lattice regression: 求解查找表
文章目录
- lattice regression
- 1.Monotonic Calibrated Interpolated Look-Up Tables
- 1.1 单调性的约束
- 1.2. 快速多维线性插值 和 单纯形插值法
- 1.3. 鼓励线性的正则化函数
- 2.lattice regression各种正则化的效果差异
- 2.1 生成二维曲面示例:
- 2.2 graph laplacian regularizer
- 2.3 graph hessian regularizer
- 2.4 torsion regularizer
- 2.5 单调性约束
- 3.Nonuniform Lattice Regression for Modeling the Camera Imaging Pipeline
- 3.1. 模块所处的位置
- 3.2. 构建lattice model
- 3.3 由于色域的变化并不是均匀的,因此采用non-uniform的lattice 会不会更好?
- 3.4. 重新求解lattice regression
- 3.5. 实验
lattice regression
1.Monotonic Calibrated Interpolated Look-Up Tables
Fast and Flexible Monotonic Functions with
Ensembles of Lattices
两篇论文都比较偏理论,涉及数学和比较早的论文引用,有些细节不是很容易懂。
1.1 单调性的约束

A 的每一行都是 1,-1, 1,-1.。。
1.2. 快速多维线性插值 和 单纯形插值法
Fast Multilinear Interpolation
Simplex Linear Interpolation
两个快速插值的方法
1.3. 鼓励线性的正则化函数

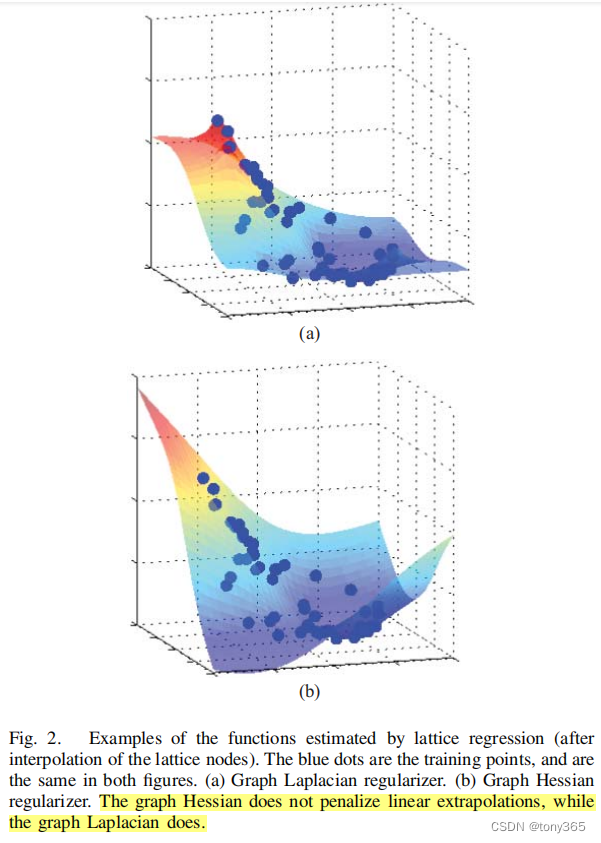
在lattice regression 相关论文中又介绍 graph laplacian 正则化 和 graph hessian正则化。
graph laplacian 正则化 是约束相邻的node, 因此向外推断时,趋势会比较平坦。
graph hessian正则化是 约束相邻的node的 差分,因此向外推断时,趋势会保持内部的变化趋势。

2.lattice regression各种正则化的效果差异
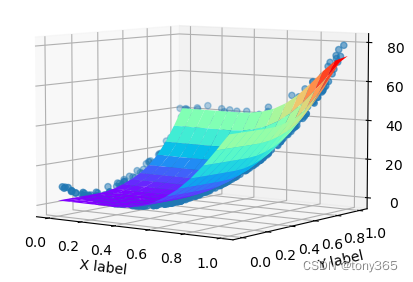
2.1 生成二维曲面示例:
生成二维曲面 lattice regression论文中的示例
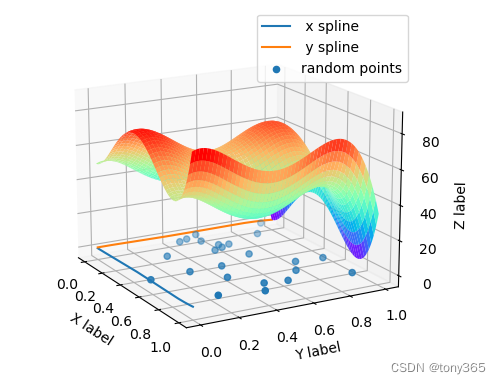
2.2 graph laplacian regularizer
在边缘趋向于平坦,维持值不变的
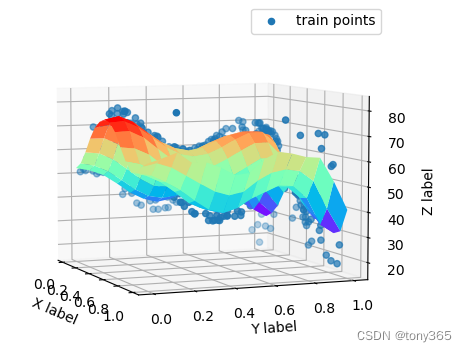
2.3 graph hessian regularizer
相比于 laplacian regualr, graph hessian regularizer不会压抑 线性,会保持线性
import numpy as npdef get_K(x, dim):s = 0for i in range(dim):for j in range(dim):p = i * dim + jif (j > 0) and (j < dim-1):s += (x[p-1] + x[p+1] - 2*x[p])**2if (i > 0) and (i < dim - 1):s += (x[p-dim] + x[p+dim] - 2*x[p])**2return s / (dim**2)
def get_K2(x, dim):x = x.reshape(dim, dim)dd = dim - 2x1 = x[0:dd, 0:dim]x2 = x[2:dd+2, 0:dim]x3 = x[:, 0:dd]x4 = x[:, 2:dd+2]x12 = x[1:dd+1, 0:dim]x34 = x[:, 1:dd+1]a = (x1 + x2 - 2 * x12) ** 2b = (x3 + x4 - 2 * x34) ** 2return (np.sum(a) + np.sum(b))/ (dim**2)'''验证get_K 和 get_K2等价'''
if __name__ == "__main__":d = 32xxx = np.random.randint(0, 9, (d,d))print(xxx)xxx = xxx.reshape(-1)a = get_K(xxx, d)print(a)b = get_K2(xxx, d)print(b)
在边缘会保持梯度,维持梯度趋势不变
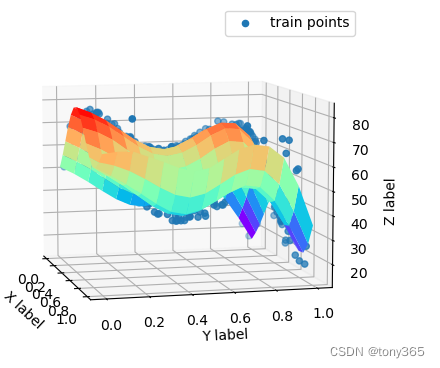
2.4 torsion regularizer
使每个grid保持线性化, 每个grid趋向与 维持 平行四边形,而不是梯形。
2.5 单调性约束
根据两条曲线生成二维曲面
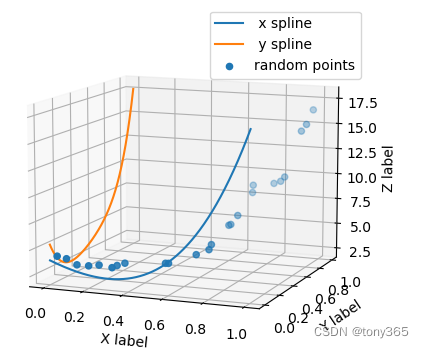
ground truth:
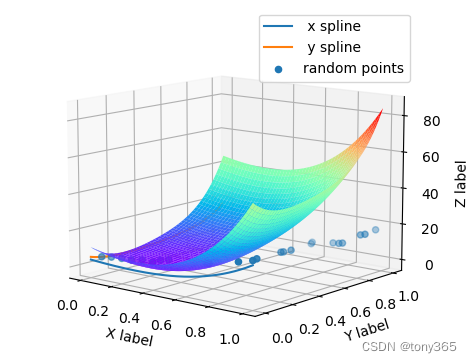
不加单调性正则化:
def mono_reg(x, dim):x = x.reshape(dim, dim)d = 6delta1 = x[1:6, :] - x[0:5, :] # r, c = dim-1, dim > 0delta2 = x[:, 1:6] - x[:, 0:5] # r, c = dim, dim-1 > 0delta3 = -delta1delta4 = -delta2s = np.mean(np.maximum(0, delta3)**2) + np.mean(np.maximum(0, delta4)**2)return sL = get_L(dim)def mini_fun(x, W, b, n, lamda):x = x.reshape(-1, 1)aa = (W @ x - b) ** 2 / n#bb = get_torsion(x, dim)bb1 = x.T @ L @ xbb = get_K2(x, dim)cc = mono_reg(x, dim)return np.sum(aa) + lamda*np.sum(bb) + 0*np.sum(cc)
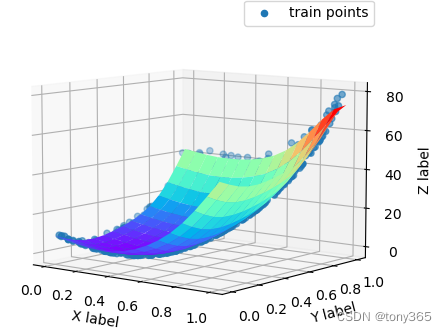
加入单调性约束图像效果,在左下角可以看出。
修改上面code最后一行
return np.sum(aa) + lamda*np.sum(bb) + 20*np.sum(cc)
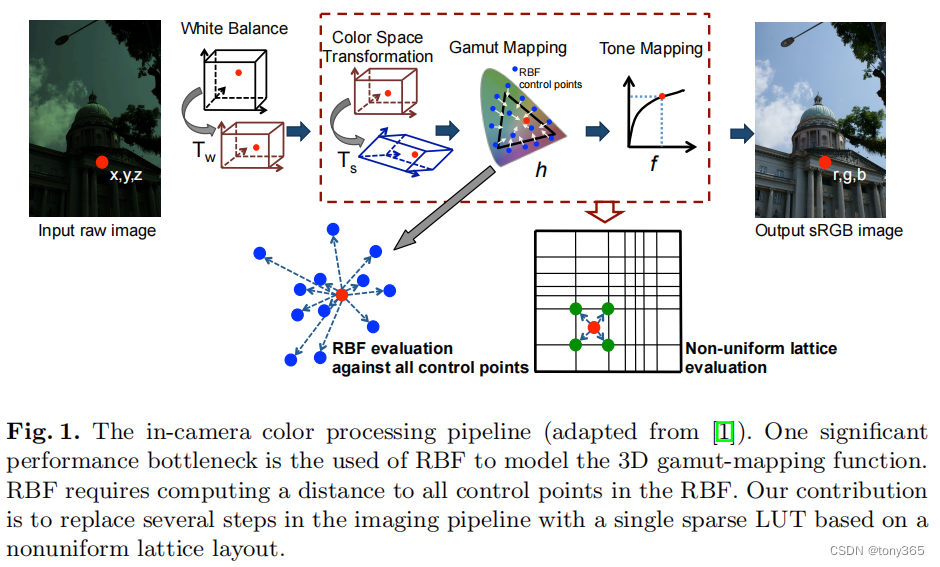
3.Nonuniform Lattice Regression for Modeling the Camera Imaging Pipeline
利用nonuniform lattice regression 进行颜色映射。
3.1. 模块所处的位置
代替ccm和gamma,tone mapping模块
3.2. 构建lattice model
输入 r1,g1,b1 输出 r2,g2,b2
可以先考虑输出一个channel: 输入r1,g1,b1 输出r2 channel.
N 是 每一行的 网格数目,比如 N = 17
m = N^3, 我们要求的是一个查找表,比如r2的数目是 m
损失函数如下:
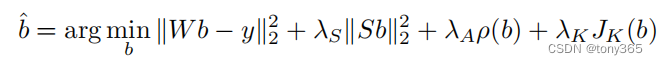
Wb - y 就是 插值 最小化,不必多说, W是 n行(训练样本数目),m 列的矩阵
Sb是导数平滑项。 比如 a2-0.5a1 + 0.5a3, 那么可以得到一个 N∗N∗(N−2)∗3N*N*(N-2)*3N∗N∗(N−2)∗3行, m列的矩阵。
ρ(b)\rho(b)ρ(b) 是约束边缘的项,因为训练数据分布步会是均匀的,想象在3Dlut中饱和度很大的点训练集中可能不会太多或者缺失,这个时候需要对 3Dlut的边缘位置(像素值达到1的点,想象一个立方体除了与(0,0,0)接触的3条边,剩余9条边,使原来是1的现在仍保持1)
原来是0,0,0的仍然保持0,0,0
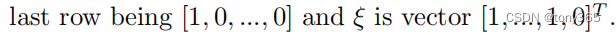
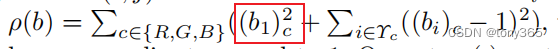
因此ρ(b)\rho(b)ρ(b) 是一个 xxx行 m列的矩阵,xxx的数目我也没计算。
最终目标函数的解为:
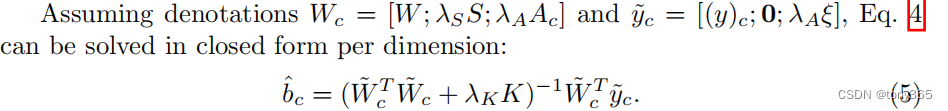
这里lattice regression的构建和之前有些不同就是 把一些约束合并在矩阵里面。其实含义是一样的。
3.3 由于色域的变化并不是均匀的,因此采用non-uniform的lattice 会不会更好?
作者就是通过一个 transformation 将 uniform变为 non-uniform 3D lut.
就是原来的线性映射到每个node, 改为非线性。
比如原来的一条边 1-255分别对应 3Dlut的 1-255,就是均匀的。
现在要设计一个转换关系,转变为非均匀,像素值为10可能不对应3Dlut的第10格。
这样其实是求一个转换关系,类似于 直方图规定化的一个 查找表。
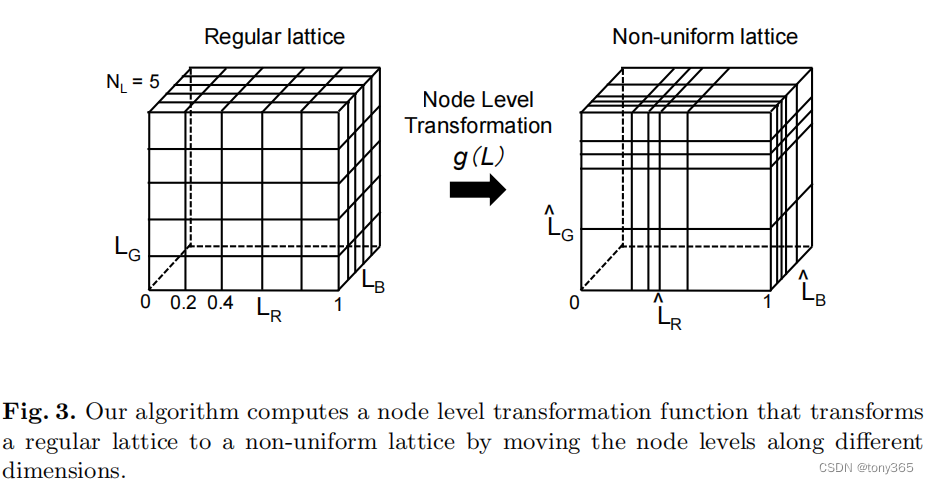
实际上作者就是构建了一个单调查找表。如何构建呢?
从误差着手。
比如 r1, b1, g1=(1,2,3)查找出来时r2,g2,b2,误差为er1,eb1,eg1。那么(1,2,3)所在的bin 的直方图加上er1,eb1,eg1。 最终可以构建一个1,2,3,4.,,255的直方图,文中时raw图0-1023的直方图。
错误越大,说明该分段 精度越差,需要分配更多的 更细化的 网格。通过图a得到一个图c的转换表。
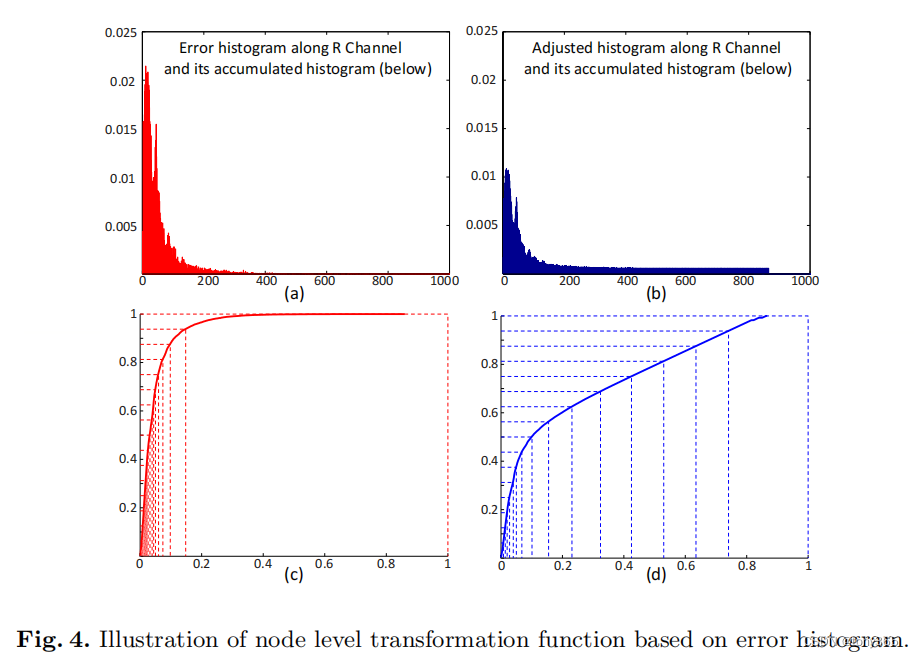
但是由于直方图中有很多空bin, 因此平滑一下得到b:

然后d就是想要的分布,现在的分布时线性,转换为d的分布,就利用直方图规定化的方法,求一个反向查找表。
首先求累计:
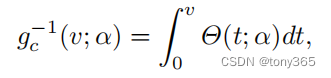
再求反向:
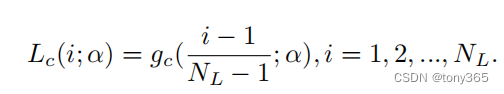
3.4. 重新求解lattice regression
一个转换的查找表得到之后,non-uinform的每个格的顶点位置也确定了,那么 W, Sb, ρ\rhoρ 也需要重新构建,然后求解
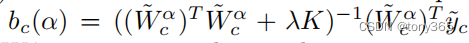
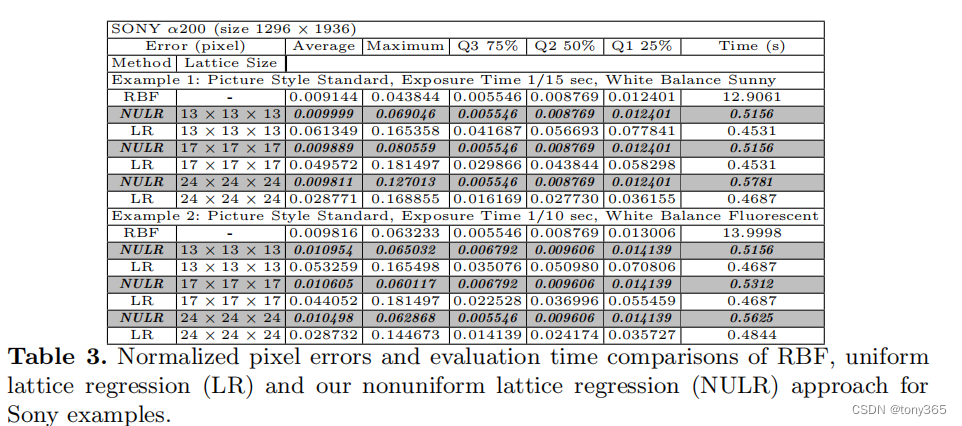
3.5. 实验
non-uniform 3dlut比 regular3dlut 效果好,比rbf 效率高,且精度不会降太多。
上一篇:图解redis的列表对象
下一篇:C++ 类与对象 (下)