正则表达式高阶技巧之转义的介绍(使用python实现)
创始人
2025-06-01 01:09:44
0次
转义
- 转义介绍
- 字符串转义与正则转义
- 注意:
转义介绍
字符串转义与正则转义
- 理解转义的基础是,要明白字符串与正则表达式的关系。通常说的string(字符串)中,string被称为字符串文字(String Literal),它是某个字符串的值在源代码中的表现形式。比如字符串文字\n,它包含\和n两个字符,意义(或者说它的值)是一个换行符(为了方便观察,表示为
NL)。在生成字符串时,应当进行“字符串转义”,才能准确识别字符串文字中\n的意思,如下表:
| 字符串文字 | 字符串 | 说明 |
|---|---|---|
| \n | NL | 换行符 |
| \t | Tab | 制表符 |
| \\ | \ | 反斜线字符 |
- 在另一个方面,在源代码中看到的“正则表达式”regex,其中的regex称为正则表达式文字(Regular Literal,一下简称正则文字),是正则表达式的表现形式。比如正则表达式
\d,其正则文字包含\与d,它的意义(或者说值)是匹配数字字符的字符组简记法。在生成正则表达式时应当进行“正则转义”,才能将正则文字中的\d识别为字符组简记法 - 上述两点不难理解,但从字符串转到正则表达式就比较复杂。因为很多正则表达式都是以字符串形式提供,必须经过从字符串文字到正则表达式的转换
- 根据上述:字符串文字首先必须经过“字符串转义”,才能得到真正的字符串;然后,这个字符串作为正则文字,经过“正则转义”,最终得到正则表达式。下图说明了从字符串文字到正则表达式转义过程

- 如下表格,若干常用的字符串的转义(从字符串文字到正则表达式的转换)
| 字符串文字 | 字符串/正则文字 | 正则表达式 | 说明 |
|---|---|---|---|
| \\n | \n | NL | 换行符 |
| \\t | \t | Tab | 制表符 |
| \\\ | \\ | \ | 反斜线 |
- 制表符与换行符的情况比较容易理解,它们的正则文字使 \n 和 \t,也就是字符串的值。但是字符串文字必须经过字符串转义才能的得到正则文字的 \n 和 \t ,字符串转义规则规定,反斜线\必须写成 \\ ,所以字符串文字必须写成 \\n 和 \\t
- 我们要在正则表达式中表示 \ ,必须使用正则文字 \\ ,这样在转义时才能正确识别。同时,正则文字中的每一个 \ 都必须使用字符串文字 \ 表示,所以正则表达式 \ 对应的字符串文字就是 \\\\。最开始学习正则表达式时,就会有人在网络上问为啥需要四个 \ 反斜线,原因就是上述
如下测试:
import rere.search("\\\\", '\\') is not None

- 有些情况较为复杂:正则表达式中的换行符或者制表符,在字符串文字中必须写成 \\n 或 \\t;但是,使用 \n 与 \t 也是没有问题的。原因是在于:在处理字符串转义时,他们已经被解释称换行符或者制表符,所以传递给正则表达式的字符串中就包含了换行符或者制表符,如下表所示:
| 字符串文字 | 字符串/正则文字 | 正则表达式 | 说明 |
|---|---|---|---|
| \\n | \n | NL | 换行符 |
| \n | NL | NL | 换行符 |
| \\t | \t | Tab | 制表符 |
| \t | Tab | Tab | 制表符 |
- 从上述表格可以看出,字符串文字中的 \\n 与 \n 表示的是同一个字符,只是前者先做了字符串的转义,再做了正则转义,而后者只做了字符串转义。如此看来,似乎是 \n 更加符合直觉一些 ----- 如果你确定能够理解,为什么字符串文字中 \n 和 \n 的结果竟然一样,使用 \n 确实是可行的
- 但是,正则表达式中 \ 的字符串文字还是必须写成
\\\\
如下测试:
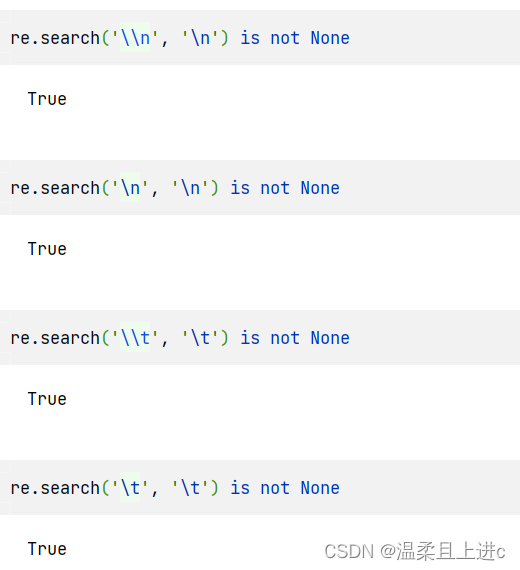
re.search('\\n','\n') is not None
re.search('\n','\n') is not None
re.search('\\t','\t') is not None
re.search('\t','\t') is not None
注意:
- 要特别注意的是
\b,在一般的字符串中,\b是预定义的转义序列,表示退格符(backspace,表示为BS);但是在正则表达式中,它表示的是单词边界(记为\B),如果在字符串文字中写\b,字符串转义为退格符,交给正则表达式,正则表达式真正的得到的是退格符BS,而不是单词边界\B
如下举例:
re.search('\ba\b', 'a') is not Nonere.search('\\ba\\b', 'a') is not None

- 所以如果用到了单词边界,在字符串文字中一定要写成
\\b,所以,在使用中最保险的方法是:正则表达式中的每一个\,在字符串文字中都要写成\\,如下表格:
| 字符串文字 | 字符串/正则文字 | 正则表达式 | 说明 |
|---|---|---|---|
| \b | BS | BS | 退格符 |
| \\b | \b | \B | 单词边界 |
- python中还有一个特殊规定,如下举例:
re.search('\d', '1') is not Nonere.search('\(', '(') is not None

- 上述看起来是有点奇怪的,因为字符串中
\d与\(都不是合法的转义序列,为啥不会报错?这是因为python对字符串特殊的规定:如果遇到无法识别的转义序列,则将它原封不动的保存下来 如下表:
| 字符串文字 | 字符串/正则文字 | 正则表达式 | 说明 |
|---|---|---|---|
| \\d | \d | \d | 字符组简记法 |
| \d | 无法识别,原样保存 | \d | 字符组简记法 |
- 从上面来看,使用字符串形式的正则表达式,转义的处理是比较麻烦的。最好能省去这些麻烦----正则表达式是怎么样的,正则文字中就怎么样写
- 在python中可以使用原生字符串(Raw String),也就是忽略字符串转义的特殊字符串,如下python举例:
# 在字符串之前使用 r 来标注原生字符串
pattern=re.compile(r"a\.\nb\b")
上述来看:如果可以使用原生字符串或者正则文字直接来表示正则表达式,应该尽量使用这种做法,因为其简单直观,方便理解,在此之前关于正则的博客以及此后的博客,如果能使用原生字符串表示正则表达式,则使用原生字符串,python示例为r"regex"
- 如果不使用原生字符串,而必须要使用字符串文字的话,请尽量坚持这条原则:正则表达式的每个反斜线 \ ,在字符串文字都必须写成 \\,而且不推荐使用语言自身提供的“字符串无法转义时将无法识别的转义序列保留下来”的规定,如:要在正则表达式中使用字符组简记法
\d,正则文字中要写出\\d,而不是\d
相关内容
热门资讯
保存时出现了1个错误,导致这篇...
当保存文章时出现错误时,可以通过以下步骤解决问题:查看错误信息:查看错误提示信息可以帮助我们了解具体...
汇川伺服电机位置控制模式参数配...
1. 基本控制参数设置 1)设置位置控制模式 2)绝对值位置线性模...
不能访问光猫的的管理页面
光猫是现代家庭宽带网络的重要组成部分,它可以提供高速稳定的网络连接。但是,有时候我们会遇到不能访问光...
不一致的条件格式
要解决不一致的条件格式问题,可以按照以下步骤进行:确定条件格式的规则:首先,需要明确条件格式的规则是...
本地主机上的图像未显示
问题描述:在本地主机上显示图像时,图像未能正常显示。解决方法:以下是一些可能的解决方法,具体取决于问...
表格列调整大小出现问题
问题描述:表格列调整大小出现问题,无法正常调整列宽。解决方法:检查表格的布局方式是否正确。确保表格使...
表格中数据未显示
当表格中的数据未显示时,可能是由于以下几个原因导致的:HTML代码问题:检查表格的HTML代码是否正...
Android|无法访问或保存...
这个问题可能是由于权限设置不正确导致的。您需要在应用程序清单文件中添加以下代码来请求适当的权限:此外...
银河麒麟V10SP1高级服务器...
银河麒麟高级服务器操作系统简介: 银河麒麟高级服务器操作系统V10是针对企业级关键业务...
【NI Multisim 14...
目录 序言 一、工具栏 🍊1.“标准”工具栏 🍊 2.视图工具...