实验2:Python数据预处理
创始人
2024-06-02 13:15:36
0次
实验2:Python数据预处理
文章目录
- 实验2:Python数据预处理
- 一、实验目的与要求
- 二、实验任务及答案
一、实验目的与要求
1、目的:
掌握数据预处理和分析的常用库Pandas的基本用法,学生能应用Pandas库实现对数据的有效查询、统计分析,以及进行必要的数据清洗或预处理,为进一步的机器学习应用做好必要的准备。
2、要求:
应用Pandas库对于给定的超市数据集进行必要的数据预处理和统计分析。
二、实验任务及答案
-
读取“超市营业额2.xlsx”中的数据,存入一个名为df的DataFrame对象中并显示前5行数据
import pandas as pd#1.读取“超市营业额2.xlsx”中的数据,存入一个名为df的DataFrame对象中并显示前5行数据 df = pd.read_excel('超市营业额2.xlsx') df.head()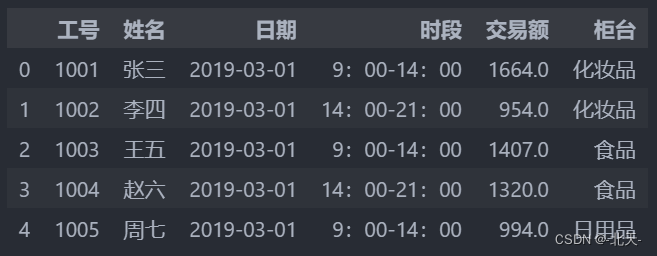
-
查看第1、3、5行中第2、4、6列的数据
df.iloc[[0,2,4],[1,3,5]]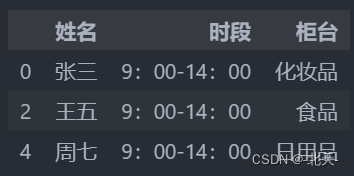
-
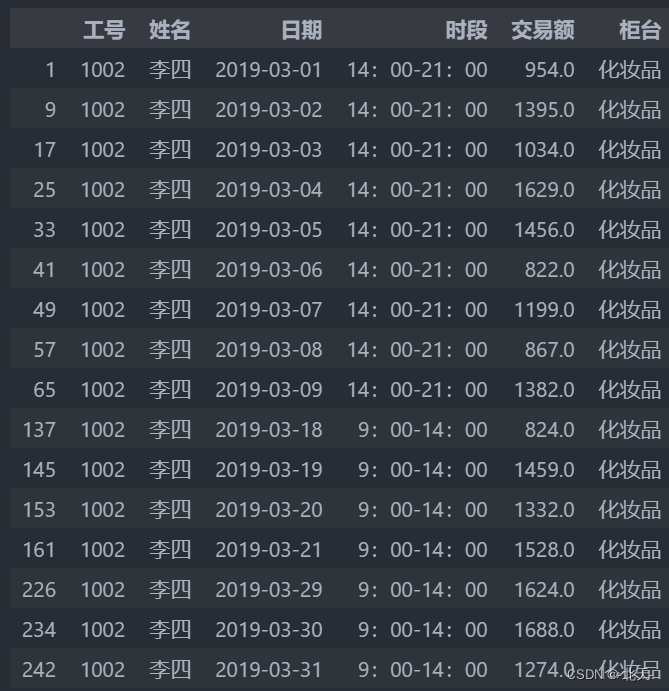
显示李四销售化妆品的情况
df.loc[(df['姓名'] == '李四') & (df['柜台'] == '化妆品')]
-
统计上半月的总交易额
df.loc[df['日期'] < '2019-03-16', '交易额'].sum()161393.0 -
使用df中的数据分组统计每个人的交易额平均值(保留2位小数),将统计结果放入dff变量中并显示该结果
dff = df.groupby('姓名')['交易额'].mean().round(2) dff姓名 周七 1195.45 张三 1529.74 李四 1249.57 王五 1472.30 赵六 1245.98 钱八 1322.72 Name: 交易额, dtype: float64 -
对dff中的交易额平均值进行降序排列
dff.sort_values(ascending=False)姓名 张三 1529.74 王五 1472.30 钱八 1322.72 李四 1249.57 赵六 1245.98 周七 1195.45 Name: 交易额, dtype: float64 -
使用df中的数据按类别统计每个人的交易总额
df.groupby(['姓名', '柜台'])['交易额'].sum()姓名 柜台 周七 化妆品 9516.0日用品 12863.0蔬菜水果 16443.0食品 8996.0 张三 化妆品 22975.0日用品 18629.0蔬菜水果 7265.0食品 9261.0 李四 化妆品 20467.0日用品 10104.0蔬菜水果 23263.0食品 4896.0 王五 化妆品 10112.0日用品 11357.0蔬菜水果 10473.0食品 26950.0 赵六 化妆品 12319.0日用品 23286.0蔬菜水果 2527.0食品 17937.0 钱八 日用品 11923.0蔬菜水果 18561.0食品 17134.0 Name: 交易额, dtype: float64 -
统计df中缺失值的个数
df.isnull().sum()工号 0 姓名 0 日期 0 时段 0 交易额 3 柜台 0 dtype: int64 -
找出df中存在的重复行
df[df.duplicated()]
-
读取超市营业额2.xlsx中Sheet3中的数据,并与df中的数据合并,然后分类统计每人的交易额
df3 = pd.read_excel('超市营业额2.xlsx', sheet_name='Sheet3') df3.head() df4 = pd.concat([df, df3]) df4.groupby('姓名')['交易额'].sum()姓名 周七 47818.0 孙九 0.0 张三 58130.0 李四 58730.0 王五 58892.0 赵六 56069.0 钱八 47618.0 Name: 交易额, dtype: float64
相关内容
热门资讯
保存时出现了1个错误,导致这篇...
当保存文章时出现错误时,可以通过以下步骤解决问题:查看错误信息:查看错误提示信息可以帮助我们了解具体...
汇川伺服电机位置控制模式参数配...
1. 基本控制参数设置 1)设置位置控制模式 2)绝对值位置线性模...
不能访问光猫的的管理页面
光猫是现代家庭宽带网络的重要组成部分,它可以提供高速稳定的网络连接。但是,有时候我们会遇到不能访问光...
不一致的条件格式
要解决不一致的条件格式问题,可以按照以下步骤进行:确定条件格式的规则:首先,需要明确条件格式的规则是...
本地主机上的图像未显示
问题描述:在本地主机上显示图像时,图像未能正常显示。解决方法:以下是一些可能的解决方法,具体取决于问...
表格列调整大小出现问题
问题描述:表格列调整大小出现问题,无法正常调整列宽。解决方法:检查表格的布局方式是否正确。确保表格使...
表格中数据未显示
当表格中的数据未显示时,可能是由于以下几个原因导致的:HTML代码问题:检查表格的HTML代码是否正...
Android|无法访问或保存...
这个问题可能是由于权限设置不正确导致的。您需要在应用程序清单文件中添加以下代码来请求适当的权限:此外...
银河麒麟V10SP1高级服务器...
银河麒麟高级服务器操作系统简介: 银河麒麟高级服务器操作系统V10是针对企业级关键业务...
【NI Multisim 14...
目录 序言 一、工具栏 🍊1.“标准”工具栏 🍊 2.视图工具...