大数据体系知识学习(二):WordCount案例实现及错误总结
创始人
2025-05-30 11:54:02
0次
文章目录
- 1. 当前环境
- 2. 相关信息
- 2.1 相关文件
- 2.2 相关流程
- 3. 运行代码
- 4. 运行结果
- 5. 运行错误情况
- 5.1 py4j.protocol.Py4JJavaError
- 5.2 JAVA_HOME is not set
1. 当前环境
pyspark:版本号为3.1.2
JAVA_JDK: 版本号为1.8.0_333
Hadoop: 版本号为3.3.0
2. 相关信息
2.1 相关文件
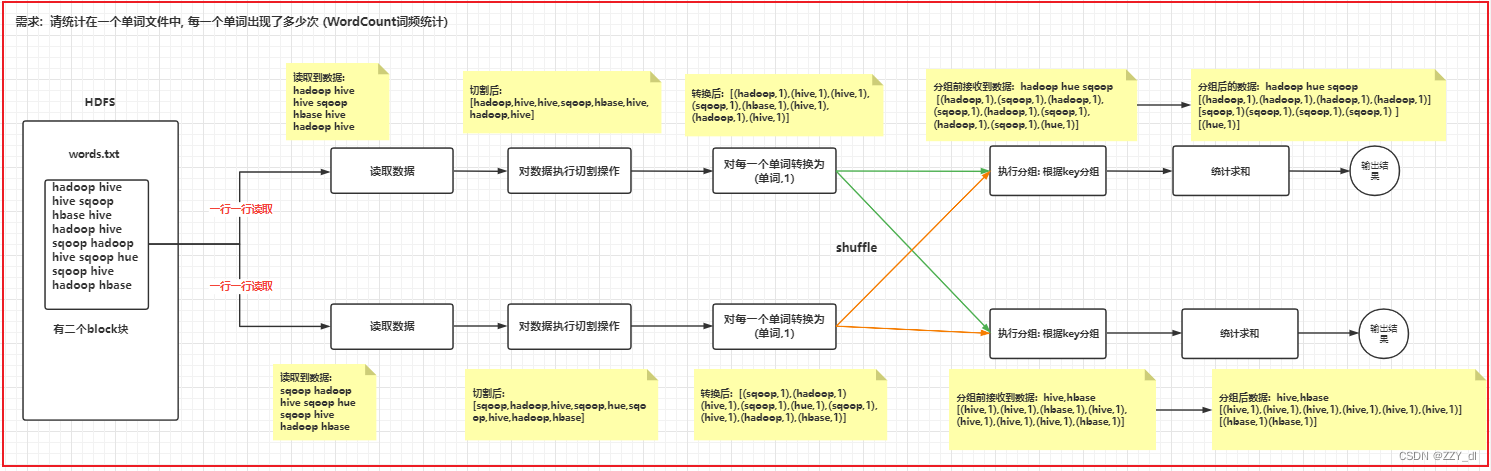
words.txt如下
hello world hello hadoop
hadoop hello world hive
hive hive hadoop
2.2 相关流程
3. 运行代码
# spark入门案例 --- WordCountfrom pyspark import SparkContext,SparkConf
import findspark
findspark.init()if __name__ == '__main__':print("spark入门案例 --- WordCount")# 1) 创建 sparkContext对象conf = SparkConf().setMaster("local[*]").setAppName("WordCount")# 自动返回 变量: ctrl +atl + vsc = SparkContext(conf=conf)# 2) 读取文件数据 file是调用本地文件rdd_init = sc.textFile("file:///F:\python\学习\Spark/file/words.txt")# 3) 对数据执行切割操作: 得到 ['hello', 'world', 'hello', 'hadoop', 'hadoop', 'hello', 'world', 'hive', 'hive', 'hive', 'hadoop']rdd_flatMap = rdd_init.flatMap(lambda line:line.split(' ')) # 一个对多个flatMap# 4) 对数据转换为 单词,1 操作# [('hello', 1), ('world', 1), ('hello', 1), ('hadoop', 1), ('hadoop', 1), ('hello', 1), ('world', 1), ('hive', 1), ('hive', 1), ('hive', 1), ('hadoop', 1)]rdd_map = rdd_flatMap.map(lambda word: (word,1)) # 一个对一个 map# 5,6) 对数据执行分组操作 统计求和操作 groupByKey是指根据key完成自动分组 reduceByKey是指根据key来做聚合# 从Shuffle的角度:# groupByKey和reduceByKey都存在shuffle的操作,但是reduceByKey可以在shuffle之前对分区内相同key的数据集进行预聚合# (combine),这样会减少落盘的数据量,而groupByKey只是进行分组,不存在数据量减少的问题,reduceByKey性能比较高。# 从功能的角度:# reduceByKey其实包含分组和聚合的功能;groupByKey只能分组,不能聚合,所以在分组聚合的场合下,# 推荐使用reduceByKey,如果仅仅是分组而不需要聚合,那么还是只能使用groupByKey。rdd_res = rdd_map.reduceByKey(lambda agg, curr: agg + curr)# 7) 输出: 打印print(rdd_res.collect())# 8) 关闭 sparkContext对象sc.stop()
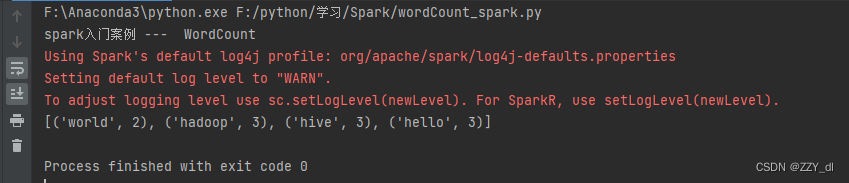
4. 运行结果
5. 运行错误情况
5.1 py4j.protocol.Py4JJavaError
错误截图
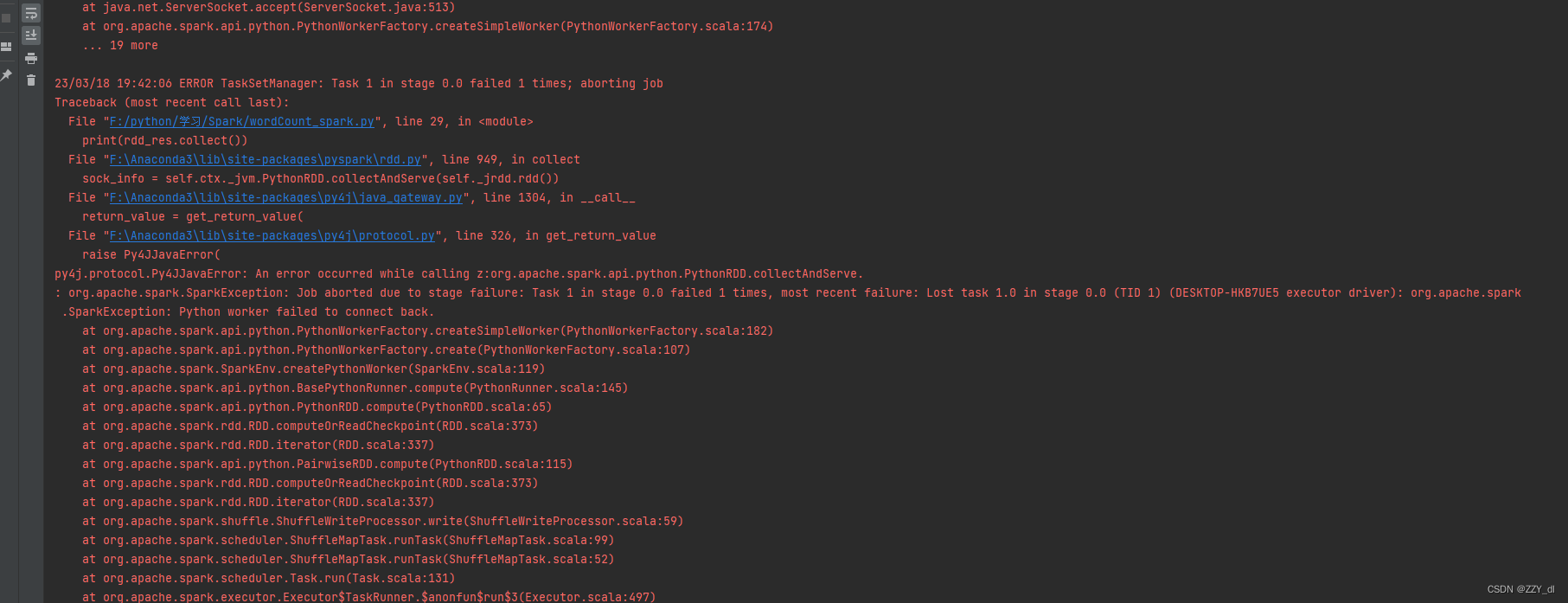
错误原因
因为转载时间过长找不到spark所以报错
解决办法
import findspark
findspark.init()
5.2 JAVA_HOME is not set
出现位置: 当pycharm采用SSH连接远程Python环境时, 启动执行spark程序可能报出原因: 加载不到jdk的位置
解决方案:
- 第一步: 可以在linux的 /root/.bashrc 文件中, 添加以下两行内容 (注意需要三台都添加)
export JAVA_HOME=/export/server/jdk1.8.0_241
export PYSPARK_PYTHON=/root/anaconda3/bin/python
- 第二步: 在代码中, 指定linux中spark所在目录, spark中配置文件, 即可自动加载到: 锁定远端操作环境, 避免存在多个版本环境的问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ["PYSPARK_PYTHON"]="/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"]="/root/anaconda3/bin/python"
相关内容
热门资讯
前端-session、jwt
目录: (1)session (2&#x...
linux入门---制作进度条
了解缓冲区 我们首先来看看下面的操作: 我们首先创建了一个文件并在这个文件里面添加了...
关于测试,我发现了哪些新大陆
关于测试 平常也只是听说过一些关于测试的术语,但并没有使用过测试工具。偶然看到编程老师...
前缀和与对数器与二分法
1. 前缀和 假设有一个数组,我们想大量频繁的去访问L到R这个区间的和,...
nodejs:本地安装nvm实...
一、背景-使用不同版本node的原因 vue3+ts、nuxt3版本,node...
JAVA集合知识整理
Java集合知识整理 HashMap相关 HashMap的底层数据结构:jdk1.8之...
无刷直流电机介绍及单片机控制实...
无刷直流电机介绍及单片机控制实例前言基本概念优势与劣势使用寿命基本结构使用单片机控制实例电子调速器&...
fwdiary(2) dp2
1.传纸条 AcWing 275. 传纸条 - AcWing 走两条路,走一条最大的...
常用的DOS命令
常用的DOS命令 DOS(Disk Operating System,磁...
<C++> 类和对象(下)
1.const成员函数将const修饰的“成员函数”称之为const成员函数,cons...