Hadoop环境搭建
一.模板虚拟机hadoop100配置如下(本文Linux系统以centos7及以上为准)
(1)使用yum安装需要虚拟机可以正常上网,yum安装前可以先测试下虚拟机联网情况:
ping www.baidu.com
(2)安装epel-release
Extra Packages for Enterprise Linux是为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux。
yum install -y epel-release
注意:如果Linux安装的是最小系统版,还需要安装如下工具;如果安装的是Linux桌面标准版,不需要执行如下操作
yum install -y net-tools (工具包集合)
yum install -y vim(编辑器)

(2)关闭防火墙,关闭防火墙开机自启
systemctl disable firewalld.service

3)创建admin用户,并修改admin用户的密码:
useradd admin
passwd admin

修改克隆ip地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
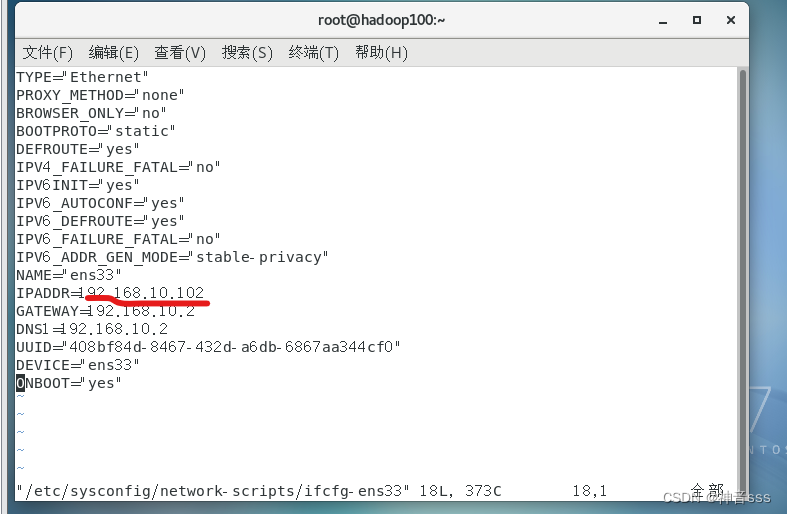
自由修改
查看主机名称
vim /etc/hostname
配置好xshell
连接好XFTPS,并传输文件
文件已经传输完成

开始安装JDK
之前现实权限不够,安装失败,所以第二次我加了sudo强制安装
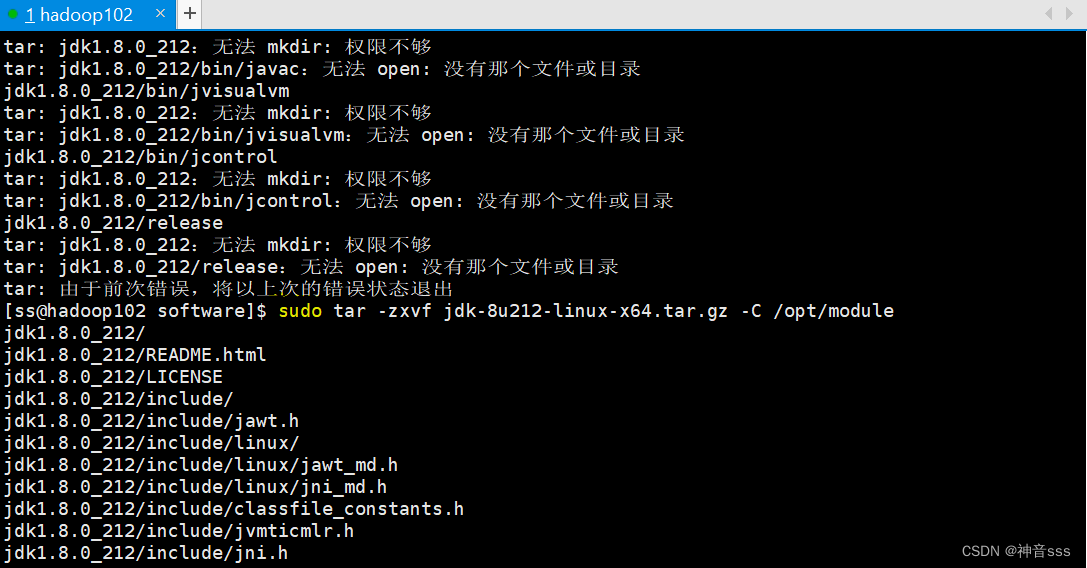
加了sudo 之后显示安装成功

进入根目录
来到这个目录下找到jdk

然后进入jdk
jdk能不能用,主要是看配置的环境变量

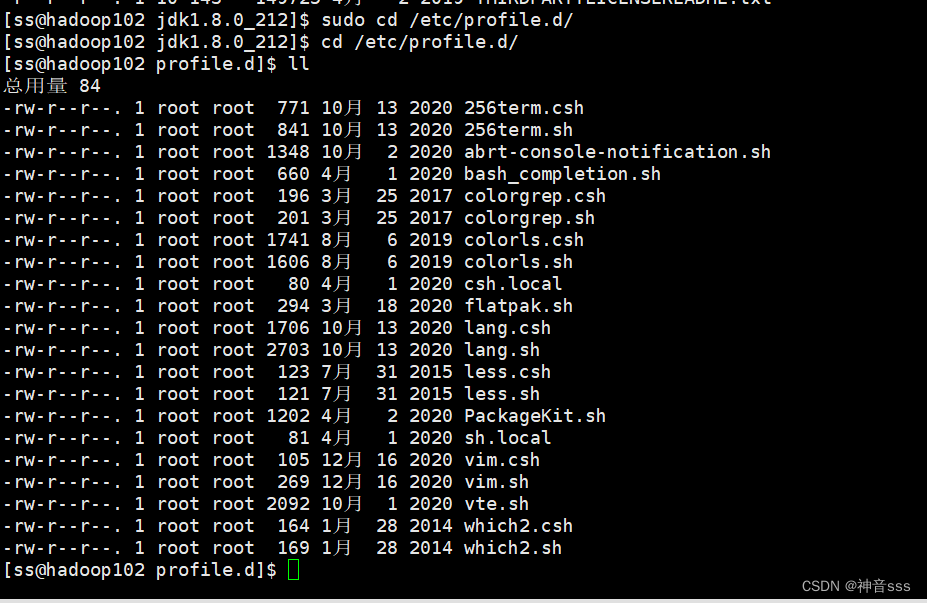
然后自己创建一个文件
井号表示注释
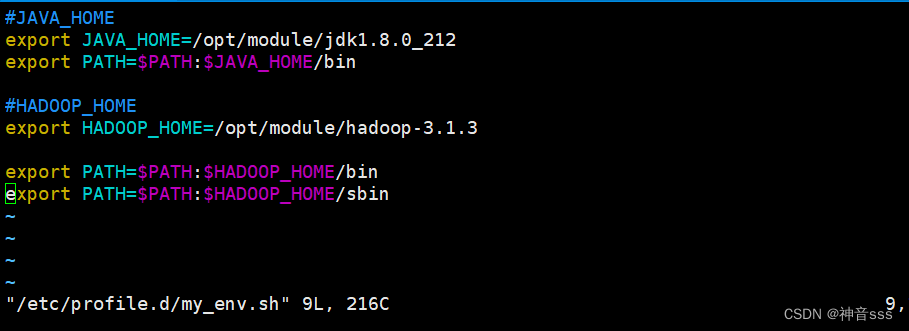
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
export 表示全局配置
source一下/etc/profile文件,让新的环境变量PATH生效
source /etc/profile

输入java
测试一下,是否安装成功
java -version

来到这,准备安装hadoop

安装成功
同样source一下之后输入hadoop
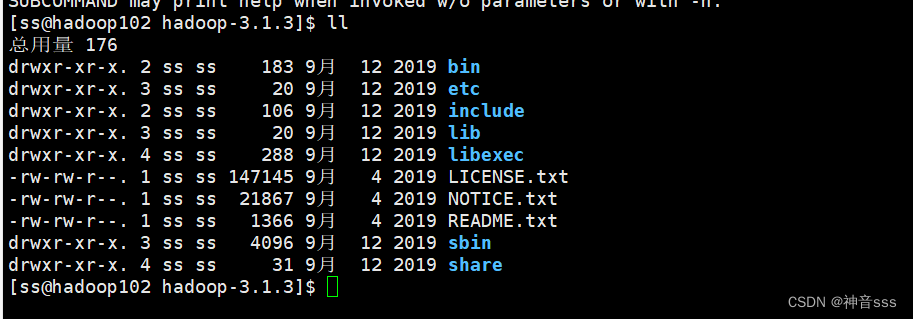
2)重要目录
(1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
Hadoop运行模式
Hadoop运行模式包括:
本地模式、伪分布式模式以及完全分布式模式。
本地模式:单机运行。
伪分布式模式:也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。
完全分布式模式:多台服务器组成分布式环境。
点绿色的Getting started
执行命令时。输出路径是不能存在的,不然会报错
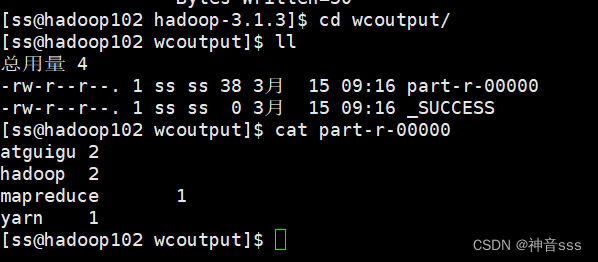
查看数据 cat
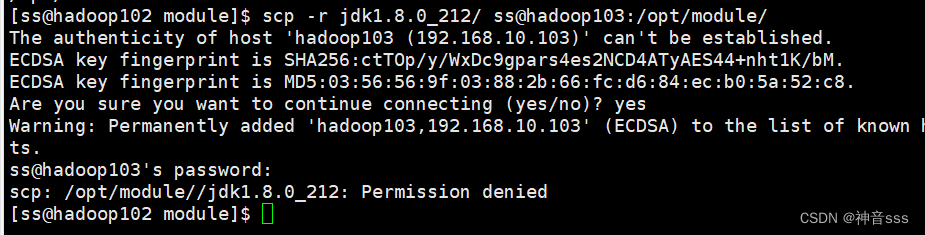
将102的Hadoop和jdk拷贝到103
(1)scp定义
scp可以实现服务器与服务器之间的数据拷贝。
(2)基本语法
scp -r pdir/pdir/pdir/fname user@user@user@host:pdir/pdir/pdir/fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
eg:
scp -r /opt/module/jdk1.8.0_212 atguigu@hadoop103:/opt/module
可能出现权限不够的情况,两边都需要用root(之前明明赋权了,上次开机就可以用,不知为什么这次不行,没懂)
scp -r root@hadoop102:/opt/module/jdk1.8.0_212/ root@hadoop103:/opt/module
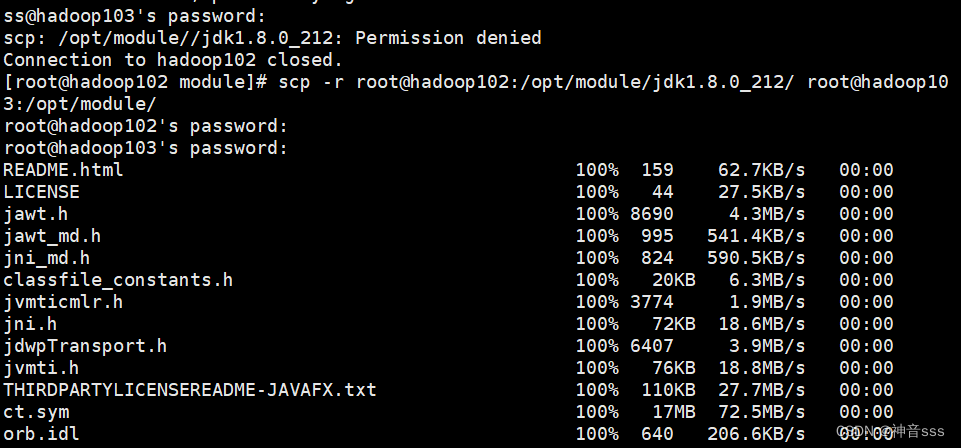
带*可以把目录下的文件都拷过来,在103上把102的文件拷贝到104

查看104
rsync第一次同步等同于拷贝,第二次及以后只改变变化数据
(1)基本语法
rsync -av pdir/pdir/pdir/fname user@user@user@host:pdir/pdir/pdir/fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
选项参数说明:
-a:归档拷贝
-v:显示复制过程
两个文件同时删掉
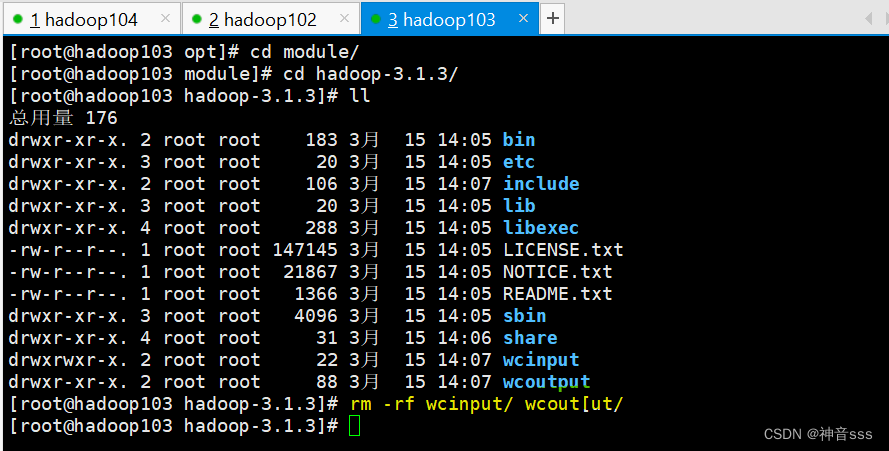
编写集群分发脚本xsync
xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /opt/module admin@hadoop103:/opt/
把原始数据同步分发到指定相同的路径上

配置全局环境变量


创建软连接
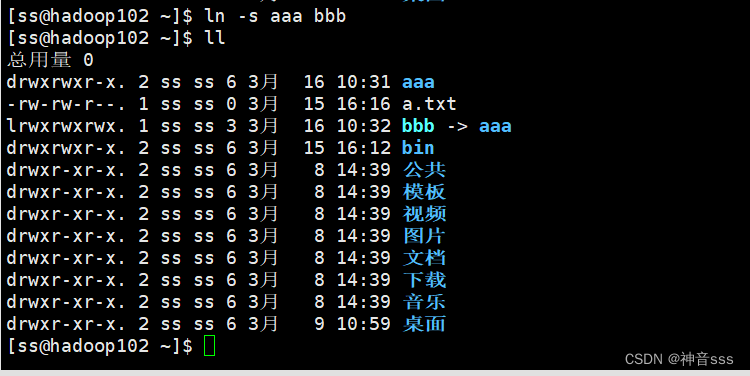
从103退回到102 exit
创建vim

在该文件中编写如下代码:
#!/bin/bash#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ==================== $host ====================

进行同步
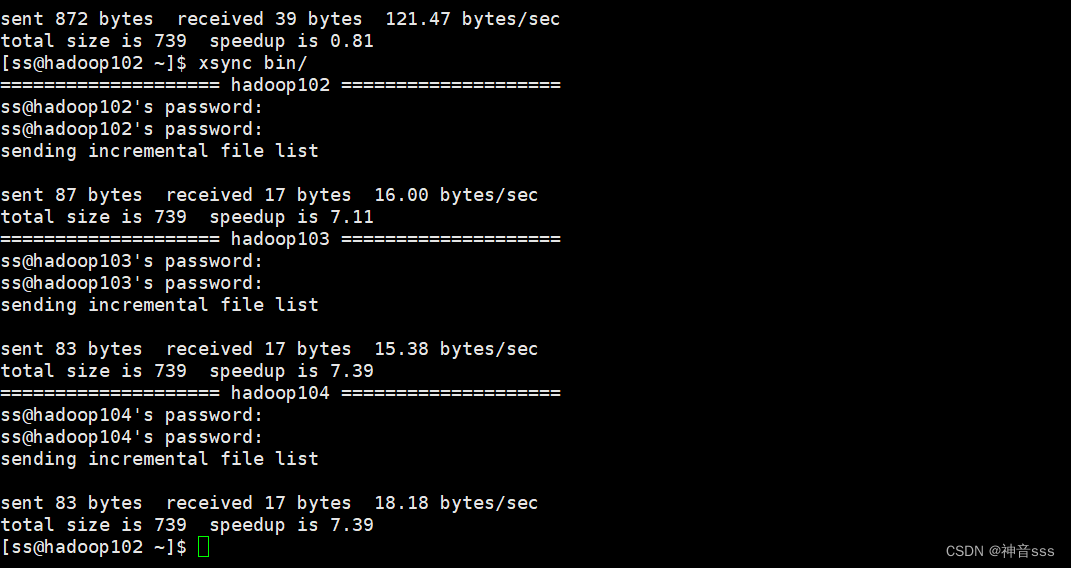
xsync bin/
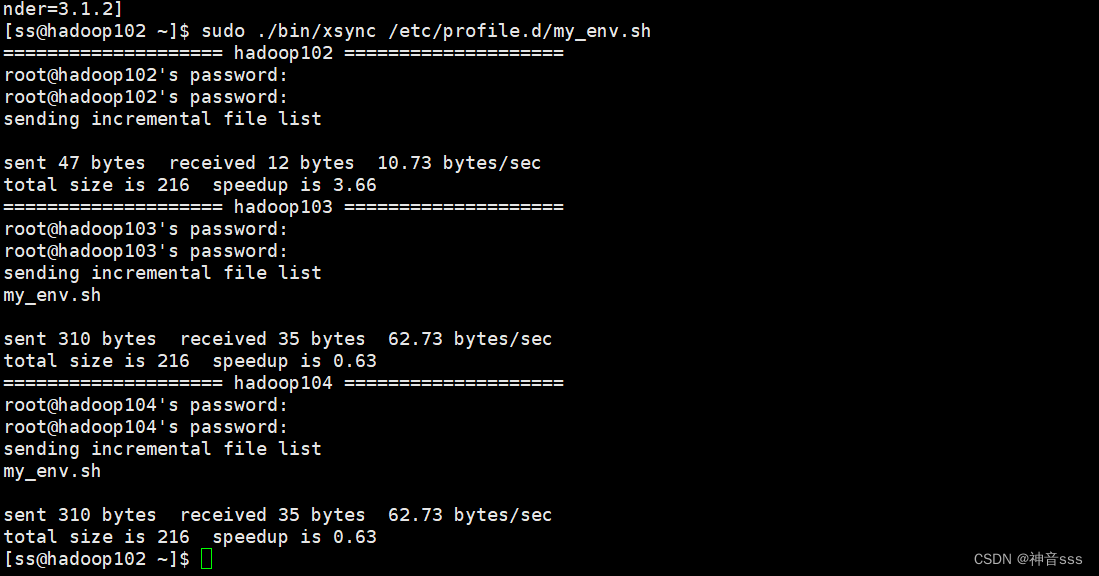
分发环境变量,但显示权限拒绝了
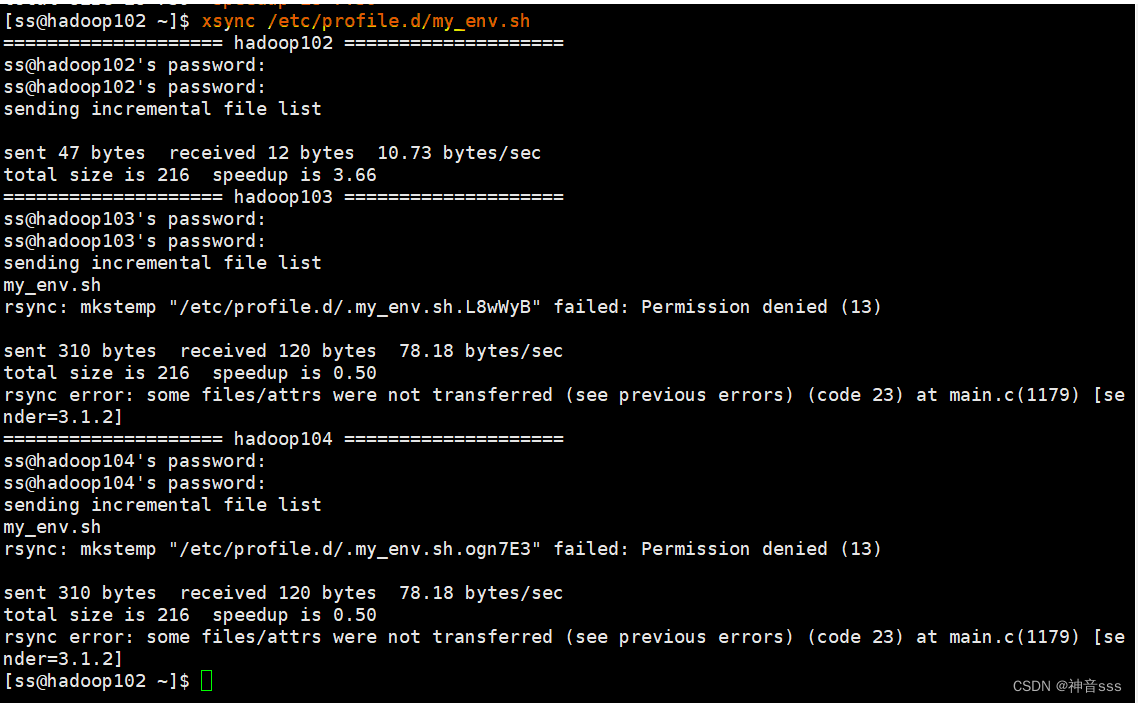
直接加sudo ,会显示找不到系统命令,因为root用户在家目录下的那些目录内,root使用不了这个路径,所以应该在前面加上 ./bin
sudo ./bin/xsync /etc/profile.d/my_env.sh
ssh免密登录,需要在自己的服务器上创建一堆密钥
上一篇:粒子群算法优化策略总结
下一篇:Spring的数据库编程