MySQL索引及索引失效的分析(MySQL8.0.19)
目录
- 索引数据结构
- 主键索引
- 非主键索引
- 索引在什么时候是有效的?
- 字符串比较大小
- btween and
索引数据结构
主键索引
我们先来看看索引的数据结构,以及我们是如何利用索引来搜索数据的。MySQL的数据存储结构是B+树,在叶子节点存储了数据行,非叶子节点是主键索引。(MySQL的叶子节点是用双向链表链接的)
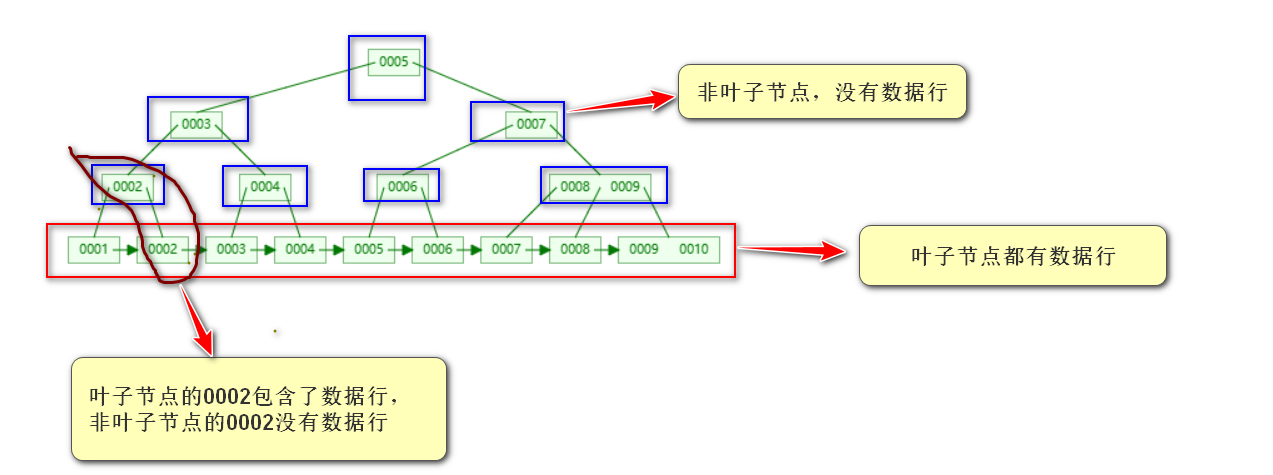
在MySQL中,表的数据行只存在于主键索引的叶子节点;因此查询任何数据都必须要搜索到叶子节点。B+树是一个多路平衡搜索树可以看出整个树结构是有序的(搜索过程与二叉搜索树的搜索过程相似);(PS:如果不了解B+树可以先了解下它的结构和特性)
如果要搜索id =7的数据行它的搜索过程是怎样的呢?select * from test_a where id = 7;(id是表主键)
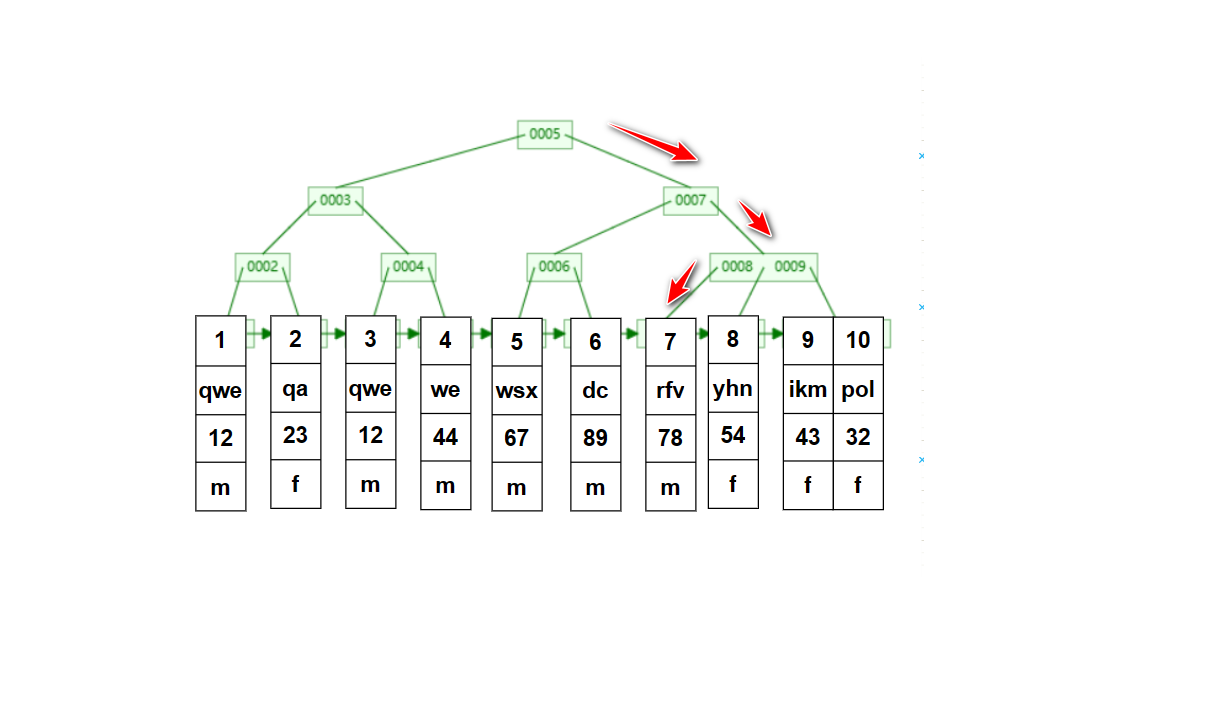
因为搜索条件是id这是一个主键索引,因此在搜索数据时会直接利用B+树的结构做搜索。只用3次查找就可以找到id=7的数据行了。如果我们用年龄来做搜索条件呢?(select * from test_a where age = 78;)
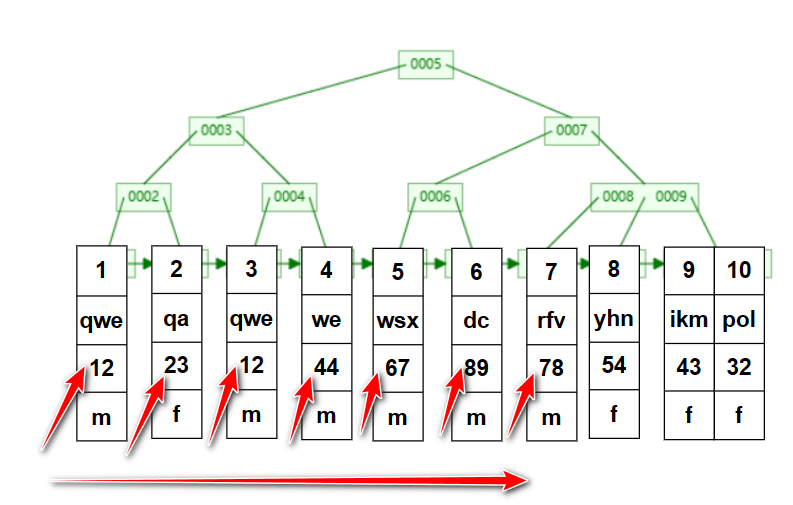
只能全表挨个搜索了,因为年龄字段的存储是乱序的没有办法像搜索id那样利用id的有序性来做搜索。搜索7次才找到明显比上面的搜索次数多。并且有索引的行搜索所有的数据行都是3次(id=1~10),效率是很稳定的;实际在利用age做搜索条件时会搜索整个表,因为不确定后面是否有age=78的行。在数据量很大的时候,明显能感受到有索引和没有索引的差距。因为利用没有索引的字段做搜索条件会搜索整个表,而有索引的字段只需要根据B+树做搜索搜索次数是成指数减少的。
怎样让age作为搜索条件时,也可以减少搜索次数呢?给age建立一个B+树的结构—>建立索引。将表中所有行的age值用来建立一个B+树,那它的叶子节点也存储整个数据行吗? 显然不能这样做,这样做太浪费空间了。MySQL的做法是叶子节点存储主键id的值,这样就可以跟数据行关联起来了。(问题1:为什么不直接存储数据地址呢,岂不是更方便直接?这个问题文章末尾再讨论)
非主键索引
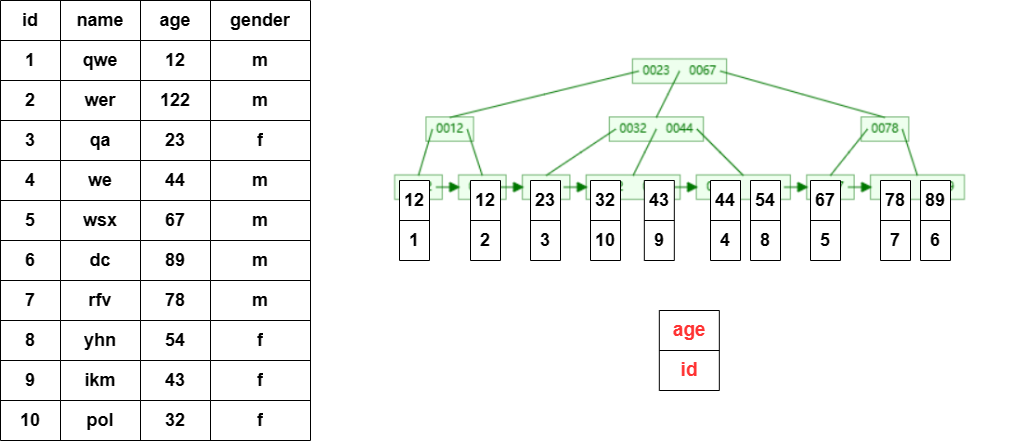
现在仍然用age做搜索条件:select * from test_a where age = 78;因为给age加了索引,因此搜索首先会搜索age的索引,也就是age值组成的B+树;
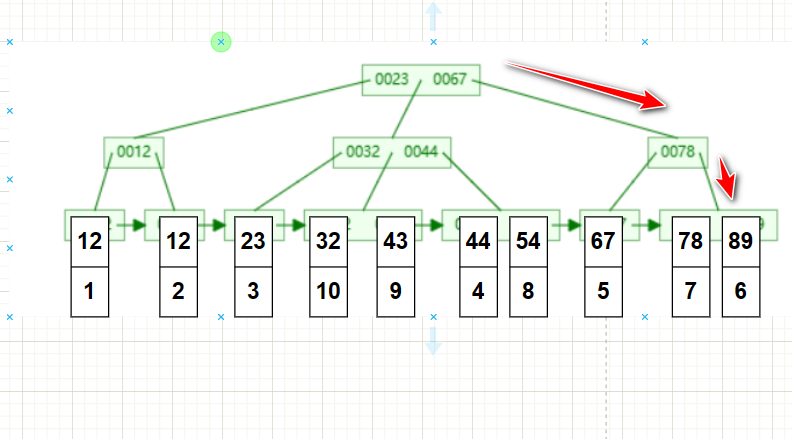
当搜索找到了age=7的时候只能够拿到主键id的值,而我们需要的是整个数据行的值,因此还需要用id的值去搜索主键的索引(B+树)也就是所谓的返表。从这里看出,如果只需要id字段就不要使用select * 来查询了。(问题2:在实际操作的时候,很少会使用select * 但是有时侯就是需要查询其他字段比如 :select id,name from test_a where age =78.这个时候该如何优化呢?有没有一种方法能够避免返表的操作呢?)
虽然使用索引可能会导致查找2个索引,但是在数据量特别大的时候相比较于没有索引的搜索也会快很多;使用索引搜索查找的次数与不使用索引相比是呈指数减少的。(问题3:这里有一个问题,age的值可能有重复不是唯一索引,因此当搜索到叶子节点age=7的时候搜索还没有完成,MySQL会如何处理普通索引呢?是所有字段都适合建立索引吗?)
索引在什么时候是有效的?
可以回想下,MySQL是如何利用索引进行搜索的?其实很简单,就是利用被搜索的字段值和B+树节点的值作比较,通过结果选择该搜索哪个分支。每搜索一层就会过滤掉其他分支减少搜索的次数,B+树就是通过这种方式来提高搜索效率的。(可以类比二叉搜索树的过程)简单来说,如果可以利用被搜索的字段值与B+树的节点值作比较,那就可以利用B+树来做搜索。如果被搜索字段不能与B+树的节点值比较,那索引就失效了。(理论上是这样的,但是MySQL还做了其他优化),要看是否走了索引可以用explain关键字来查看。
字符串比较大小
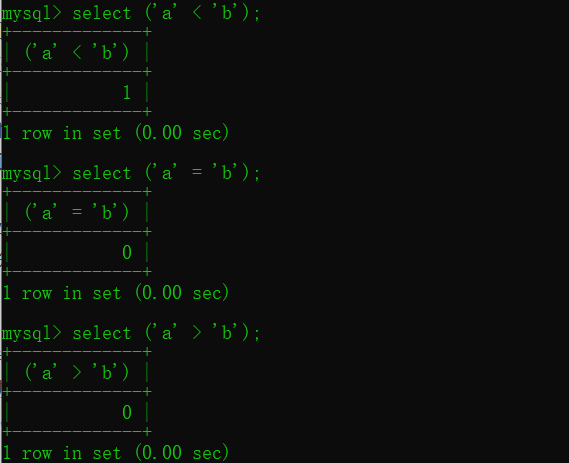
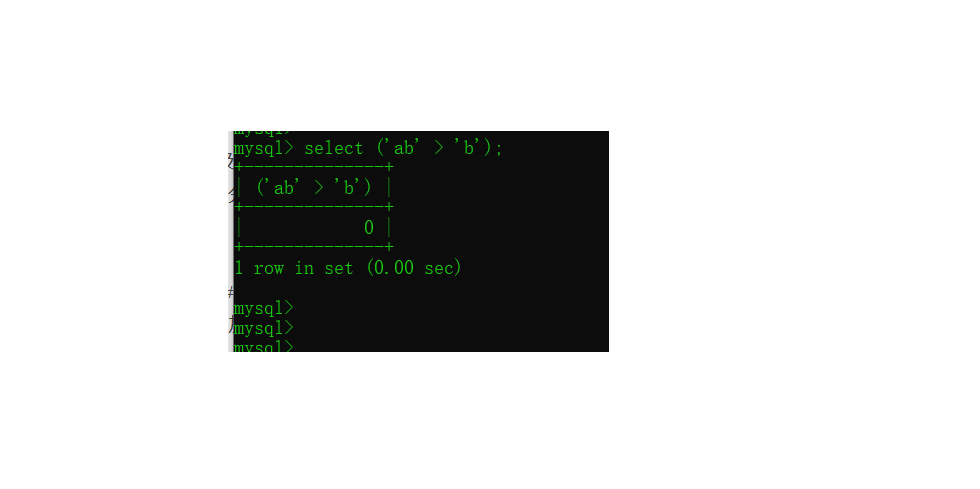
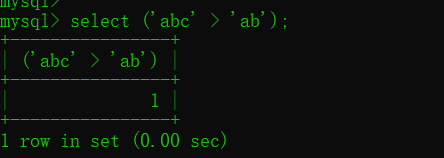
这涉及到在MySQL中如何比较2个值的大小问题了。在MySQL中比较字符串,是取出字符串的每一个字符来分别作比较。与String类的compareTo方法比较字符串大小大的规则是一样的。都是从第一个字符开始比较大小:如果第一个字符分出大小就返回;如果相同继续比较后面的字符;
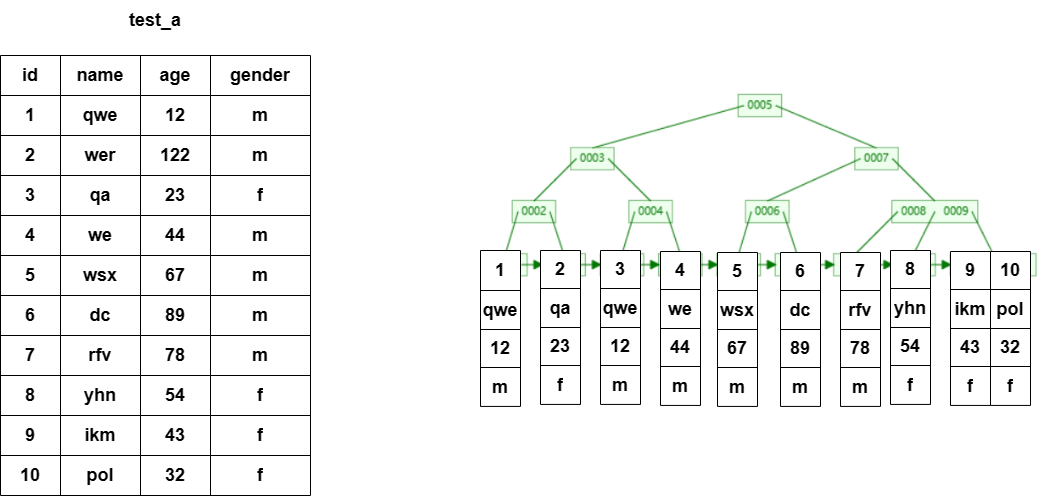
CREATE TABLE test_a(
id INT PRIMARY KEY ,
NAME VARCHAR(20),
age INT ,
gender char(1)
);INSERT INTO test_a VALUES(1,'qwe',12,'m');
INSERT INTO test_a VALUES(2,'wer',122,'m');
INSERT INTO test_a VALUES(3,'qa',23,'f');
INSERT INTO test_a VALUES(4,'we',44,'m');
INSERT INTO test_a VALUES(5,'wsx',67,'m');
INSERT INTO test_a VALUES(6,'dc',89,'m');
INSERT INTO test_a VALUES(7,'rfv',78,'m');
INSERT INTO test_a VALUES(8,'yhn',54,'f');
INSERT INTO test_a VALUES(9,'ikm',43,'f');
INSERT INTO test_a VALUES(10,'pol',32,'f');SELECT * FROM test_a ;CREATE INDEX index_age ON test_a(age);btween and
现在举几个例子判断一下索引是否失效:
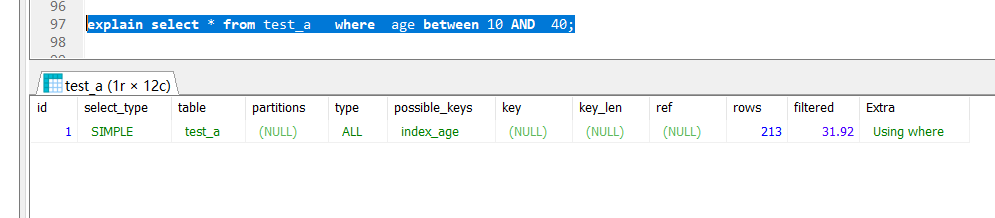
# test_a有一个主键id索引,age索引explain select id from test_a where age between 10 AND 100;explain select * from test_a where age between 10 AND 100;explain select * from test_a where age between 10 AND 40;-
第一个使用了索引;explain select id from test_a where age between 10 AND 100;

-
第二个没有使用索引;explain select * from test_a where age between 10 AND 100;

-
第三个使用了索引;explain select * from test_a where age between 10 AND 40;

前面2个SQL语句对比起来看:第一个sql为什么走了age的索引?第二个SQL不走索引?
分析一下这2个SQL有什么不同?第一个SQL直接查询id,不会返表。第二个SQL查询所有字段,拿到id会返回主键索引查询。从这2条SQL的结果对比来看会得出一个结论:在索引上使用(between and 或者 age > mm and age
后面2个SQL语句对比起来看:第三个sql为什么走了age的索引?第二个SQL不走索引?
可以看到(10-100)占表90%的数据,基本上没怎么过滤数据,而(10-40)占表30%的数据,过滤了大部分的数据。后者拿到了一个较小了结果集,前者基本算是没有过滤了。因为还要拿着查询到的主键id到主键索引树再查询一次,如果没有筛选掉大部分的数据,拿着90%的id主键到主键的B+树上查询,相当于是来了2次全表查询,效率会相当低。这种情况下不走age的索引,直接全表查询效率会更高。
后续将范围扩至(10-78)包含70%数据也走了索引,情况有点诡异。后续往表里面添加100条数据(age:1-100)总数居113条,范围(10-78),没有走索引。当范围降至(10-41)时又会走索引。

 再往表里添加100条数据(age:1-100),总共213条数据,与数据113条时相比:年龄(10-40)范围还要小,但是没有走索引。这就需要结果集数据占比减小,才可能走索引。
再往表里添加100条数据(age:1-100),总共213条数据,与数据113条时相比:年龄(10-40)范围还要小,但是没有走索引。这就需要结果集数据占比减小,才可能走索引。
综合上面的情况,使用范围查询到底要不要走索引?如果需要返表查询会受到表的数据总量和查询到的结果集占总表数据量的占比这2个因素的影响。表的数据量越大,想要走索引那么查询的结果集就必须占比越小。表的数据量小,即使结果集占比较高也会走索引。
可以思考下面2个sql语句是否会走索引:
explain select * from test_A where age != 67;
explain select id from test_A where age != 67;
吃完饭再来跟新,未完待续。。。