队列中的相关数据进行初始化处理,比如对存储数据的数组a进行动态开辟,对表示长度的k进行赋值等。
2.3.3、循环队列销毁:myCircularQueueFree
void myCircularQueueFree(MyCircularQueue* obj)
1)、基本说明
队列销毁,注意释放动态申请的空间即可,此处内外开辟了两次空间,因此释放时需要注意顺序,避免造成内存泄露:
void myCircularQueueFree(MyCircularQueue* obj) {assert(obj);free(obj->a);free(obj);obj=NULL;//此步可略去
}
2.3.4、判空:myCircularQueueIsEmpty
bool myCircularQueueIsEmpty(MyCircularQueue* obj)
1)、基本说明
队列为空有两种情况,其一是创建队列无任何元素时,其二是不断出队直到队列中无任何元素,这时head==tail:
bool myCircularQueueIsEmpty(MyCircularQueue* obj) {assert(obj);return obj->tail==obj->head;
}
2.3.5、判满:myCircularQueueIsFull
bool myCircularQueueIsFull(MyCircularQueue* obj)
1)、基本说明
数值是否为满有两种情况:
常规下,由于存在一个预留结点,若tail+1==head,则说明已满。
特别的,当head指向数组头部(下标最小值),tail指向数组尾部(下标最大值),此时tail指向的位置作为预留结点不能插入数据。且该情况下,作为循环队列它也满足tail+1==head表示队列已满的条件。
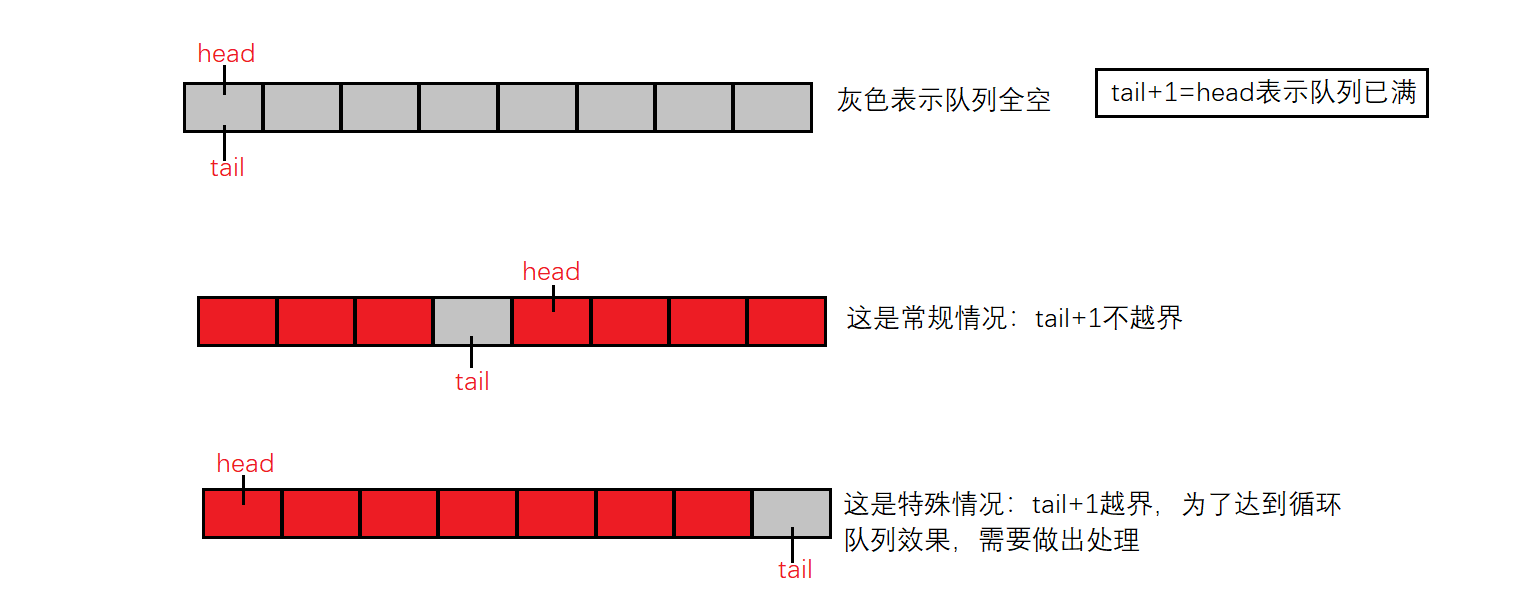
PS:要注意tail指向的是下一次插入数据的位置。即再次插入数据时需要在tail下标处插入。
bool myCircularQueueIsFull(MyCircularQueue* obj) {assert(obj);int next=obj->tail+1;//记录下标为tail+1的位置,即tail的下一个if(next==obj->k+1)//若越界,则做重置处理next=0;return next==obj->head;
}
2.3.6、获取队头元素:myCircularQueueFront
Front: 从队首获取元素。如果队列为空,返回 -1 。
int myCircularQueueFront(MyCircularQueue* obj)
1)、基本说明
注意题目条件,这里队列为空时要返回对应值。
int myCircularQueueFront(MyCircularQueue* obj) {assert(obj);if(myCircularQueueIsEmpty(obj)){return -1;}return obj->a[obj->head];
}
2.3.7、获取队尾元素:myCircularQueueRear
Rear: 获取队尾元素。如果队列为空,返回 -1 。
int myCircularQueueRear(MyCircularQueue* obj)
1)、基本说明
事项说明:
1、同取队头元素,需要注意题目返回值条件;
2、此处tail并非指向队尾,而是队尾后一个元素,因此队尾为tail-1,但是需要注意特殊情况:当tail指向数组下标为0的位置时,tail-1在数值上为负,数组越界。但对于循环队列来说,tail-1应该指向下标为k的数组位置,故需要做处理。
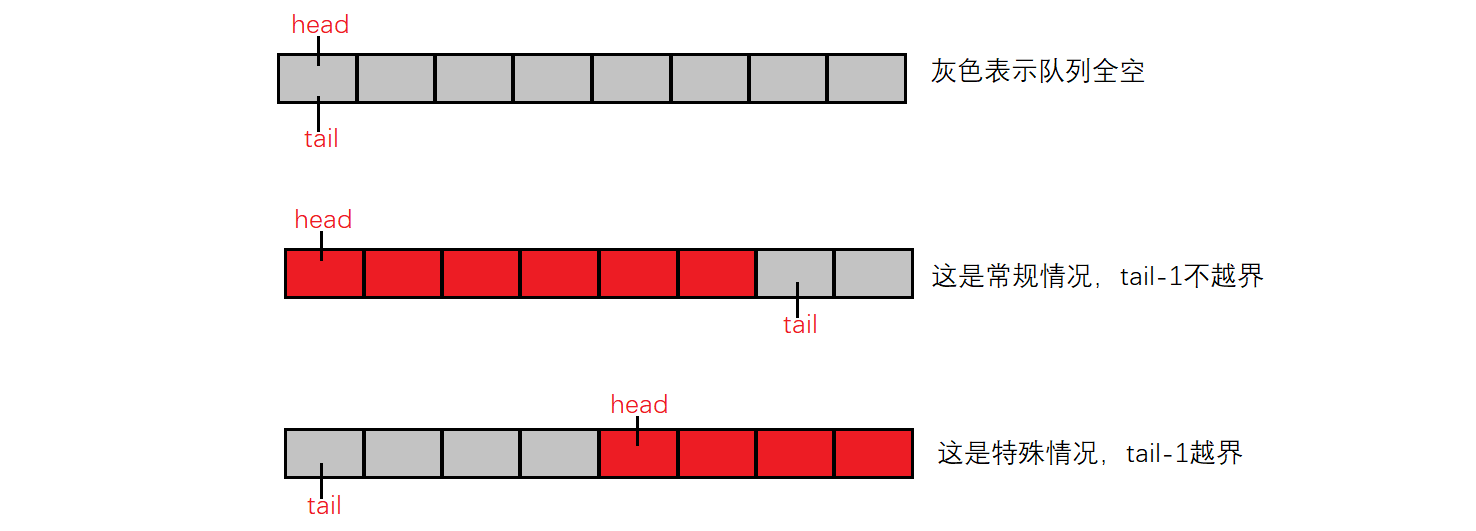
int myCircularQueueRear(MyCircularQueue* obj) {assert(obj);if(myCircularQueueIsEmpty(obj)){return -1;}int prev=obj->tail-1;if(prev<0)//obj->tail==0{prev=obj->k;}return obj->a[prev];
}
2.3.4、入队:myCircularQueueEnQueue
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value)
1)、基本说明
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value) {//入队,需要处理数组满时和数组边界问题(对tail的处理)if(myCircularQueueIsFull(obj)){return false;//数组满时,插入失败,根据题目要求返回false}//插入数据:obj->a[obj->tail]=value;//处理tail指向:此处顺序不能颠倒,要先让tail自增,再来判断其是否越界obj->tail++;if(obj->tail==(obj->k+1))//设k=3,实际开辟为4个,数组下标最大值为3,此处越界为k+1=4(tail、head实际指向为数组下标){obj->tail=0;}return true;
}
2.3.5、出队:myCircularQueueDeQueue
deQueue(): 从循环队列中删除一个元素。如果成功删除则返回真。
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value)
1)、基本说明
删除数组元素,根据队列的性质为头删,因此我们只需要改变head下标即可,对实际数据可不做处理,后续若插入直接覆盖即可。
bool myCircularQueueDeQueue(MyCircularQueue* obj) {//数组为空时,删除失败,根据题目要求返回falseif(myCircularQueueIsEmpty(obj)){return false;}//和tail一致需要检查越界问题,此处顺序不可调动obj->head++;if(obj->head==obj->k+1)obj->head=0;return true;
}
3、题目补充
关于栈和队列涉及的相关题目见其它博文:单链表、栈和队列部分习题