[学习笔记]每天1小时学会数据分析、挖掘、清洗、可视化从入门到项目实战
每天1小时学会数据分析、挖掘、清洗、可视化从入门到项目实战
导读:如何成为一名合格的业务数据分析师?
文章目录
- 数据分析师职业解析
- 技术栈
- 能力解读
- 学历要求
- 数据分析发展前景
- 数据分析发展-薪酬水平
- 一、Excel基本操作(Tina的视频)
- 1.1 单元格
- 1.2 数据格式
- 1.2.1 自定义格式
- 1.2.2工具栏-条件格式
- 1.3 保护功能
- 1.4 快速输入数据
- 填充柄 - 鼠标左键下拉
- 利用自定义列填充
- 多个不连续单元格同数据
- 文本记忆输入
- 数据验证
- 1.5 导入数据
- 1.6 数据类型
- 1.7 文本转为数值
- 1.8 日期标准化
- 1.9 批量删除单引号
- 1.10 组合键Alt+=
- 1.11 快速选择区域
- 1.12 冻结单元格
- 1.13 选择单元格
- 1.14 数据的分类汇总
- 1.15 复制分类汇总结果
- 1.16 选择性粘贴-运算
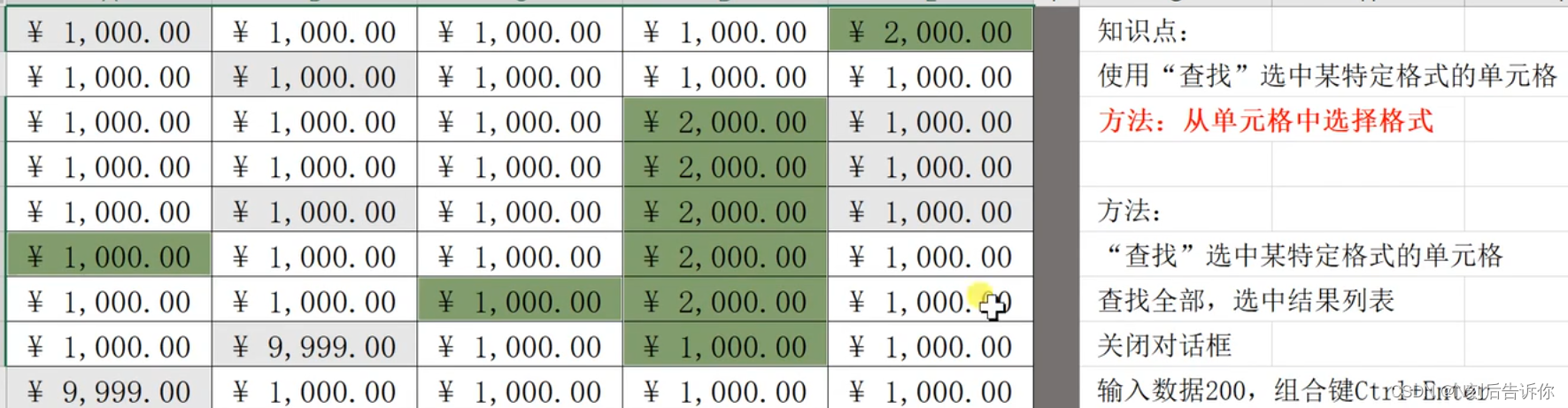
- 1.17 查找功能统计同填充色个数
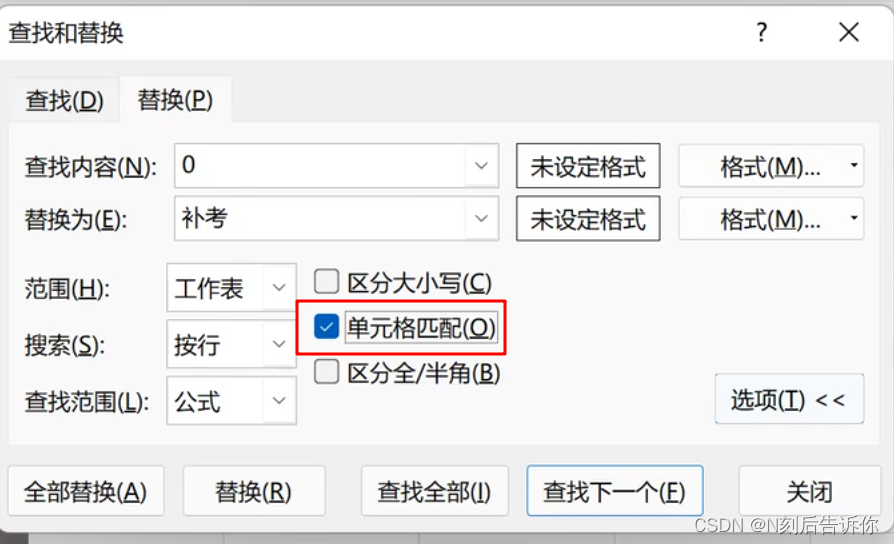
- 1.18 单元格匹配替换
- 1.19 利用辅助列-隔行插入1行空行
- 1.20 选择性粘贴,将两列数据合为一列
- 一、补充Excel(ailsa的视频)
- 1.21 第一课
- 最智能的快捷键ctrl+e
- 文本拼接&
- 1.22 公式与函数
- 1.22.1 地址引用
- 1.22.2 函数
- 1.23 数据透视表
- 1.23.1 数据透视表
- 1.23.2 注意事项
- 1.23.3 常用功能
- 1.24 图表
- 1.25 数据分析流程
- 1.25.1 数据清洗
- 二、Jupyter notebook
- 2.1 单元格状态
- 2.2 单元格的编辑模式
- 2.3 单元格操作
- 2.4 运行
- 2.5 帮助文档
- 2.6 魔法指令
- 2.7 IPython输入输出历史
- 三、Numpy
- 3.1 普通列表和Numpy中的数组ndarray对象的区别
- 3.2 ndarray的构造方法
- 3.3 ndarray的访问方法
- 3.4 二维的构造与访问
- 3.5 快速构造高维数组
- 四、pandas
- 4.1 pandas的基本数据类型
- 4.2 修改索引
- 4.3 excel和csv文件的读写操作
- 4.4 绝对路径和相对路径
- 4.5 pandas对象访问与筛选
- 4.6 pandas数据运算
- 4.7 pandas映射处理
- 4.8 pandas空值填充和查找
- 五、Matplotlib数据可视化基础
- 5.1 折线图plt.plot()
- 5.2 条形图(柱状图)plt.bar()
- 5.3 散点图plt.scatter()
- 5.4 pandas库的快速绘图技巧
- 5.5 添加文字说明
- 5.6 绘制多图
- 六、pandas文件汇总
- 七、业务数据分析思维
- 7.1 业务指标
- 7.2 常用的分析方法
- 7.3 逻辑树分析
- 7.4多维度拆解分析
- 7.5 对比分析
- 7.6 归因分析(假设检验法)
- 八、统计学
- 九、商业智能 Power BI
- 9.1 Power BI简介
- 9.2 PowerBI实操1_整体报表建立
- 9.2.1 功能区介绍
- 9.2.2 读取文件夹并合并文件
- 9.2.3 加载MySQL
- 9.2.4 excel的powerquery编辑器
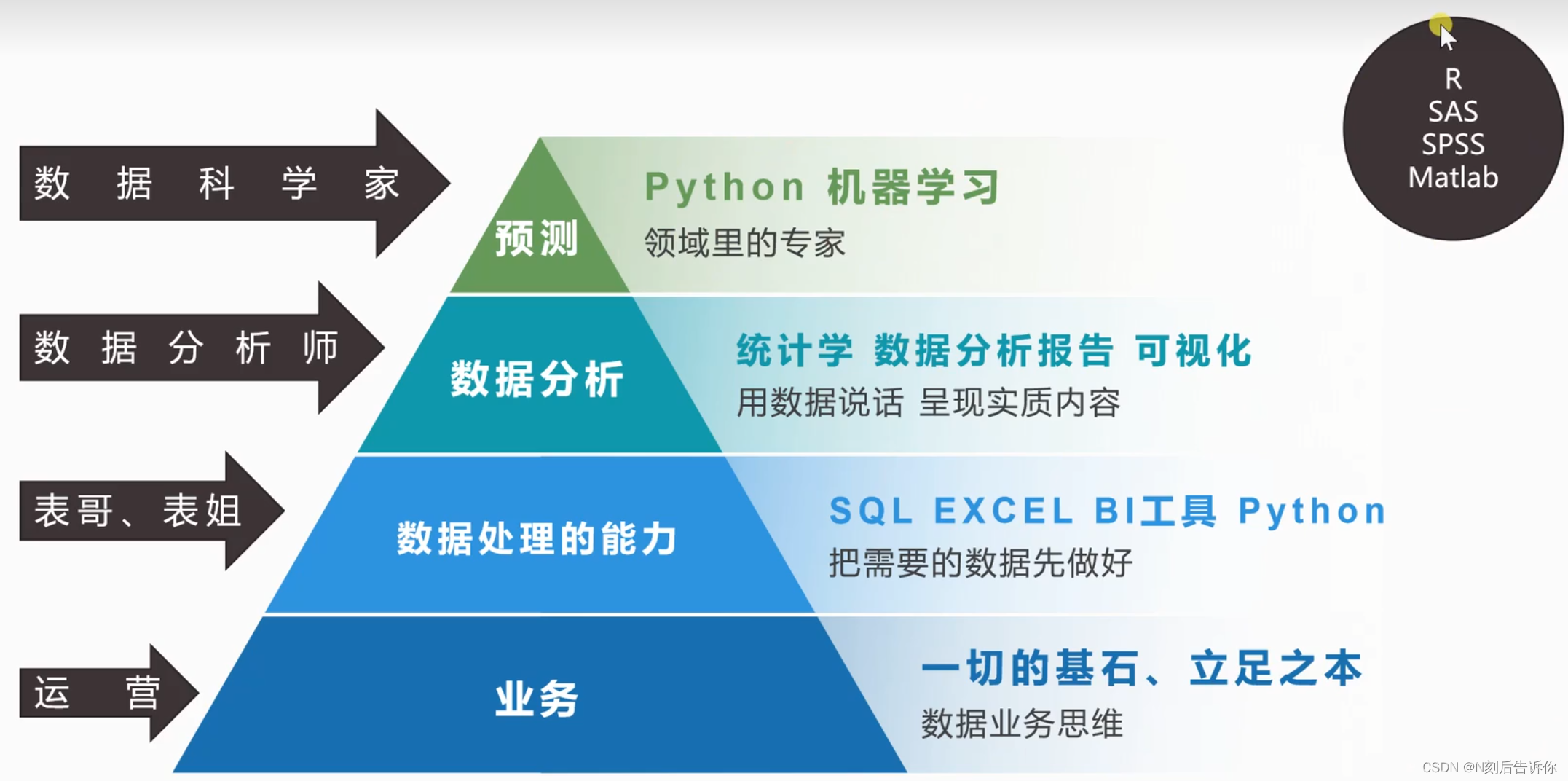
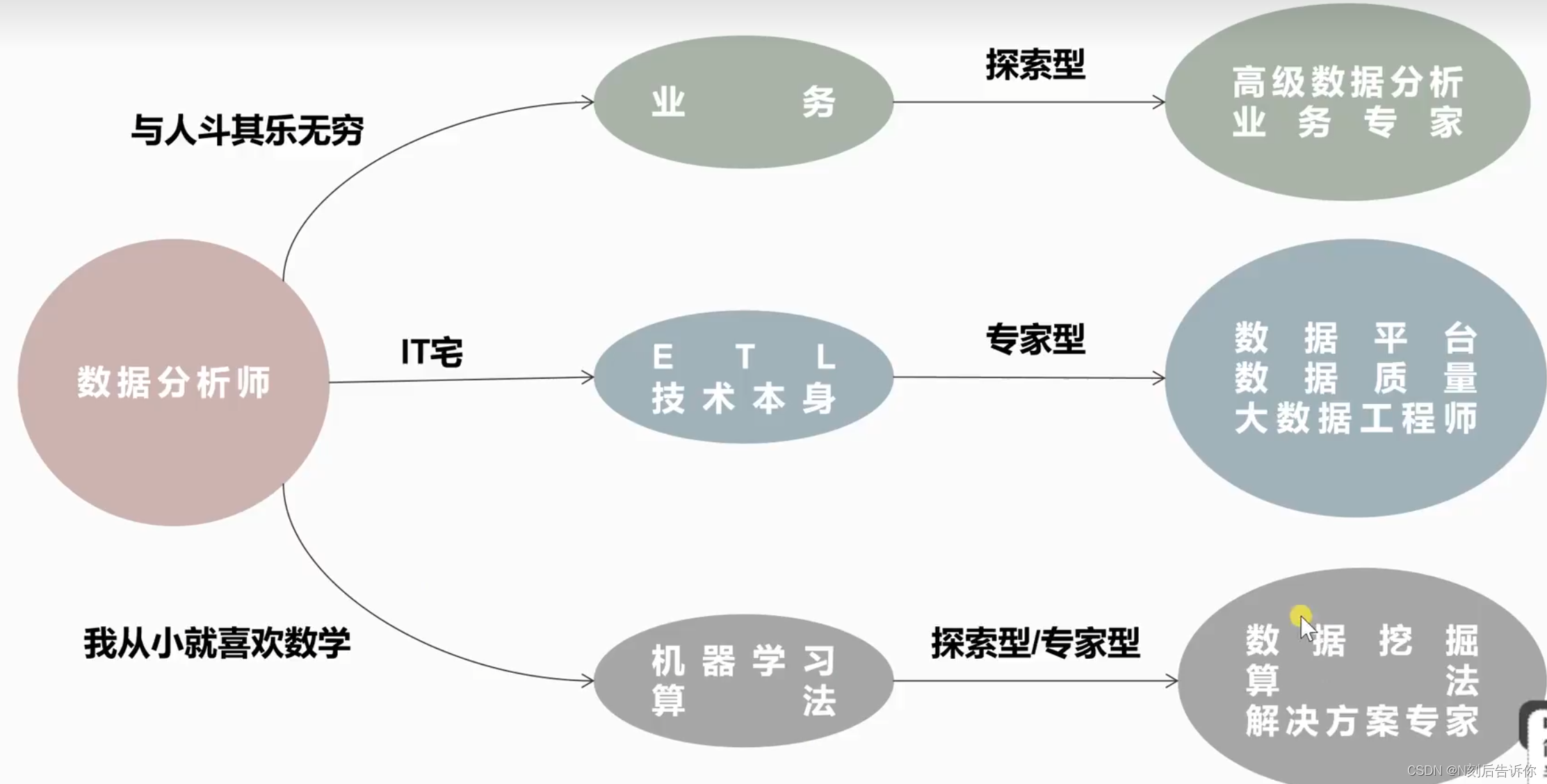
数据分析师职业解析
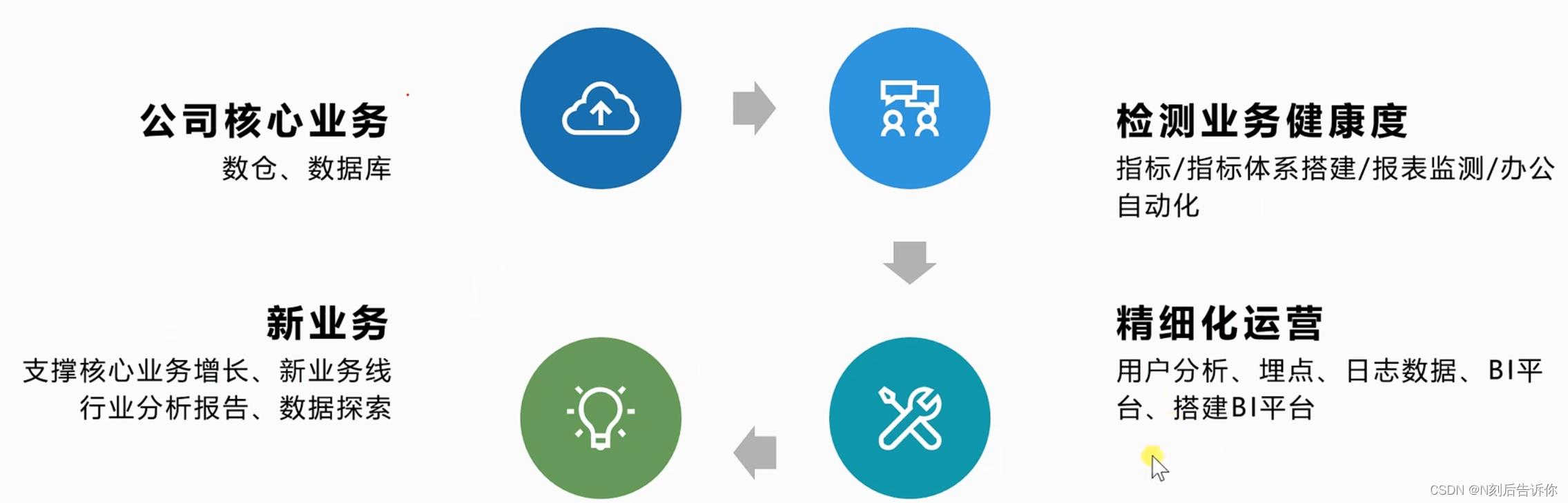
技术栈
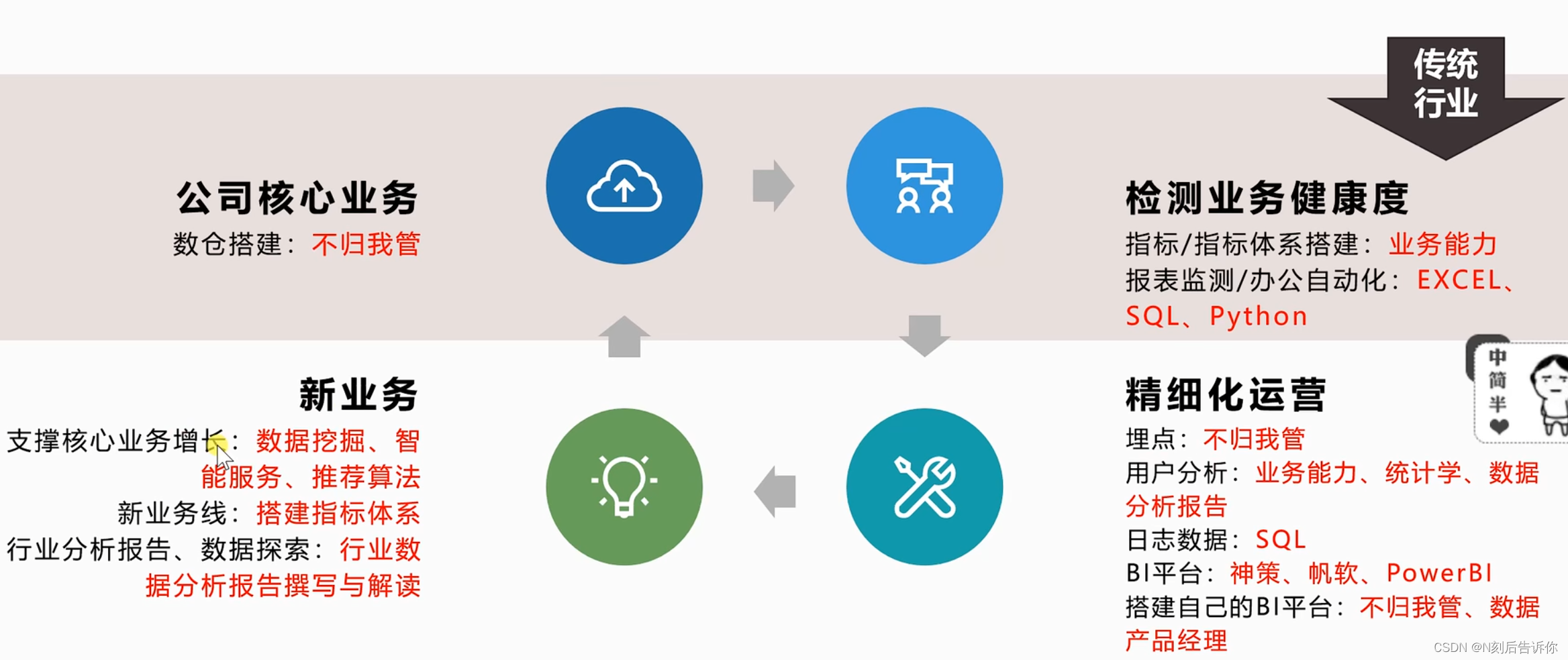
能力解读
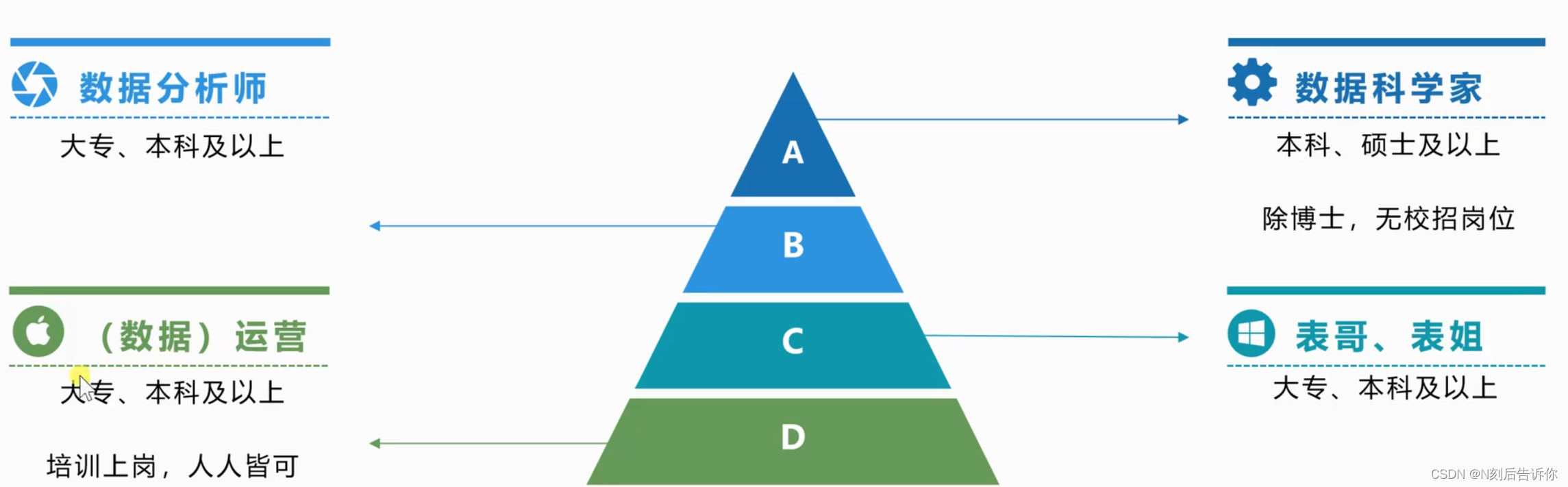
学历要求
数据分析发展前景
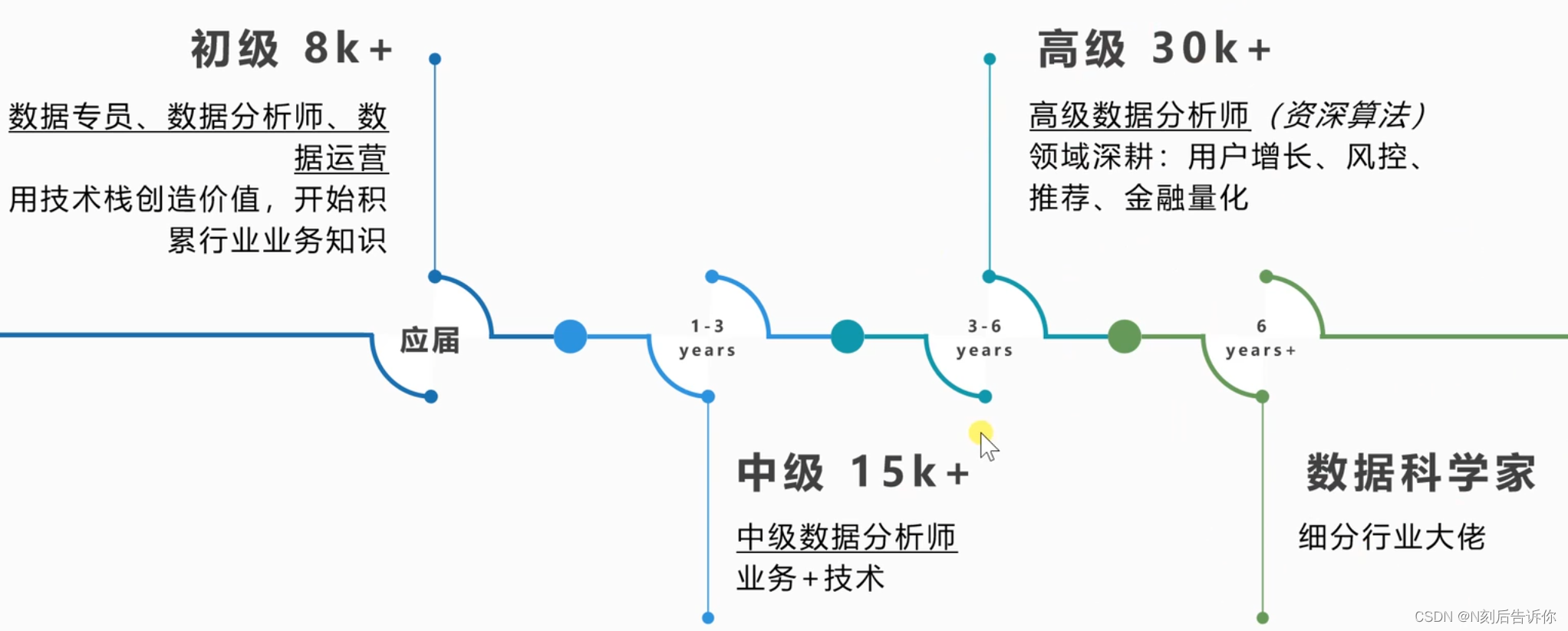
数据分析发展-薪酬水平
一、Excel基本操作(Tina的视频)
知识点:
- 数据格式、单元格格式
- 函数:汇总统计、文本处理、时间计算、查找与匹配
- 可视化
- 数据透视表
Power Query会在Power BI中讲
在学了Python之后,放弃VBA(所以不必要学)
1.1 单元格
选择模式,输入模式,编辑模式(双击可以进入)。
按F2可以在编辑和输入模式之间切换。
"ctrl+shift+下"可以用于查看某一列是否有空缺。
“alt+enter”可以在单元格内换行。
在格式可以选择自动调整列宽,行高。
1.2 数据格式
文本格式,默认靠左。
数值格式,默认靠右。
有些函数针对文本,有些针对数值
1.2.1 自定义格式
可以自定义格式。
- 设置
##“次”,则输入数值25,会显示25次,但是仍然是数值格式。 - 设置
[>=75][蓝色]##"次";[<75][红色]##"次";,则大于等于75会显示蓝色,且后面带上单位次。
这改的是数值本身的颜色。
# 代表原本的数据格式,0代表数值格式,0000表示不足位则补齐4位。

1.2.2工具栏-条件格式
数据条、色阶、规则
1.3 保护功能
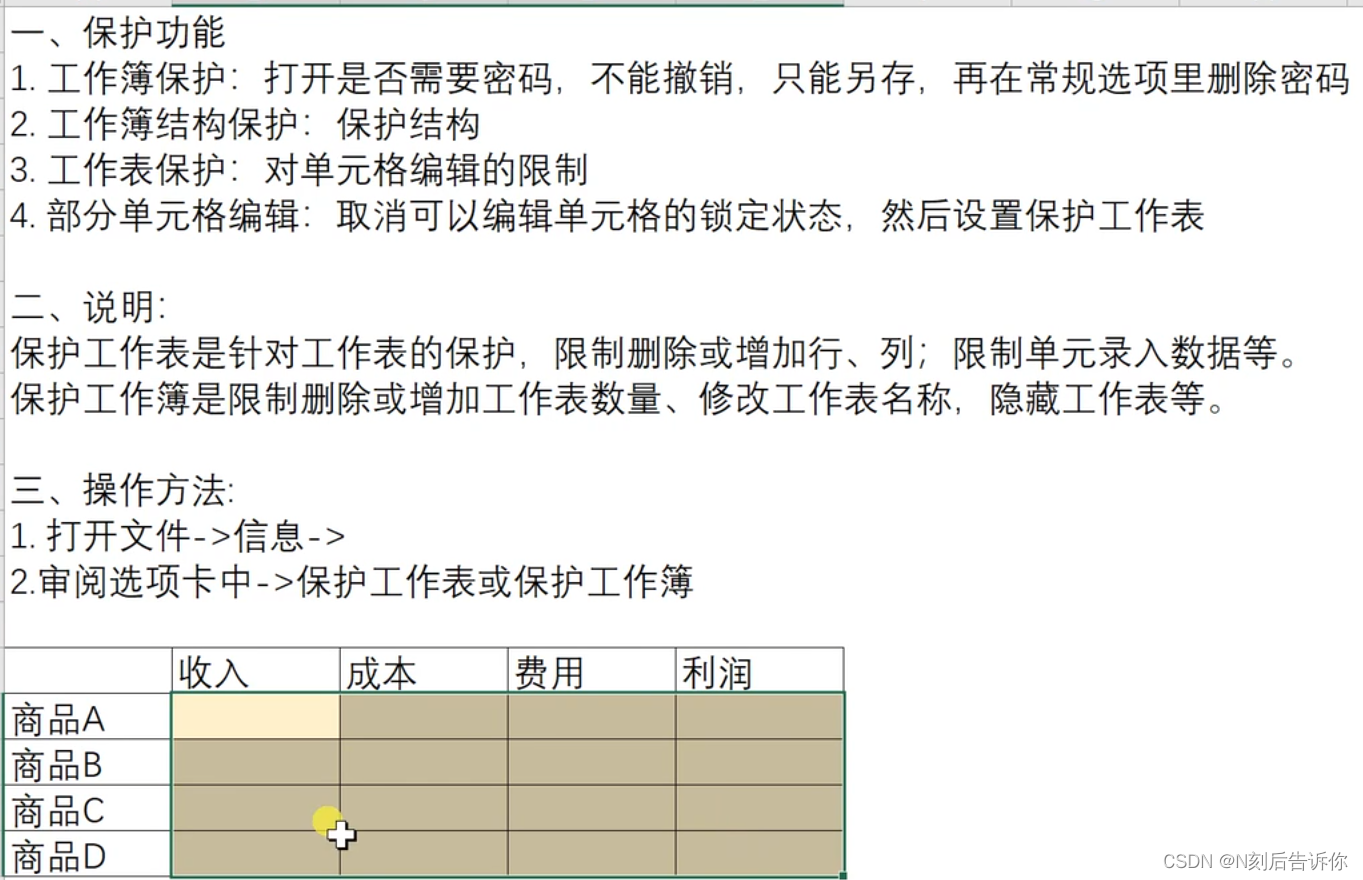
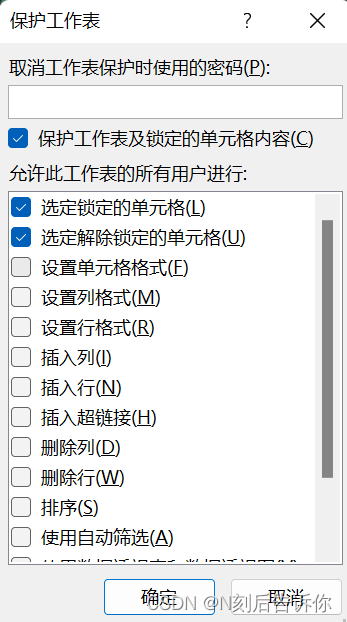
- 保护工作表
选择审阅,选择”保护工作表“
- 保护工作簿
选择审阅,选择”保护工作簿“
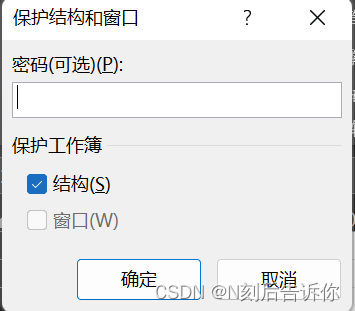
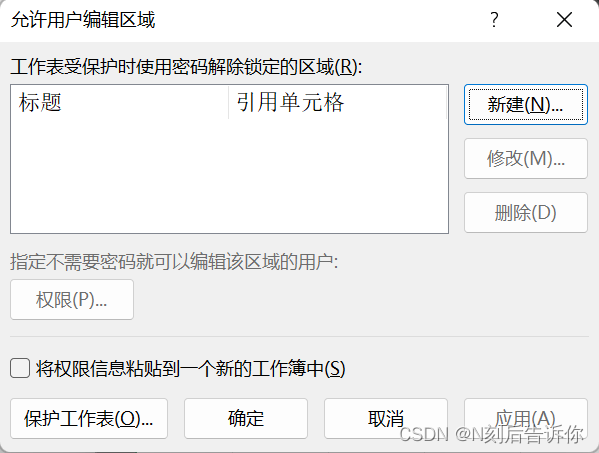
- 部分单元格编辑
选择审阅,选择”允许编辑区域“
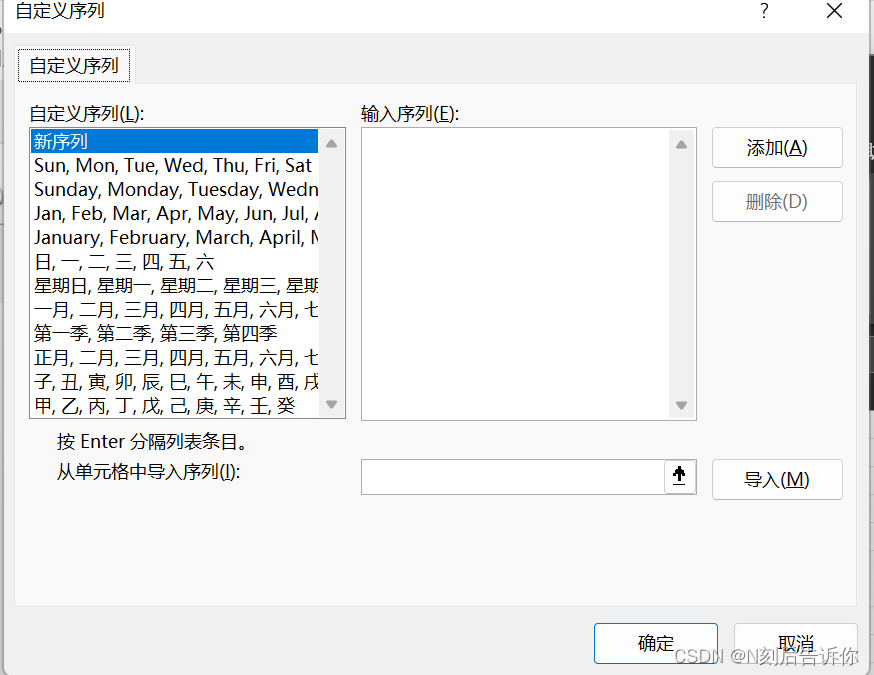
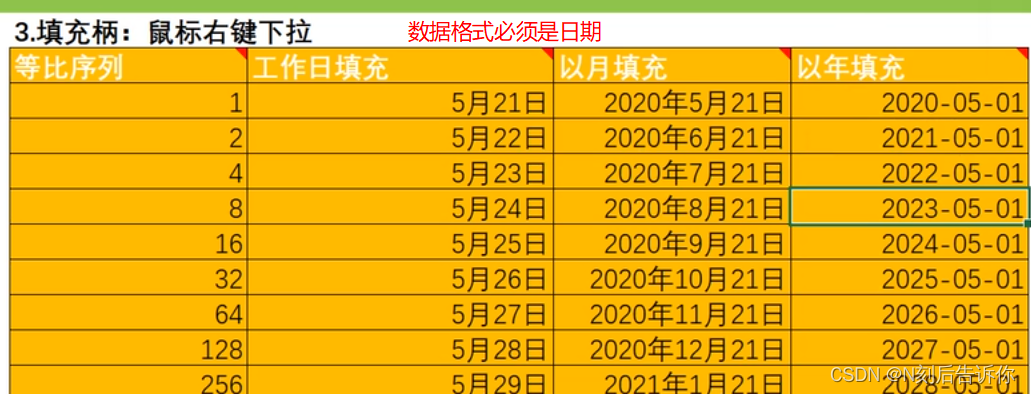
1.4 快速输入数据
填充柄 - 鼠标左键下拉
利用自定义列填充

多个不连续单元格同数据

ctrl+鼠标左键选中多个不连续单元格,然后输入内容,再ctrl+回车补全所有选中单元格。
这个方法也可以用于删除不连续单元格。
文本记忆输入

数据验证
在数据选项卡,选择数据验证。
1.5 导入数据

注意,如果数据源丢失了,那么表格信息也就没了。
如果数据源修改了,那么表格信息刷新之后也能看到修改。要点击表设计选项卡的刷新。
1.6 数据类型
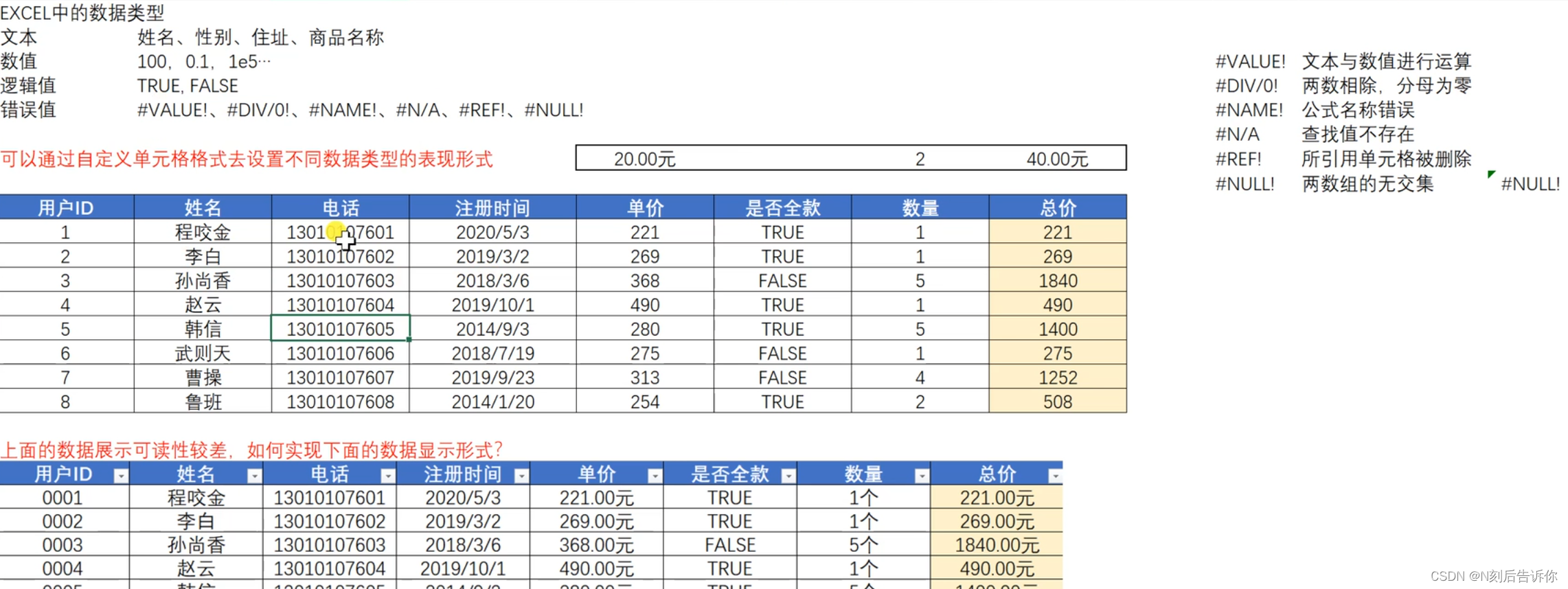
1.7 文本转为数值
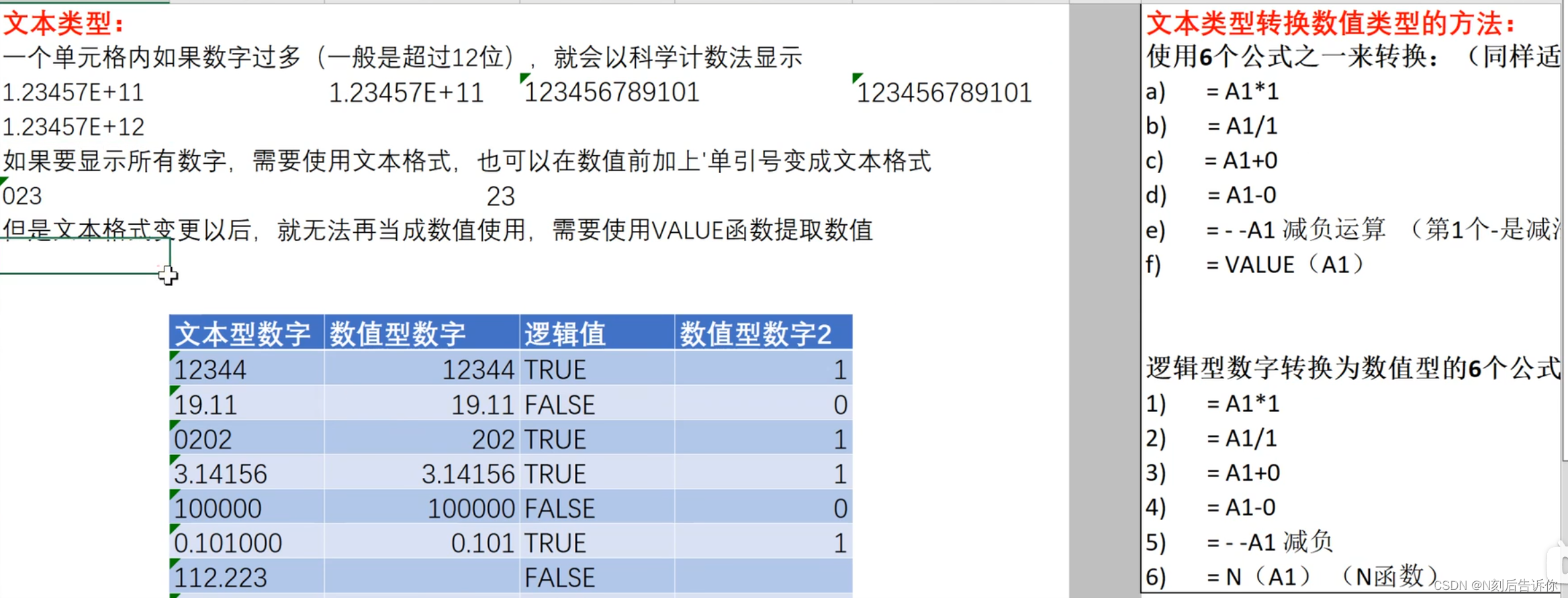
在单元格前面加上英文格式的单引号,则会默认居左。
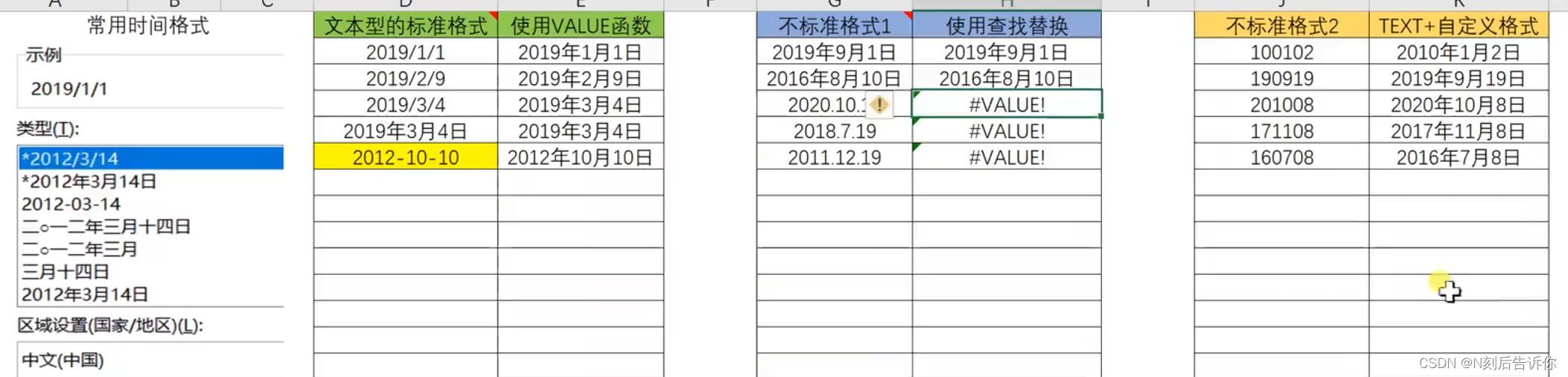
1.8 日期标准化
1.9 批量删除单引号
利用格式刷
1.10 组合键Alt+=
Alt+=会自动对上面的元素求和。
1.11 快速选择区域
"ctrl+shift+方向"可以快速选择某个方向上的单元格。
这个方法可以被用来找空缺。
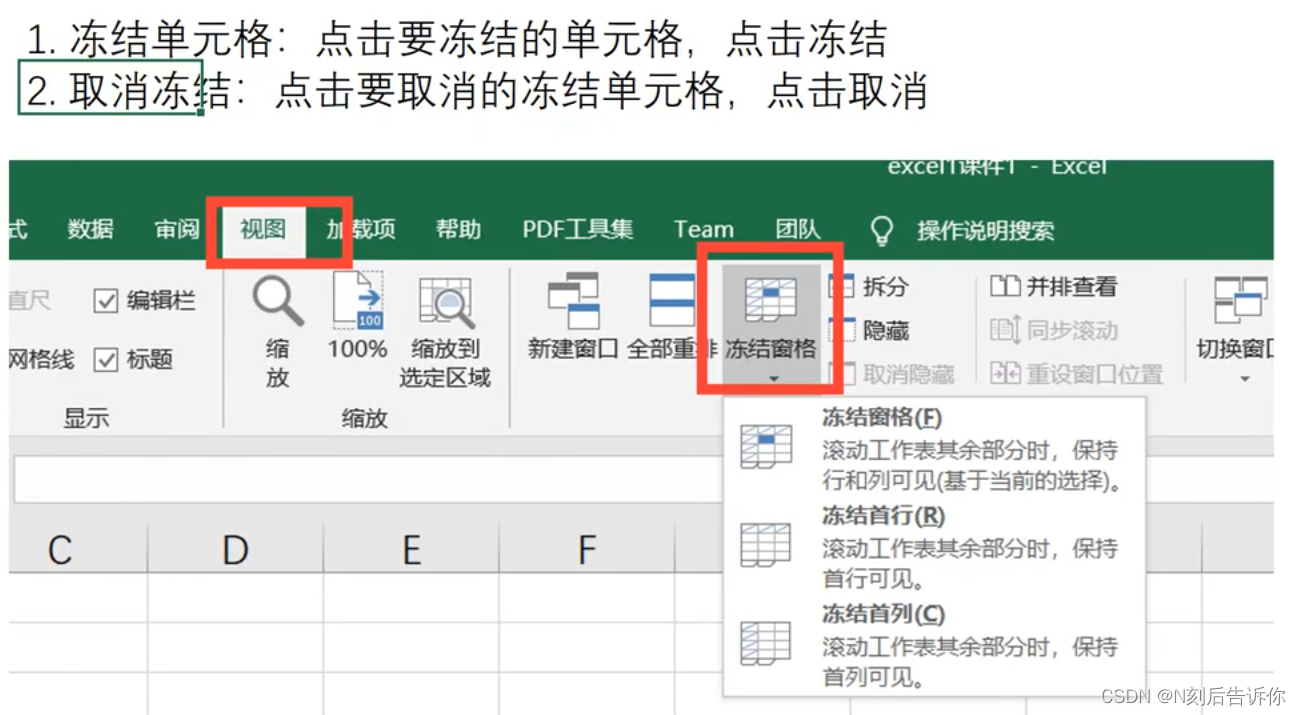
1.12 冻结单元格
1.13 选择单元格
如果单元格有空缺,则计算平均值时,分子分母都不会记录这个单元格。
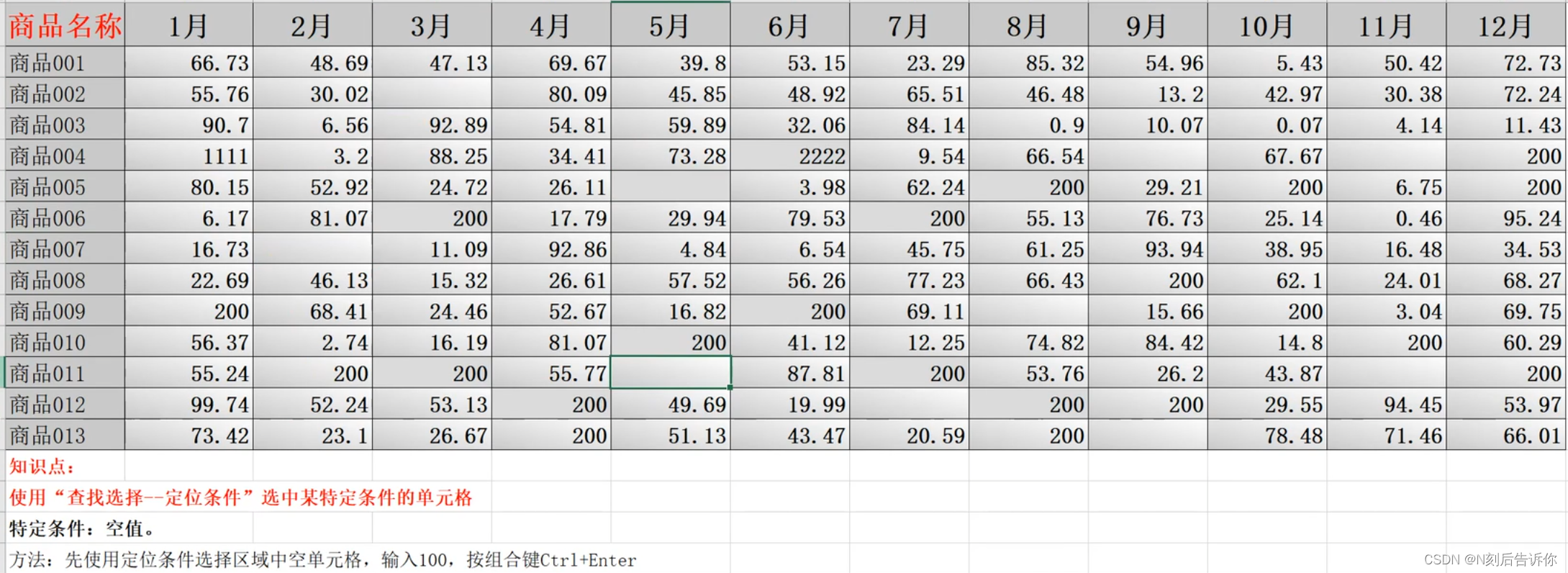
1.14 数据的分类汇总
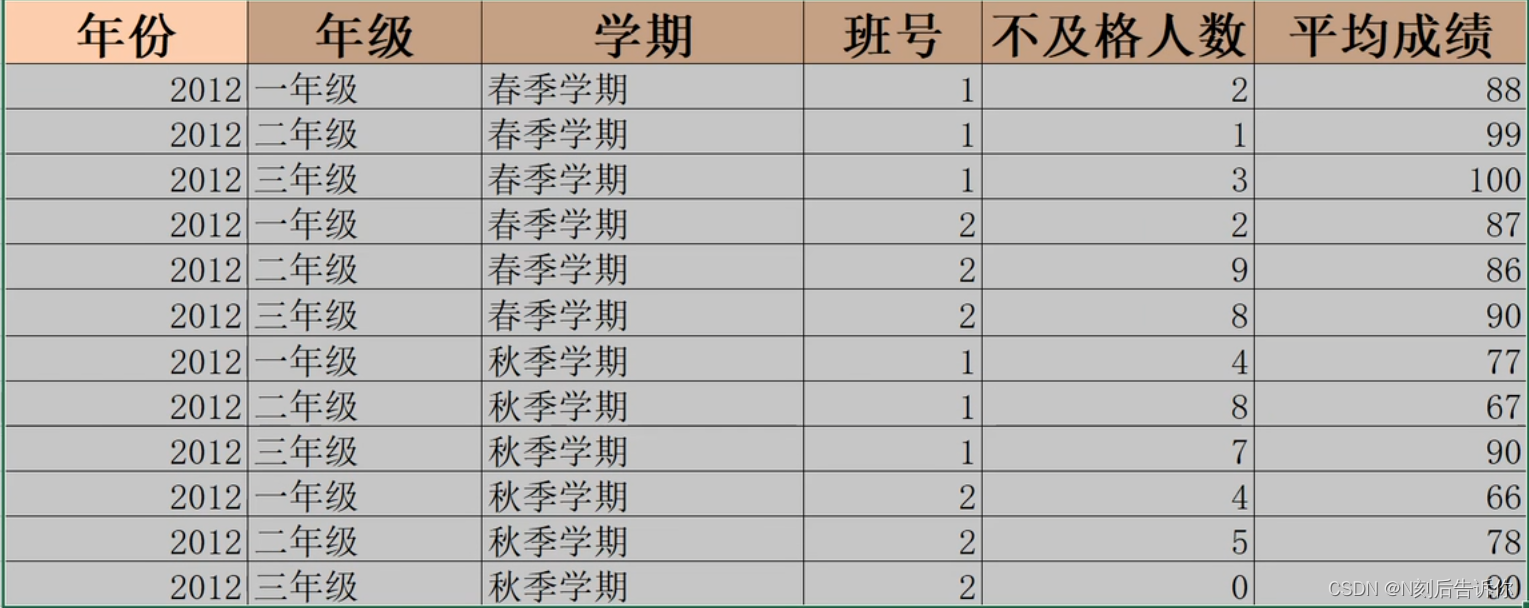
在数据选项卡-选择分类汇总
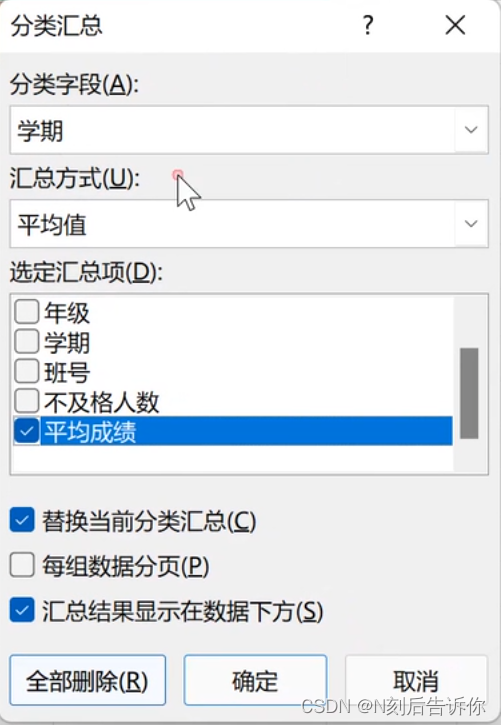
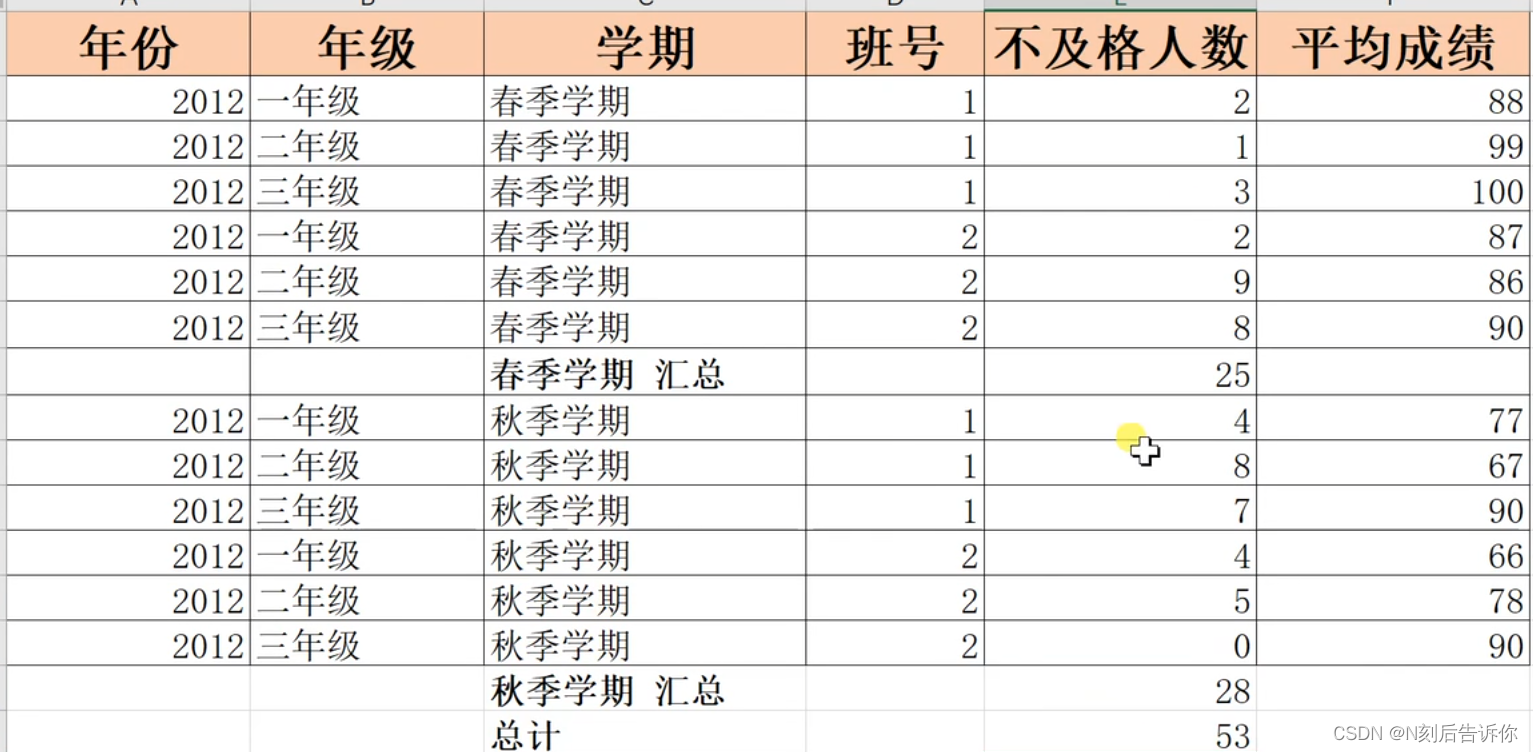
1.15 复制分类汇总结果
如果直接复制1.14中的分类汇总结果,即使把分级隐藏了,还是会复制隐藏的单元格。
这时候可以通过”查找和选择“,然后选择”可见的单元格“,这样再进行复制,就不会复制隐藏的单元格了。
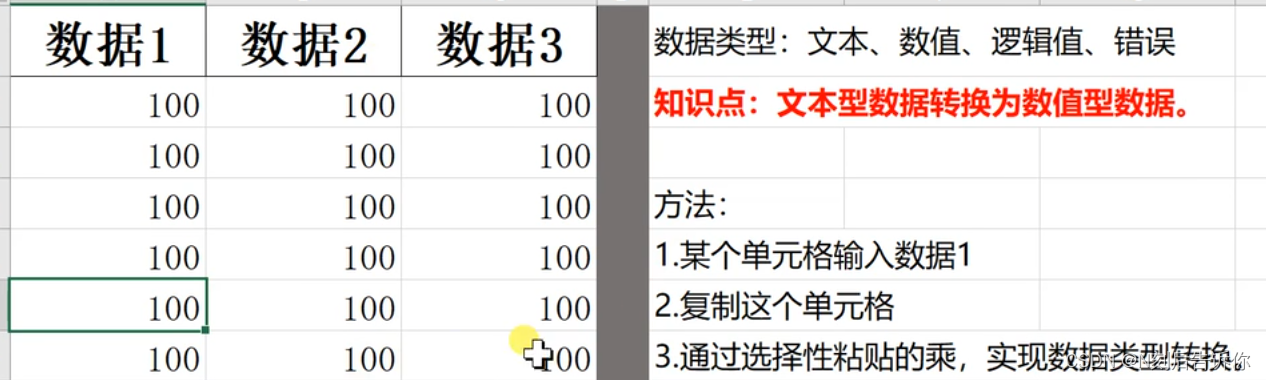
1.16 选择性粘贴-运算

1.17 查找功能统计同填充色个数
1.18 单元格匹配替换

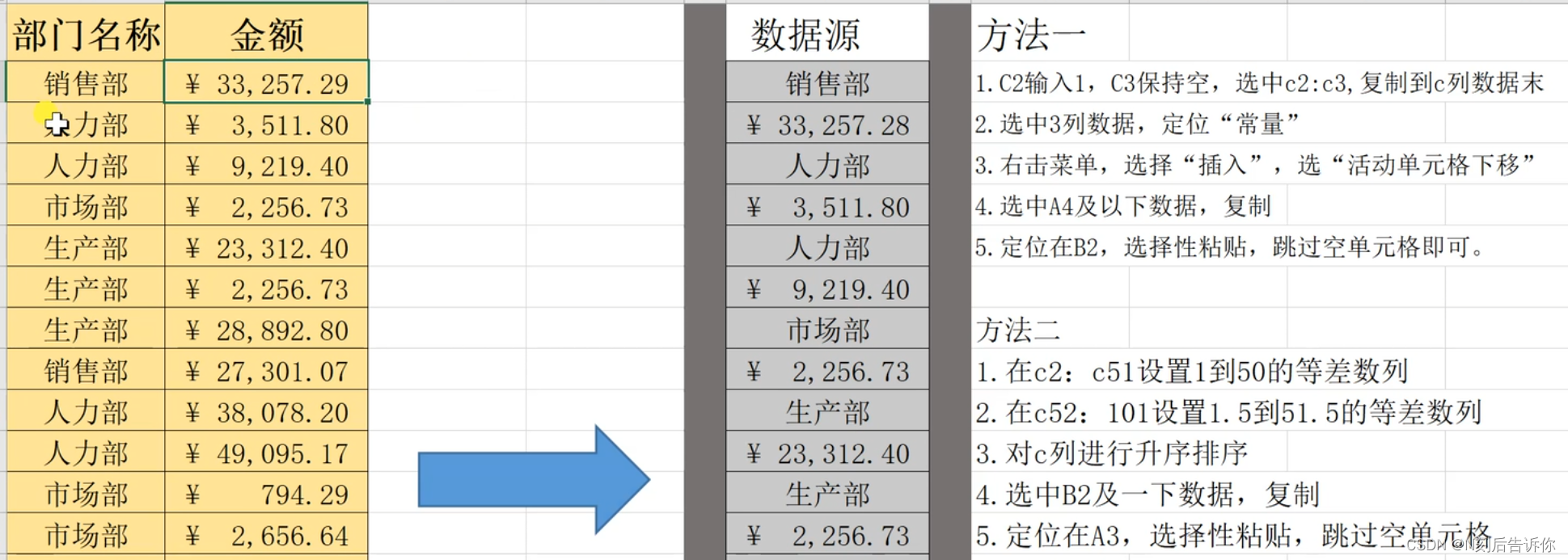
1.19 利用辅助列-隔行插入1行空行
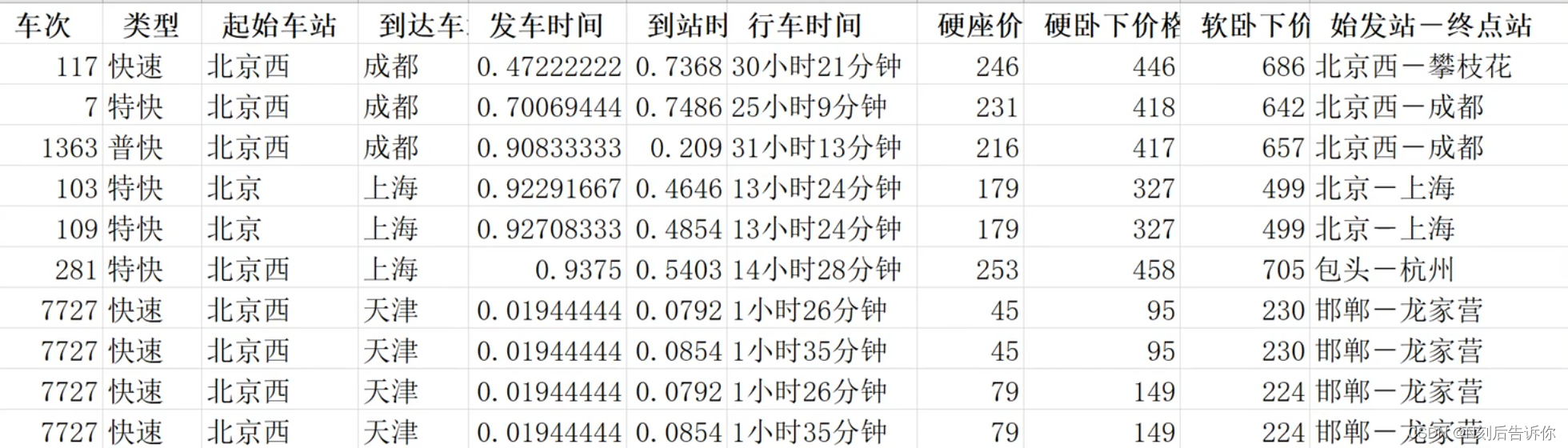
如何使上表实现一行有数据,一行空,一行有数据的效果?
使用辅助行,先添加等差数列1,2,…
然后再在结尾的空行处,添加1.1,2.1,…
最后对辅助行使用升序排序,然后删掉辅助列,就达到效果了。
1.20 选择性粘贴,将两列数据合为一列
一、补充Excel(ailsa的视频)
1.21 第一课
最智能的快捷键ctrl+e
智能填充
文本拼接&
1.22 公式与函数
ctrl+~可以切换显示原始公式或者值。
1.22.1 地址引用
相对引用:你变它就变,如A2:A5
绝对引用:如$A2混合引用:如2 混合引用:如2混合引用:如A2,A$2
$在谁前面,谁就不能动了,按F4可以在相对引用,绝对引用,混合引用之间互相切换
1.22.2 函数
- 逻辑函数
IF(判断条件,True的结果,False的结果) # 判断
AND(条件,条件) # 与
OR(条件,条件) # 或
NOT(条件) # 非
excel中对文本的引用必须是双引号
- 文本函数
MID(文本,开始字符下标,几个字符长度) # 取子串
LEFT(文本,几个字符长度) # 从左取子串
RIGHT(文本,几个字符长度) # 从右取子串
LEN(文本) # 文本长度
TEXT(文本,文本格式) # 数字转化文本格式
# 文本格式如"yyyy-mm-dd",可以参考单元格格式中的自定义的书写方法
REPLACE(原始文本,开始字符下标,几个字符长度,替换的内容) # 替换特定位置处的文本
- 统计函数
# 简单的
INT() # 向下舍数取整
MOD(除数,被除数) # 求余数
ROUND(数值,几位小数) # 四舍五入,精确到指定小数位
AVERAGE(一组数据) # 求平均
MAX(一组数据) # 求最大
MIN(一组数据) # 求最小
SUM(一组数据) # 求和
COUNT(一组数据) # 数值计数
# 稍微有点难度的
SUMIF(条件区域,条件,求和的数据区域) # 条件求和
SUMIFS(求和的数据区域,条件区域1,条件1,条件区域2,条件2,...) # 多条件求和
COUNTIF(条件区域,条件) # 条件计数
COUNTIFS(条件区域1,条件1,条件区域2,条件2) # 多条件计数
- 查找与引用函数
VLOOKUP函数的应用场景:数据源是不同的表,但是格式是类似的,想归纳到一个表。
返回查找区域中查找对象所在行的某个值。
VLOOKUP(查找对象(如姓名),查找区域(如姓名列和值列),得到哪一列的值,查找方式):垂直方向查找
# 查找对象必须在查找区域的第一列中,否则找不到
# 查找区域一般需要绝对引用
# 查找方式分为近似匹配(TRUE或1)和精确匹配(FALSE或0),一般采用后者
MATCH函数的应用场景:返回查找对象在查找区域中的位置
MATCH(查找对象, 查找区域,查找方式):查找函数
- 日期函数
TODAY() # 当前日期
NOW() # 当前日期和时间
DATE(年,月,日) # 组合得到给定的日期
DATEDIF(开始时间,结束时间,单位) # 计算日期差
# 单位是“D”表示天,“M”表示月,“Y”表示年
YEAR() # 求年
MONTH() # 求月
DAY() # 求日
1.23 数据透视表
1.23.1 数据透视表
当跨表引用数据时,会在引用前加上"表名+!"
- 数据透视
步骤1:鼠标放在数据区域
步骤2:点击“插入选项卡”,点击“数据透视表”
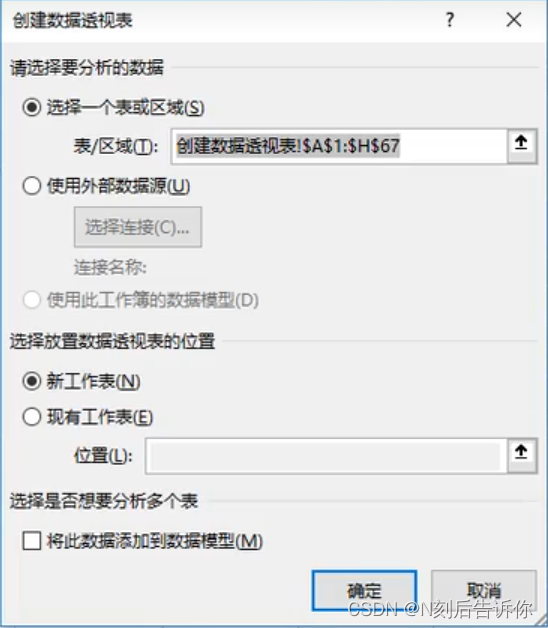
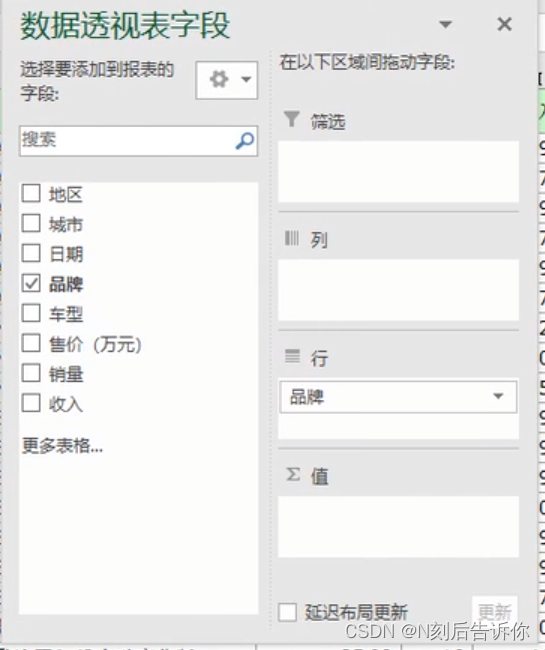
步骤3:将品牌拖到行方向上,将销量拖到值方向,收入拖到值方向。
值字段设置中可以选择要采取的聚合操作,如求和,求平均等。
1.23.2 注意事项
- 列名不能为空
- 不能重复
- 不能有空行,所以要填充空缺值
- 不能有合并单元格
- 数据类型保持一致,特别是数值型
1.23.3 常用功能
点到数据透视表,会出现上下文选项卡。
- 数据记错了,需要更高,该如何更新数据透视表?
答:如果数据透视表的源数据更新了。数据透视表需要在上下文选项卡里面的分析选项卡中,点击“全部刷新”,才能刷新创建的数据透视表。 - 源数据内容新增了一行或一列,数据透视表该怎么办?
答:如果在数据内部增加数据,只需要刷新即可。但是在底部或者边缘添加行或者列,刷新也没用。因为数据源的范围没有包含这些新的列或者行,所以需要点击“刷新”旁边的“更改数据源”。 - 想要计算结果按照一定顺序排列怎么办?
答:点击行标签,然后选择“其他排序选项”。 - 想要在数据透视基础上增加计算列?
答:选中要计算的列,然后点击“数据透视表工具”选项卡下面的“分析”选项卡,再点击“字段、项目和集”,点击“计算字段”。 - 想要在数据透视基础上增加计算行?
答:选中要计算的行,然后点击“数据透视表工具”选项卡下面的“分析”选项卡,再点击“字段、项目和集”,点击“计算行”。 - 如何动态筛选数据透视内容?
答:使用切片器。点击”分析“选项卡,点击”插入切片器“,然后选择要切片的标签。选中切片器,再按Delete键就可以删除切片器。
在“数据透视表工具-分析”选项卡下,可以点击”字段列表“,”+/-按钮“来修改透视表的显示样式。在“数据透视表工具-设计”选项卡下,点击报表布局,点击”以表格形式显示“。在分类汇总里可以点击”不显示分类汇总“。
在”分析“里面可以点”选项“,在布局和格式里,可以选择”合并且居中排列带标签的单元格“。
- 如何根据某个类别拆分多个工作表?
答:将”地区“拖到”数据透视表字段列表“的”筛选“中,然后点击”分析“,”选项“,”显示报表筛选页“。这样”东北“和”华北“的数据,分别会生成一个工作表。 - 如何合并多个Excel表?
答:需要用到多重合并对话框。这个功能在前台的功能区没有,需要设置。
点”文件“选项卡,”选项“,自定义功能区,在”下拉位置选择命令“中下拉中,点击”不在功能区“的命令,找到”数据透视表和数据透视图向导“,将它添加到”数据分组“下面的”新建组“里面。这样在功能区就能看到”数据透视表和数据透视图向导“
点击”数据透视表和数据透视图向导“,然后点击”多重合并计算数据区域“,点击下一步,再点击”创建单页字段“,再点击下一步,选择数据区域,点击添加。
前提是内容和格式极度相似
- 如何建立数据透视图?
答:点击分析,点击数据透视图,然后选择图表类型(如柱状图)。
1.24 图表
略
1.25 数据分析流程
- 分析流程
1.明确需求
2.确定思路
3.处理数据(数据清洗,大部分时间都在这里)
4.分析数据
5.展示数据,攥写报告
6.效果反馈
1.25.1 数据清洗
- 选择子集
去掉不需要的列 - 列名重命名
- 删除重复值
- 缺失值处理
使用countif函数来查看是否有空值。
缺失值的处理方案:
- 如果数据量比较少,不太重要,直接删除
- 如果是文本型,我们单独人为判断填写
- 填充缺失值,对于数值型,均值或者中位数填充
- 一致化处理
二、Jupyter notebook
2.1 单元格状态
- 状态
选中状态:单元格左侧变蓝色,此时可以对单元格本身进行操作
编辑状态:单元格左侧变绿色,此时光标在单元格内部闪动,可以对内部文本进行操作 - 状态切换
选中状态-》编辑状态:1.回车 或2.鼠标点击单元格内部
编辑状态-》选中状态:1.ESC 或2.鼠标点击单元格外侧
2.2 单元格的编辑模式
- 编辑模式
Code代码模式,Markdown文本模式 - 模式切换(两种方法)
1.选中状态下,按y切换到code模式,按m切换到markdown模式
2.鼠标在上方下拉列表中手动切换
2.3 单元格操作
前提:单元格处于选中状态
1.新增cell:
按a:在选中单元格上方插入一个新的cell
按b:在选中单元格下方插入一个新的cell
2.删除cell:
按dd:删除选中cell
按x:剪切cell
3.复制cell
按c:复制选中cell
4.粘贴
按v:粘贴已复制的cell到选中的cell的正下方
2.4 运行
Ctrl+Enter运行选中单元格,然后继续选中当前单元格
Shift+Enter运行选中单元格,并在其下方选中一个单元格,如果下方没有单元格,则新增一个
ALt+Enter运行选中单元格,并在其下方新增一个单元格
2.5 帮助文档
- hlep(要查询的对象)
- 要查询的对象+?
- shift+tab
2.6 魔法指令
- %run
运行xx.py文件
%run xx.py
- %time
记录一行代码的运行时间
%%time 一行代码
- %%time
记录多行代码的运行时间
%%time
多行代码
- %timeit和%%timeit
类似于%time和%%timeit,但是会多次运行取平均值 - %who
找出当前所有的对象的名字 - %whos
不仅仅获取所有对象的名字,还有类型,和内容或者信息
2.7 IPython输入输出历史
jupyter notebook是基于IPython的,所以
In存放着所有已输入命令的字符串组成的字符串列表,可以通过In[index]获得元素。
Out返回所有含输出命令的序号及其输出组成的字典,可以通过Out[index]获得元素。
三、Numpy
Numpy是pandas库的基础。
3.1 普通列表和Numpy中的数组ndarray对象的区别
普通列表里面的元素可以是任意类型的,但数组ndarry里面的元素则必须是同类型的(会自动把元素类型统一,方便运算)。
3.2 ndarray的构造方法
ages = [17, 19, 20, 34]
ages_array = np.array(ages)
3.3 ndarray的访问方法
可以通过索引访问数组元素
数组相比列表而言,提供了一些方便的方法,如求和方法ndaaray.sum()
3.4 二维的构造与访问
数组*2会对里面每个元素乘以2,而列表乘以2会复制扩充原列表。
# 构造二维数组
array2 = np.array([[1,2],[3,4]])
3.5 快速构造高维数组
- 使用np.arange()方法构造数组
# 一个参数,则起点为0,参数为终点,步长为1
x = np.arange(5) # [0, 1, 2, 3, 4]
# 两个参数,则第一参数为起点,第二参数为终点,步长为1
y = np.arange(5, 10) # [5, 6, 7, 8, 9]
# 三个参数,则第一参数为起点,步长为1,第二参数为终点,第三个参数为步长
z = np.arange(5, 10, 0.5)
- 使用np.random模块构建随机数组
np.random.randn(n) # 创建服从正太分布的n个随机数组成的一维数组
np.random.randint(整数x, 整数y, [行m, 列n]) # 创建由x到y之间的随机数组成的m*n数组
ndaaray.reshape((a, b))方法可以将数组的形状改变成a行b列。
四、pandas
pandas被广泛用于快速数据分析,以及数据清洗和准备工作。相比Numpy而言,pandas更擅长处理二维数据。
pandas主要有两种数据结构:series和DataFrame。
series类似于一维数组,但是它还包含一组索引。
4.1 pandas的基本数据类型
- 创建series
import pandas as pd
s1 = pd.Series([“a”, "b", "c"], index=[“x”, "y", "z"])
- 创建DataFrame
DataFrame是Series的容器。
import pandas as pd
# 方法1:通过列表创建,可以通过index和col来配置行索引和列索引
a = pd.DataFrame(二维列表, index=[], col=[])# 方法2.11:通过字典创建,字典键会变成列索引
先创建两个series(或者列表),用变量names和ages存放
pd.DataFrame({"names": names,"ages": ages
})# 方法2.2:如果想让字典键变成行索引,可以通过from_dict方式,并设置orient参数为index
c = pd.DataFrame.from_dict({"a": [1, 3, 5], "b": [2, 4, 6]}, orient="index")# 方法2.3:通过把DataFrame当字典使用来赋予列
mdate = [1, 3, 4, 5]
score = [10, 20, 30, 40]
a = pd.DataFrame()
a["key1"] = mdata
a["key2"] = score# 方法3:通过np.arrange()方法来创建二维数组,然后传递给DataFrame
pd.DataFrame(np.arange(12).reshape(3,4), index=[1,2,3], columns=[...])
4.2 修改索引
- DataFrame.set_index()方法
# DataFrame.set_index可以将某列设置为行索引,但这样不会改变原DataFrame,而是返回一个新的DataFrame
a.set_index(“日期”)
# 要在原DataFrame上更改,要么直接赋值给原变量,要么使用参数inplace=True(如下)
a.set_index("日期", inplace=True)
- DataFrame.rename()方法
# 可以重命名索引,也有inplace参数
a.rename(index={"A": "万科", ...}, columns={"date":"日期"}, inplace=True)
- DataFrame.reset_index()方法
# 可以重置索引,让行索引变成常规列,也有inplace参数
a = a.reset_index()
4.3 excel和csv文件的读写操作
- 文件读取-excel
import pandas as pd
data = pd.read_excel('data.xlsx')
# 指定sheet读取
pd.read_excel("path", sheet_name=1)
# 参数index,以表格中的某列或某些列来设置行索引
# 参数header,以表格中某行或某些行设置列索引
pd.read_excel(path, index=0, header=[0, 1])
- 文件写入-excel
data.to_excel("mdata.xlsx")
- 文件读取-csv
pd.read_csv("csv文件", sep=',', header=[0,1])
- 文件写入-csv
data.to_csv("mdata2.csv")
4.4 绝对路径和相对路径
python中的\有转义功能,如\n等。所以只写一个\,需要再前面加r,去掉转义功能。或者写2个\。
# windows下绝对路径举例
"E:\\大数据分析\\data.xlsx"
r"E:\大数据分析\data.xlsx"
"E:/大数据分析/data.xlsx" # 这种写法主要用于linux,也可以用于windows(python也可以读取)
4.5 pandas对象访问与筛选
- 按照列来选取数据
b = data["c1"] #读取c1列,返回Series
b = data[["c1"]] # 读取c1列, 返回DataFrame
- 按照行来读取数据
d = data.loc["r1"] # 读取r1行,返回成一列的Series
d = data.loc[["r2", "r3"]] # 读取r2行和r3行,返回DataFrame
- 用loc读取某一个元素
records.loc[2, "身高"]
- 读取前几行
df.head(n) # 查看前n行,n不填默认为5
- 特定条件筛选
data[data["c1"] > 1] # 筛选c1列数字大于1的行
4.6 pandas数据运算
- shape属性查看行数和列数
data.shape # 返回(3, 3)
- describe()方法查看统计指标
df.describe() # 返回每一列的计数,均值等
- info()方法查看表格数据信息
df.info() # 可以看到每一列数据的数据类型和非空数据个数
- value_counts()方法统计每一列数据及其频次
data["c1"].value_counts()
- pandas支持列与列直接运算
df["sum"] = df["c1"] + df["c2"]
- pandas支持聚合方法
df.sum() # 默认对列进行求和,得到Series
df.mean() # 默认对列求均值
# 设置axis=1可以求行方向的
df.sum(axis=1)
df.mean(axis=1)
4.7 pandas映射处理
- map()方法对列数据进行映射
先定义map_funct方法
records["身体"].map(map_funct) # 对身高列做map方法
4.8 pandas空值填充和查找
表中数据如果显示NaN(表示Not a Number),表示空值。
- fillna()方法填充空值
data.fillna(value=0, inplace=True)
- isnull()方法查找空值
records.isnull() # 对每个数做空值检验,是空值的位置为Trure
# 求出每一列空值的个数
records.isnull().sum()
# 求出每一列空值的占比
records.isnull().mean()
五、Matplotlib数据可视化基础
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline # 这个魔法指令保证图像一定能渲染到jupyter上
5.1 折线图plt.plot()
x = [1,2 3]
y = [2,4,7]
plt.plot(x, y)
plt.show() # 建议写上。不用的话,在jupyter上也能看到,但是是在Out里
5.2 条形图(柱状图)plt.bar()
plt.bar(x, y, color=np.random.random((4,3))) # 利用0-1随机浮点数配置rgb颜色
plt.show()
5.3 散点图plt.scatter()
x # 横轴数据
y #纵轴数据
size # 大小,也可以用来表示第三维数据
plt.scatter(x, y, s=size) # 这样就成了气泡图
5.4 pandas库的快速绘图技巧
pandas绘制折线图
df # 10行3列的dataframe
df.plot() # 会把3列化成3条折线
df["人均收入"].plot(kind='line') # 和df.plot()一样
df["人均收入"].plot(kind='bar') # 绘制柱状图
df.T可以转置dataframe
5.5 添加文字说明
- 标题,x轴标签,y轴标签,图例
plt.plot(x, y, label="line of sin") # label就是图例要展示的信息
plt.title("xxx") # 添加标题
plt.xlabel("X") # 添加x轴
plt.ylabel("Y") # 添加y轴
plt.legend(loc="upper right") # 允许展示图例,且用loc参数配置位置,这里放在右上角
np.linspace(0, 2*np.pi, 100) 从0-2pi拆分出100个数,等差数列
- 中文显示的问题
使用matplotlib画图,默认不支持中文。需要通过全局配置。
plt.rcParams['font.sans-serif'] = 'SimHei' # 用来正常显示中文标签,simhei:黑体字
# 更改了字体会导致不显示负号,所以要
plt.rcParams['axes.unicode_minus'] = False # 解决符号"-"显示为方块的问题
5.6 绘制多图
figure是画布,下面有很多axes(子图)。
subplot()函数,含有3个参数,第一个表示行数,第二个表示列数,第三个表示子图序号。如subplot(2,2,1)表示绘制2行2列的子图,并在第1个子图上绘图。
plt.figure(figsize=(12, 8)) # 通过调整画布来调整整体大小
# 分别获取子画布绘图
ax1 = plt.subplot(221)
ax1.plot(x,y)
ax2 = plt.subplot(222)
ax2.plot(x,np.cos(x))
ax3 = plt.subplot(223)
ax3.plot(x,np.cos(x))
ax4 = plt.subplot(224)
ax4.plot(x,np.cos(x))
六、pandas文件汇总
- os模块
import os
os.listdir('./') # 获取当前目录下的子目录和子文件
for root, dirs, filenames in os.walk('./)': # 迭代进入子目录,获取子文件...
os.path.join(root, filename) # 拼接路径
- pd.concat()
pd.concat(files) # 将多个dataframe组成的李彪进行级联
七、业务数据分析思维
7.1 业务指标
从”离职率“指标展开。

p65-p72,暂略
7.2 常用的分析方法
7.3 逻辑树分析
7.4多维度拆解分析
7.5 对比分析
7.6 归因分析(假设检验法)
RFM分析模型
漏斗分析模型(AARRR分析模型)
杜邦分析法(了解)
八、统计学
略
九、商业智能 Power BI
PowerBI官网:https://powerbi.microsoft.com/zh-cn/
9.1 Power BI简介
传统公司的痛点:
1.没有专门的分析师,有领域专家,但是卡在工具使用上
2.数据量很复杂,表很散,大量工作用在表的集中。很多时间浪费在想法-制作报表的过程中。
3.缺ETL过程:源-整合-数据治理-加载 - 大数据架构
外卖公司里面有很多系统,如客户订单系统,物流管理系统,商家系统,客服售后系统,这些系统是独立开发的。然后考虑接入数据中台。
数据分析平台:只读。如国内:FineReport,神策,诸葛IO。美国:Tableau(做地图起家)、PowerBI(微软)。
APP:用户操作:埋点数据。
要在PowerBI中获取更多视觉对象,需要账号,账号分为普通账号
1.企业邮箱,或者edu邮箱, 可以免费申请,可以从淘宝买,10元以内。
2.pro账号:不仅可以获得更多视觉对象,可以发布报表文档,权限管理可分享,99永久。个人不建议买。
9.2 PowerBI实操1_整体报表建立
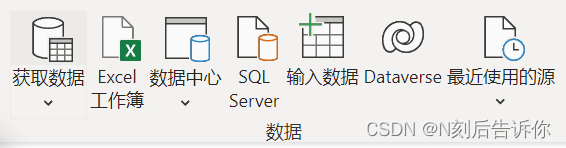
9.2.1 功能区介绍
- 数据源找数据
- 数据清洗
- 视觉对象
- 各种透视

流程:数据源-数据清洗power query-构建指标 新建度量值power pivot-可视化power view-报表完成

左边的三个分别是(从上到下):报表、数据、表和表之间的关系(数据建模)
PowerBI可以通过:获取数据,选择其他,选择Web连接,读取网页中的表格信息。适用于读取一些内容多,但是网站比较老的数据网站。
可以去PowerBI文档:https://learn.microsoft.com/zh-cn/power-bi/。查看一些函数的用法。
9.2.2 读取文件夹并合并文件
获取数据,加载文件夹,然后在Power Query编辑器中,找到加载的文件夹内容,删除其他列(如创建时间等),只保留Content列,然后选择合并文件(注意合并的文件,一定要注意标题对应一致)
9.2.3 加载MySQL
必须要安装mysql-connector-net-…msi文件放在mysql的文件夹里面,PowerBI才能连接Mysql。
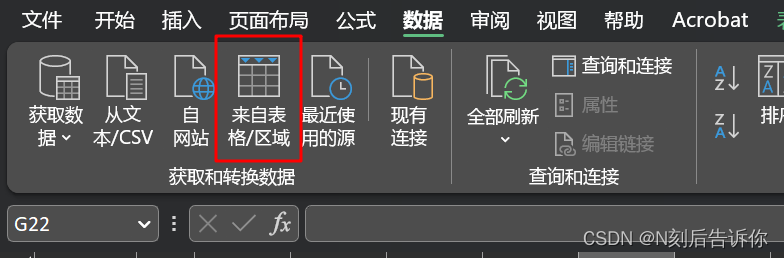
9.2.4 excel的powerquery编辑器
excel也可以进入powerquery编辑器。(所以后面的讲解都在excel的powerquery编辑器上)
在“数据选项卡",选择"来自表格/区域"。
上一篇:分布式锁学习笔记