达内 目标检测
2、数据表示


笔记:左边的表示数据格式(每个模型不一样,数据格式就不一样),第一个是置信度,表示这个区域有无目标物,代表可靠程度,置信度越高,存在目标物体的可能性越大。后面四个参数表示定位的参数,对目标物体进行定位;最后三个表示分类问题表示的参数(这里表示C1、C2、C3三个类别对应的概率)。
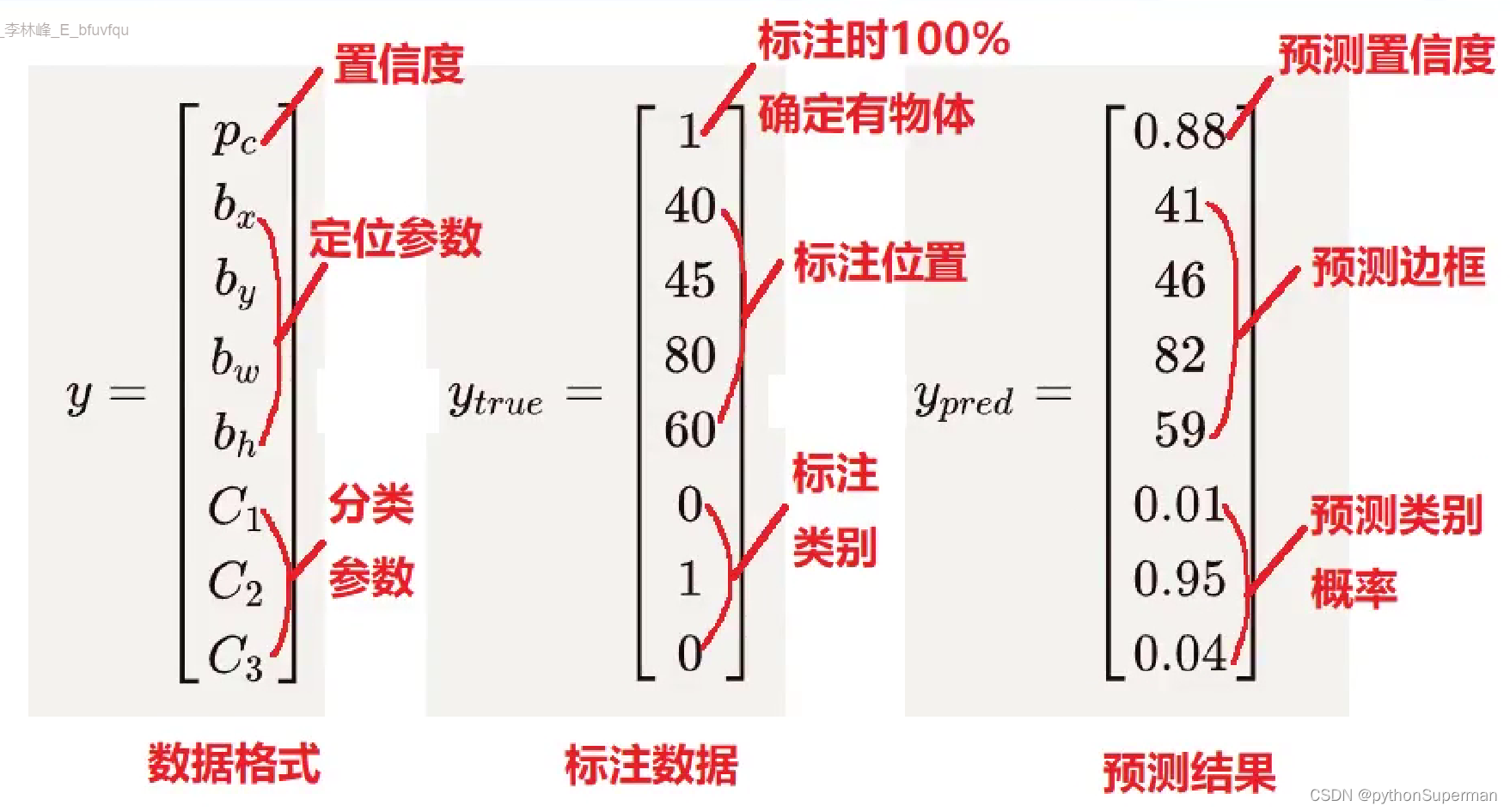
b位置结果交给均方差,C类别结果交给交叉熵,然后将均方差损失函数核交叉熵损失函数叠加在一起构成整体的损失函数。
3、效果评估:
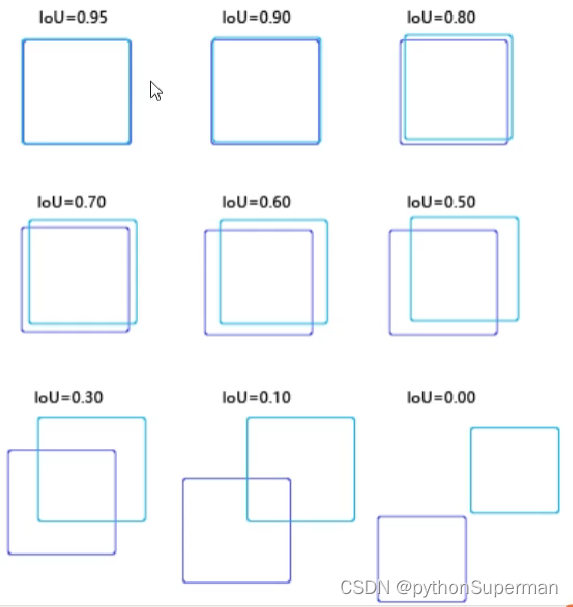
使用IoU(Intersection over Union,交并比)来判断模型定位的好坏。所谓交并比,是指预测边框、实际边框交集和并集的比率,一般约定0.5为一个可以接受的值。

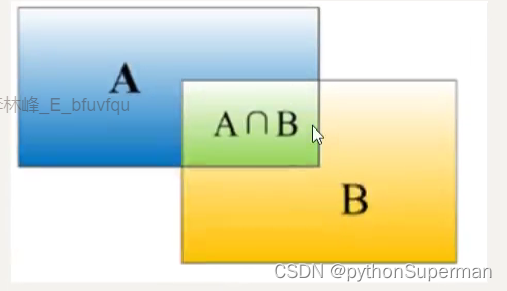
真实边框和预测边框完全重合,则交并比为1

交并比:

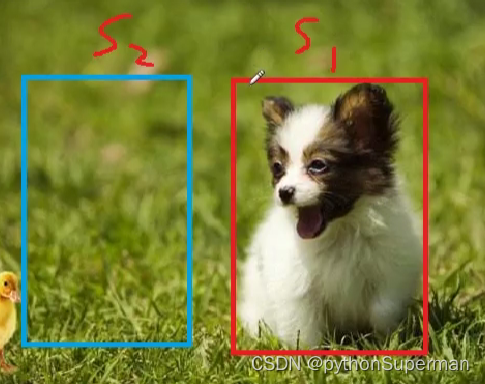
交并比的直观感受
4、非极大值抑制
预测结果中,可能多个预测结果间存在重叠部分,需要保留交并比最大的、去掉非最大的预测结果,这就是非极大值抑制(Non-Maximum Suppression,简写作NMS)。如下图所示,对同一个物体预测结果包含三个概率0.8/0.9/0.95,经过非极大值抑制后,仅保留概率最大的预测结果。
5、多尺度检测
特征金字塔(Feature Pyramid Network,简称FPN)指由不同大小的特征图构成的层次模型,主要用于在目标检测中实现多尺度检测。大的特征图适合检测较小的目标,小的特征图适合检测大的目标。
图像金字塔
把大小不同的金字塔叠加在一起。
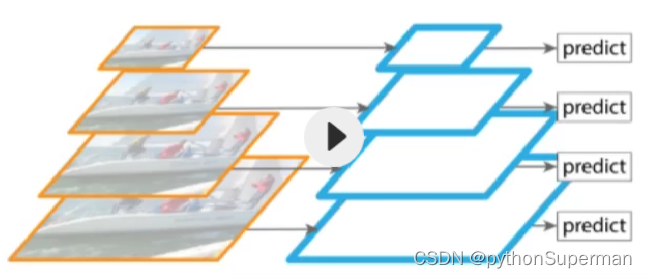
5、特征金字塔
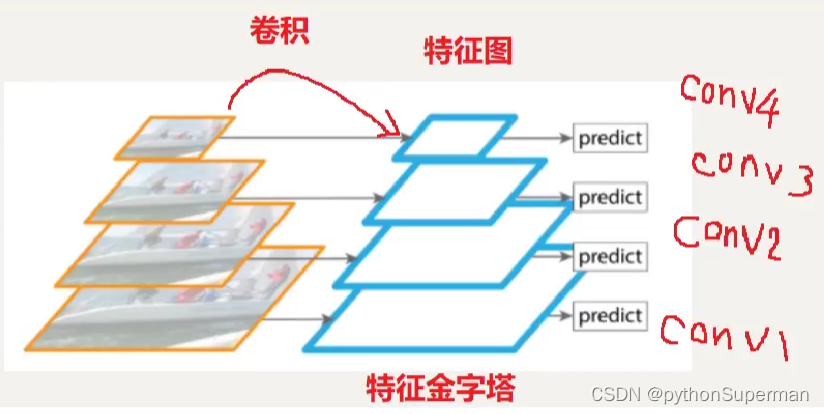
第一层、第二层卷积的时候提取的都是相对具体的特征,第三层、第四层这种高层自卷积提取的是相对抽象的特征。在预测的时候把具体的特征和抽象的特征放在一起考量、预测,这样预测的结果更准确。
卷积神经网络输出特征图上的像素点,对应在原始图像上所能看到区域的大小 称之为“感受野”,卷积层次越深、特征图越小,特征图上每个像素对应的感受野越大,语义信息表征能力越强,但是特征图的分辨率较低,几何细节信息表征能力越弱;特征图越大,特征图上每个像素对应的感受野越小,几何细节信息表征能力强,特征图分辨率较高,但语义表征能力较弱。为了同时获得较大特征图和较小特征图的优点,可以对特征图进行融合。
2)特征融合
- add:对小的特征图进行上采样,上采样至与大特征图相同大小,进行按元素相加。
- concat:按照指定的维度进行连接
三、目标检测模型
1.R-CNN系列
1)R-CNN
- 定义
定义(全程Regions with CNN features),是R-CNN系列的第一代算法,其实没有过多的使用“深度学习”思想,而是将“深度学习”和传统的“计算机视觉”知识相结合。比如R-CNN pipeline中的第二步和第四部其实就是传统的“计算机视觉”技术。使用selective search提取region proposals,使用SVM实现分类。
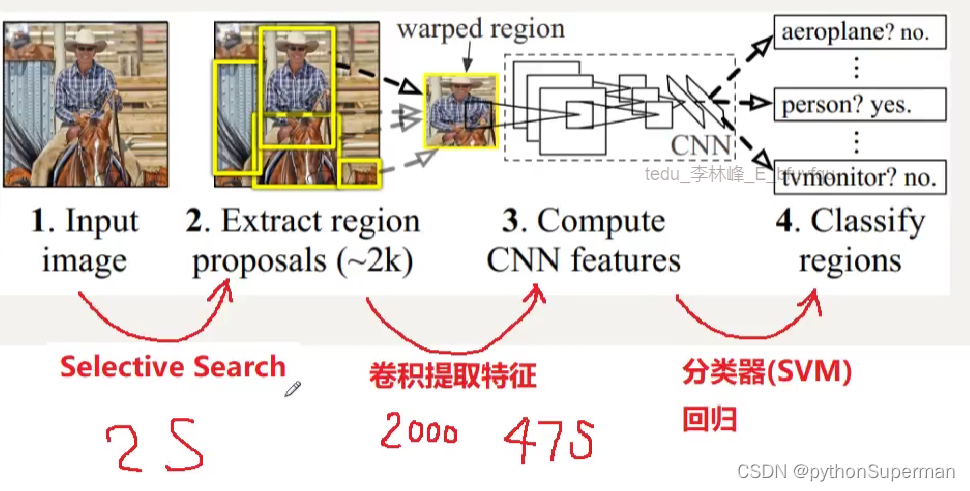
笔记:在原图像上产生大于2000个的候选区,然后将2000个候选区交给卷积神经网络得到特征,得到的特征图送给后面的分类器和回归器。
2. 流程
- 预训练模型。选择一个预训练(pre-trained)神经网络(如AlexNet、VGG)。
- 重新训练全连接层。使用需要检测的目标重新训练(retrain)最后全连接层(connected leayer)。
- 提取proposals并计算CNN特征。利用选择性搜索(Selective Search)算法提取proposals(大约2000幅 images),调整(resize/warp)它们成固定大小,以满足CNN输入要求(因为全连接层的限制),然后将feature map保存到本地磁盘。
- 训练SVM。利用feature map训练SVM来对目标和背景进行分类(每个类一个二进制SVM)
- 边界框回归(bouding boxes Regression)。训练将输出一些校正因子的线性回归分类器。
3.效果
- R-CNN在VOC 2007测试集上mAP达到58.5%,打败当时所有的目标检测算法。
4.缺点

缺点原因:1.进行的2000次卷积 2.在图像上生成2000个左右的候选区
希望能实现端对端训练:同一个模型输入、同一个模型输出。
2)Fast R-CNN
1.定义
Fast R-CNN是基于R-CNN和SPPnets进行的改进。SPPnets,其创新点在于只进行一次图像特征提取(而不是每个候选区域计算一次),然后根据算法,将候选区域特征图映射到整张图片特征图中。(通过一个算法把之前2000个候选区域合并成一个,把2000个卷积合并成一个卷积)
笔记:把2000次候选区合成一次卷积
2.流程


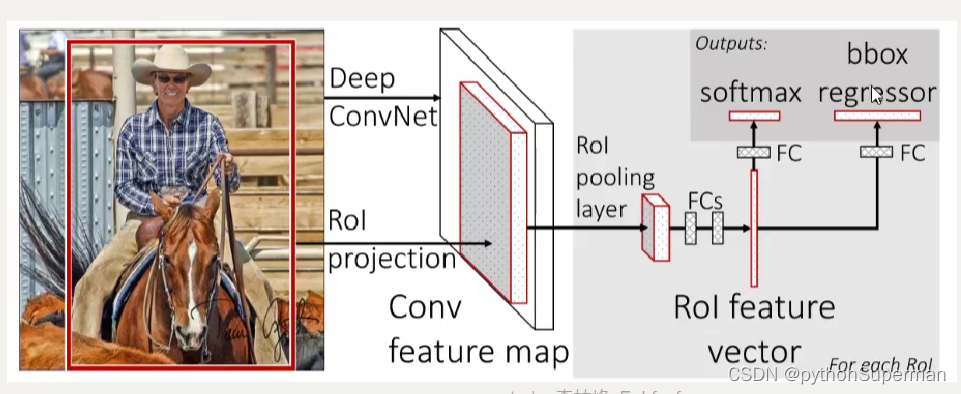
3.改进

4.缺点

3)Faster RCNN

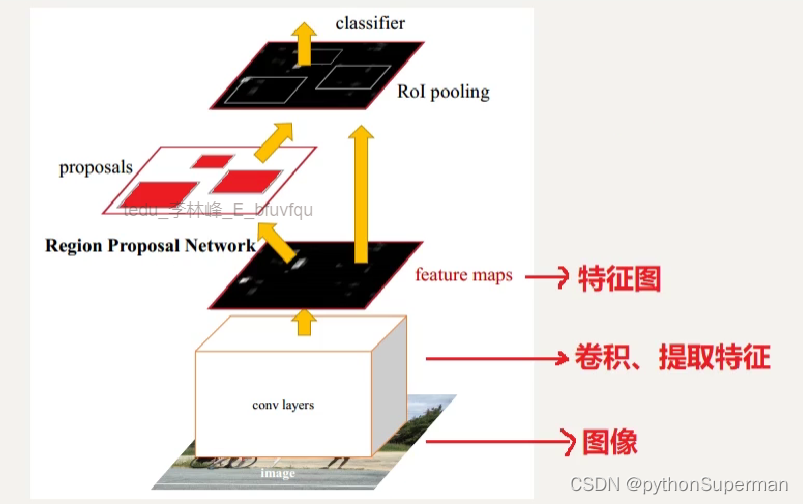
笔记:直接在特征图上产生候选区,其实就是做一个非常粗糙的预测。不要求准确率有多高,知识尽可能把可能存在目标物体的区域提取出来就是了。
预测那些区域可能存在目标物体,至于目标物体是什么,真正的有没有,置信度是多少,精确定位不管。这个方法很巧,就相当于进行了快速的搜索。
1.整体流程

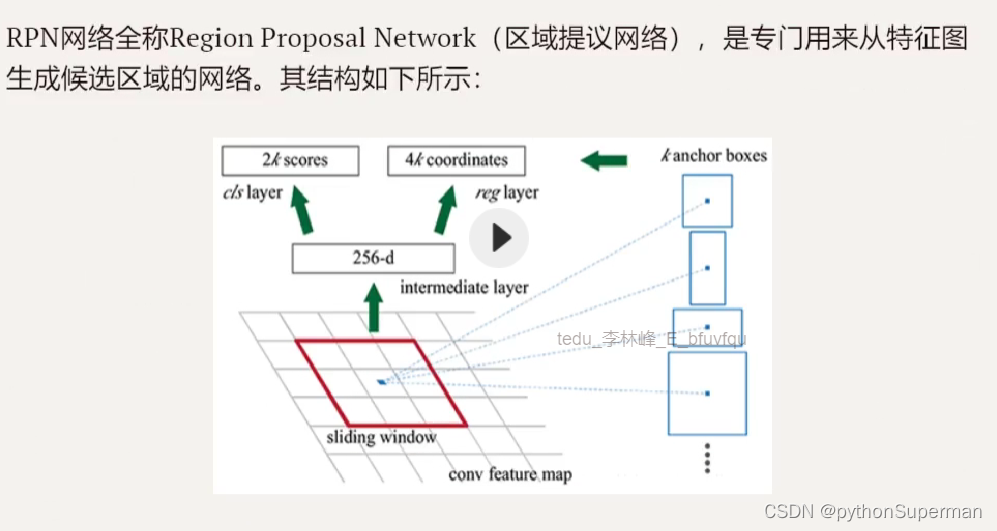
2.RPN网络(快速地产生预测)
3.Anchors
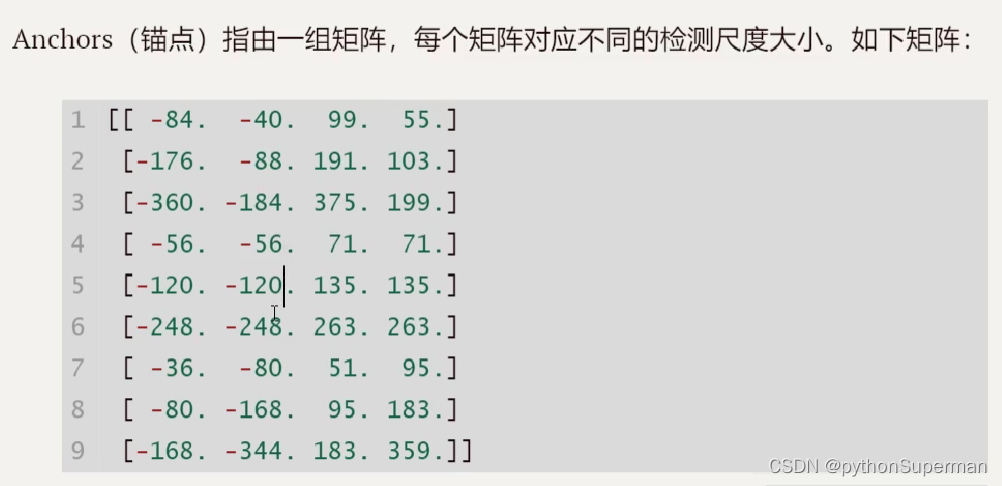
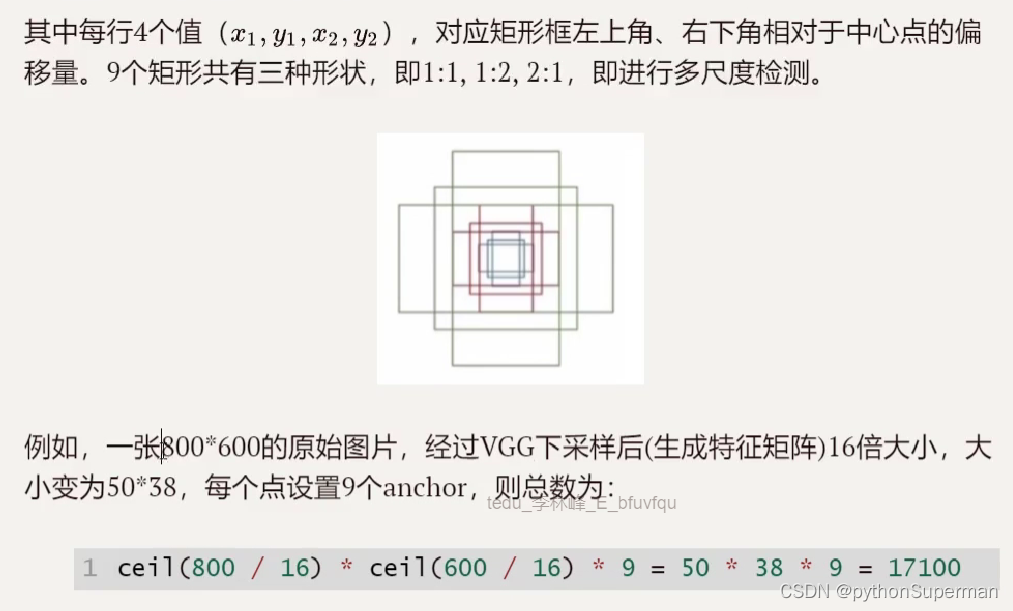
位置+高度+宽度




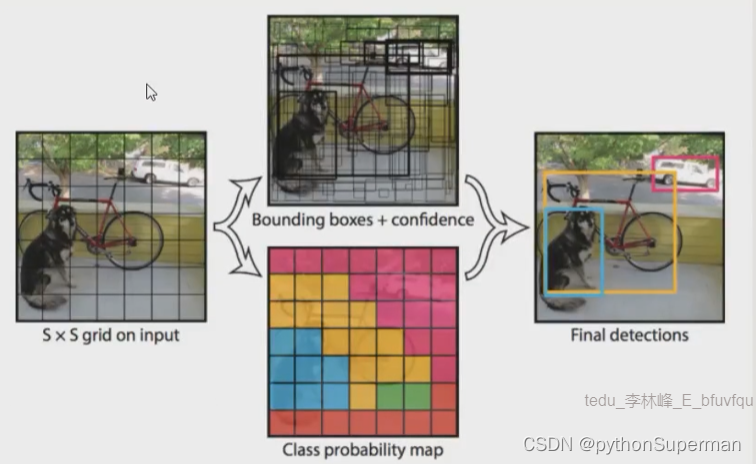
YOLOv1
1.基本思想




上一篇:Java运算符