Excel2Table框架搭建 - Excel文件与数据库相互转换的工具
Excel2Table框架搭建
毕设某模块,源码暂不公开。但总体实现,在实现原理一节基本叙述完毕。
本文仅是初期实现的记录分享。
1. 基本特性:
对于简单的Excel文件(第一行为列名,后续为数据)
- 支持根据excel文件动态建表
- 支持根据表数据生成excel文件
- 实现一一对应:Java对象实体 - 数据库表 - Excel文件
- 实现运营人员与开发工具相隔离,让医生更专注在工作上,让开发人员用最少的精力去维护系统。
- Android端、Java后端代码通用
2. 基本思路:
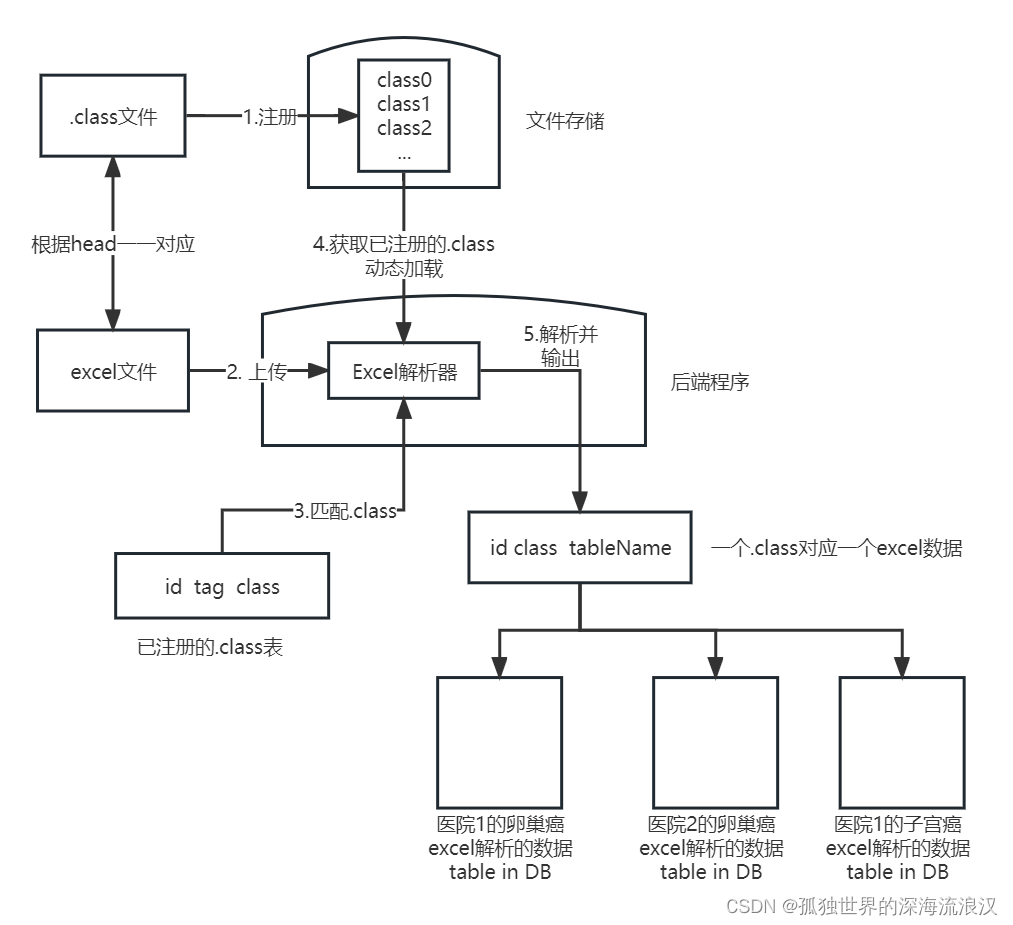
3.基本使用:
- 引入初版实现 excel2table 框架
- 与 EasyExcel 等 Excel 解析工具 配合使用
3.1 场景说明
目前需要上传的Excel为(Excel文件截图):
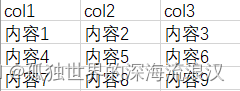
JavaBean(将要生成字节码用)为:
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("dian_temp_excel_vo")
public class TempExcelVo {@TableColumn(name="col1")private String x;@TableColumn(name = "col2")private String y;@TableColumn(name = "col3")private String z;}
其中变量名被混淆了(这也是为什么要用注解的原因)。将该Java文件编译成为字节码文件,上传到服务器的某个文件存储位置。
3.2 上传Excel文件,并解析
这里模拟直接获取到了字节码所在的路径,客户端上传了一个excel文件,需要进行解析处理:
@PostMapping("upload1")
public void upload1(@RequestParam("excel") MultipartFile file){//path为字节码所在的父路径String path = "D:/JavaProjects/clinic/target/classes";//父路径//name为字节码的全类名String name = "com.dian.clinic.entity.vo.TempExcelVo";//全类名//ExcelTableGenerator是上传入口ExcelTableGenerator generator = new ExcelTableGenerator(clazzTableService);//加载字节码,顺带建表generator.loadClass(path, name, new ExcelTableGenerator.IClzTableService.TableCreateCallback() {@Overridepublic void finish(Class clz, String tableName) {//回调 - 建表完成//建表完成之后,通过EasyExcel解析excel,将解析后的数据写入表中try {//文件输入流InputStream is = file.getInputStream();//不带id的读取,和excel头保持一致EasyExcel.read(is, clz, new ExcelUploadListener(clz)).sheet().doRead();}catch (Exception e){// e.printStackTrace();System.out.println("上传文件出错");}System.out.println("上传excel解析完成");;}@Overridepublic void error() {System.out.println("上传文件出错");}});
}
执行会做两件事:
1.如果 @TableName 注解中的表名不存在,将会建表,同时通知需要记录 class-table 数据的表更新信息(Navicat界面截图):
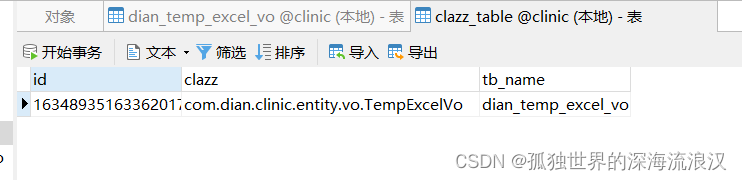
2.将Excel数据解析,并填入表中(Navicat界面截图)

3.3 下载Excel文件
通过Excel2Table工具读取表数据,再通过EasyExcel生成Excel文件
@PostMapping("download1")
public void download1(HttpServletResponse response){try{response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");response.setCharacterEncoding("utf-8");// 这里URLEncoder.encode可以防止中文乱码 当然和easyexcel没有关系String fileName = URLEncoder.encode("TempExcel", "UTF-8").replaceAll("\\+", "%20");response.setHeader("Content-disposition", "attachment;filename*=utf-8''" + fileName + ".xlsx");TableManager tableManager = TableManager.getInstance();//传入一个Class<>对象去解析headList> head = tableManager.getHead(TempExcelVo.class);EasyExcel.write(response.getOutputStream()).head(head).sheet("模板").doWrite(tableManager.search(TempExcelVo.class));//list}catch (Exception e){e.printStackTrace();}
}
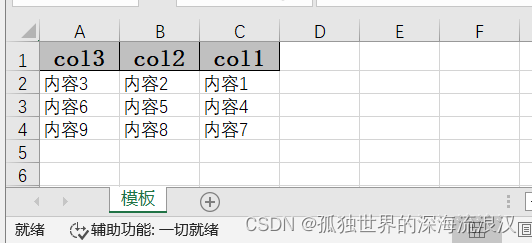
EasyExcel生成Excel文件需要head,这可以是List 类型的,对应的写入的数据 data 需要是 List 类型的。本场景下:
- head为:
[[col3], [col2], [col1] - data 为:
[[内容3,内容2,内容1],[内容6,内容5,内容4],[内容9,内容8,内容7]]
解析后,生成文件:
4. 实现原理
4.1 注解与反射
希望能有一个模板来建表,我们可以通过反射成员变量的名字来建表:
//直接使用模板的成员变量名来建表
public int createTableFromClazz(Class clazz,String tableName){//为了简单起见,类变量的名字直接转成column名,可以在这里插入驼峰转换的工具Map> map = new HashMap<>();Field[] fields = clazz.getDeclaredFields();Field cur;StringBuilder sb = new StringBuilder();//默认初始值,不希望提前占过多内存//可能要拼接 if exists,这里暂时不拼接sb.append("create table ").append(tableName).append("(\n");//给个默认升序idsb.append("id int not null auto_increment primary key,");for (int i = 0; i < fields.length; i++) {cur = fields[i];cur.setAccessible(true);//拿到名字String colName = cur.getName();//拿到类型,简便起见全都转为String类型//Class type = declaredField.getType();sb.append(colName).append(" ").append(sqlMap.get(String.class));if (i sb.append(",\n");}else{sb.append(");");}}//打印建表语句System.out.println(sb.toString());//建表语句拼接完成,开始建表String sqlStatement = sb.toString();int createTableResult = CRUDTemplate.executeUpdate(new SqlParam(sqlStatement));if (createTableResult==0){//建表失败
// System.out.println("建表失败");}return createTableResult;}
但是这样就带来一个坏处,一方面模板可能会经过代码混淆,字节码中变量名被修改。另一方面,模板类无法再引入其他变量。为了拓展性考虑,使用注解进行标注信息:
- @TableName : 模板类对应的表名
- @TableColumn: 某个列名,机器对应的表属性
//TableName
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface TableName {String value();//tableName
}
//TableColumn
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface TableColumn {//表名String name();//类型,默认是字符串类型String type() default Type.STR;//长度,默认100int len() default 100;//如果需要,可以增加主键,excel暂时不需要
}
使用注解还有一个好处,易拓展,可以在原有基础上,增加可以表示的表信息。(如果直接在TableColumn上做修改的话,就违反了开闭原则,这里的“拓展性”只体现在开发框架的时候,并不体现在程序运行中)
有了这些注解信息,我们就可以通过反射来根据表名、列信息来建表。在此之前,我们还需要将字节码文件加载入系统,所以我们需要自定义类加载器:
public class ExcelClassLoader extends ClassLoader {/*** 加载二进制数据* @param path 文件所在父路径(注意是全类名之上的父路径)* @param name 全类名转为文件名 com.company.User->com/company/User * @return*/private byte[] loadByte(String path,String name) throws Exception{name = name.replaceAll("\\.","/");//ava.io.FileNotFoundException: D:\JavaProjects\clinic\target\classes\com\dian\clinic\entity\vo\TempExcelVoBeanInfo.class (系统找不到指定的文件。)FileInputStream fis = new FileInputStream(path+"/"+name+".class");int len = fis.available();byte[] data = new byte[len];fis.read(data);fis.close();return data;}//生成Class<>对象public Class findClass(String path,String name) throws ClassNotFoundException{try{byte[] data = loadByte(path,name);return defineClass(name,data,0,data.length);}catch (Exception e){//e.printStackTrace();throw new ClassNotFoundException();}}}
原理很简单,通过文件输入流,直接读取字节码的二进制串,通过defineClass生成一个Class<>对象,如果需要拓展,可以增加网络输入流等方式,增加字节码传输方式。
类加载完成后,就可以进行反射解析注解,并且建表了,这部分逻辑和直接反射成员变量拼接sql语句是几乎类似的。经过实验是可行的,但是问题来了,反射是非常消耗性能的,如何解决这个问题?在文章 Retrofit中的反射耗时,罪魁祸首并不在动态代理,而在反射注解 中,讨论了反射优化。我们通过添加缓存,将那些统一的反射逻辑封装到一个模板中,未来就根据这个模板来创建实例。
4.2 反射优化
我们建立一个Template作为可以用来缓存的模板:
//模板类,用于缓存
public class Template {//同时也缓存了所有Template//LRU,便于FullGC释放元空间的Class对象private static final Map, Template> cache = new LruMap(50);private String tableName;//tableName - field - 用来反向构建一个对象private final Map mTableNameFieldMap;//field - annotation - 用于拼接sql语句private final Map mAnnotationMap;private Template() {//外部自己维持好并发问题this.mTableNameFieldMap = new HashMap<>();this.mAnnotationMap = new HashMap<>();}//假单例//开始解析public static Template parse(Class clz) {//先看有没有缓存,优先使用缓存//考虑并发安全if (cache.containsKey(clz)) {return cache.get(clz);} else {//DCL,不用加volatile了,已经final可见性了synchronized (Template.class){if (!cache.containsKey(clz)) {//反射Template t = parse0(clz);//计入缓存cache.put(clz, t);return t;}else{return cache.get(clz);}}}}private static Template parse0(Class clz) {//必须要有表名TableName tableNameAnnotation = clz.getAnnotation(TableName.class);if (tableNameAnnotation==null){throw new RuntimeException("模板必须要有tableName");}Template t = new Template();//设置表名t.tableName = tableNameAnnotation.value();//反射Field[] fields = clz.getDeclaredFields();//遍历,查看其注解for (Field field : fields) {//置为可访问field.setAccessible(true);TableColumn annotation = field.getAnnotation(TableColumn.class);//如果没有这个注解,跳过,不处理if (annotation == null) continue;//如果有,获取表名String tableName = annotation.name();t.mTableNameFieldMap.put(tableName, field);t.mAnnotationMap.put(field,annotation);}//解析完毕return t;}public Map getmTableNameFieldMap() {return mTableNameFieldMap;}public Map getmAnnotationMap() {return mAnnotationMap;}public String getTableName() {return tableName;}public void setTableName(String tableName) {this.tableName = tableName;}private static class LruMap extends LinkedHashMap, Template> {int capacity;public LruMap(int initialCapacity) {super(initialCapacity);this.capacity = initialCapacity;}//超过了就删掉最少访问的@Overrideprotected boolean removeEldestEntry(Map.Entry, Template> eldest) {return size()>capacity;}@Overridepublic Template remove(Object key) {//截获删除的节点,从其他map中把它也删掉//其实也不用截获,它本身被删除之后就没有引用了//如果还有引用,在这里要做后续断掉引用的操作,避免内存泄漏Template removed = super.remove(key);return removed;}}
}
这里我使用LinkedHashMap的LRU实现,来进行缓存处理,因为我们知道,类的加载过程中,类信息、Class对象都会存在本地内存(元空间)中,程序运行地越久,加载的类越多,当类达到一定量的时候,就会触发 FullGC,此时可能会清理本地内存(元空间)中的数据,如果这些数据还被持有强引用,将不会被清理,这是非常危险的。此外,LinkedHashMap缓存将会跑在内存中,如果体积太大,也是不好的。所以我们给它限制了 50 的大小。通过LRU(最近最少使用删除调度)来控制缓存大小。
Template类中的LinkedHashMap是全局缓存,存了所有的Template。
每个Template实体,作为模板,保存了反射到的信息,例如表名、注解实体。后续可以通过引用实例的方式,而不是反射的方式进行这些信息的访问,提高效率。
4.3 建表
有了Template,我们就可以进行建表了,将这部分逻辑解耦到两处:
- TableManager 负责上层调度,发起建表、填充数据、数据查询
- CRUDTemplate 进行实际的数据库操作逻辑
CRUDTemplate很简单了,就是通过JDBC访问数据库,通过sql语句来执行数据库操作。我们直接看到TableManager中是如何通过Template进行建表的:
//TableManager.java
/*** 根据解析出来的Template进行建表*/
public Template createTableFromTemplate(Class clz){//解析clz,可能会复用之前的templateTemplate template = Template.parse(clz);//开始建表Map map = template.getmAnnotationMap();StringBuilder sb = new StringBuilder();//默认初始值,不希望提前占用过多内存sb.append("create table ").append(template.getTableName()).append("(\n");//给个默认升序id,这里可以根据业务逻辑修改,或者通过某种设计模式将此逻辑抛出去给上层动态设置。更适配开闭原则sb.append("id int not null auto_increment primary key,\n");//开始拼接建表语句Iterator> iterator = map.entrySet().iterator();Map.Entry cur;//写在外面避免内存抖动while (iterator.hasNext()){cur = iterator.next();TableColumn anno = cur.getValue();//例如"phone varchar(20)"sb.append(anno.name())//这个是必须由的值.append(" ").append(anno.type())//这个如果没有设置,有默认值varchar.append("(").append(anno.len())//这个如果没有设置,有默认值100.append(")");if (iterator.hasNext()){sb.append(",\n");}else{sb.append(");\n");}}//打印建表语句System.out.println(sb.toString());//拼接完成,开始建表String sqlStatement = sb.toString();int i = CRUDTemplate.executeUpdate(new SqlParam(sqlStatement));System.out.println(i);return template;
}
4.4 查表
我们只需要根据模板来判断生成一个Excel文件需要哪几列数据,拼接出sql语句,剩下的就交给CRUDTemplate工具了:
public List> search(Class clz){Template template = Template.parse(clz);String tableName = template.getTableName();StringBuilder sb = new StringBuilder();//先从缓存中拿sql语句if (searchSqlCache.containsKey(clz) && searchColumnCache.containsKey(clz)){sb.append(searchSqlCache.get(clz));}else {//拿不到才拼接,并添加到缓存中Map map = template.getmAnnotationMap();sb.append("select ");Iterator> iterator = map.entrySet().iterator();ArrayList columnName = new ArrayList<>();while (iterator.hasNext()) {Map.Entry next = iterator.next();String name = next.getValue().name();columnName.add(name);sb.append(name);if (iterator.hasNext()) {sb.append(",");} else {sb.append(" ");}}sb.append("from ");sb.append(tableName);searchSqlCache.put(clz,sb.toString());searchColumnCache.put(clz,columnName);}List> result = CRUDTemplate.executeQuery(new SqlParam(sb.toString()), new IResultSetHandler() {@Overridepublic List handle(ResultSet... resultSets) throws Exception {ResultSet res = resultSets[0];List> list = new ArrayList<>();while (res.next()){ArrayList 4.5 TableManager优化
虽然有了Template缓存优化,但是发现每次都需要拼接sql语句,如果某个Template用的很频繁,将会出现重复拼接之前已经拼接过的sql语句,这是无用功,我们一样可以通过缓存复用之前拼接过的sql语句:
public class TableManager {//sql语句缓存//insertMap,String> insertSqlCache = new LruMap<>(50);//queryMap,String> searchSqlCache = new LruMap<>(50);Map,List> searchColumnCache = new LruMap<>(50);private TableManager(){}private static class LruMap extends LinkedHashMap{int capacity;public LruMap(int initialCapacity) {super(initialCapacity);this.capacity = initialCapacity;}//超过了就删掉最少访问的@Overrideprotected boolean removeEldestEntry(Map.Entry eldest) {return size()>capacity;}@Overridepublic V remove(Object key) {//截获删除的节点,从其他map中把它也删掉//其实也不用截获,它本身被删除之后就没有引用了//如果还有引用,在这里要做后续断掉引用的操作,避免内存泄漏V removed = super.remove(key);return removed;}}
}
5. 待优化
- 架构模块分工并不清晰
- 查表逻辑不够开放,需要改进
- 性能与使用复杂数据库查询条件实现同样效果来说有一定差距。