HyperGBM用4记组合拳提升AutoML模型泛化能力
本文作者:杨健,九章云极 DataCanvas 主任架构师
如何有效提高模型的泛化能力,始终是机器学习领域的重要课题。经过大量的实践证明比较有效的方式包括:
- 利用Early Stopping防止过拟合
- 通过正则化降低模型的复杂度
- 使用更多的训练数据
- 尽量使用更少的特征
- 使用CV来选择模型和超参数
- 使用Ensemble来提升泛化能力
Early stopping以及正则化是比较基本的方法这里就不赘述,此外HyperGBM中还提供了4种高级特性,专门用来提升模型的泛化能力:
- Pseudo-labeling半监督学习
- 二阶特征筛选
- K-fold Cross-validation
- Greedy ensemble
1.Pseudo-labeling
伪标签技术主要应用在分类任务上,本质上是通过半监督学习的方法来增加更多的训练数据,以提升模型的泛化能力。其过程如下图所示,主要分为三个阶段:
1.第一阶段用训练数据训练模型;
2.第二阶段使用第一阶段训练好的模型在无标注的数据上预测,将其中置信度较高的数据合并到训练集中;
3.第三阶段使用合并后的数据重新训练模型;
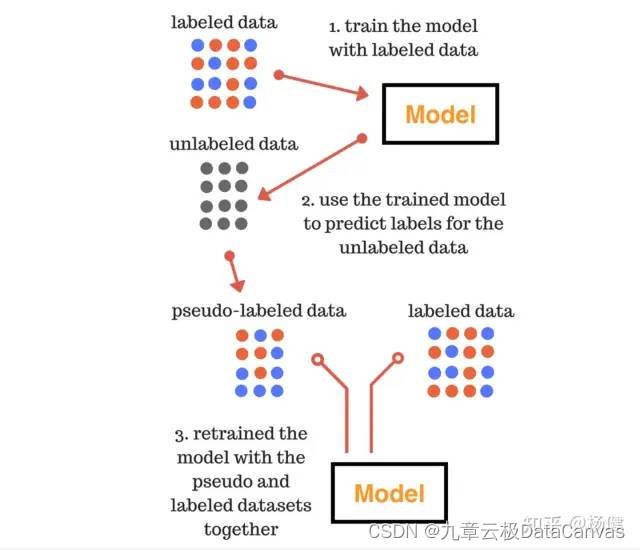
Image from: https://www.analyticsvidhya.com/blog/2017/09/pseudo-labelling-semi-supervised-learning-technique/
示例代码,HyperGBM中只需设置pseudo_labeling会自动完成伪标签学习:
from tabular_toolbox.datasets import dsutils
from sklearn.model_selection import train_test_split
from hypergbm.search_space import search_space_general
from hypergbm import make_experiment
# load data into Pandas DataFrame
df = dsutils.load_bank()
target = 'y'
train, test = train_test_split(df, test_size=0.3)
test.pop(target)#create an experiment
experiment = make_experiment(train,target=target,pseudo_labeling=True)
#run experiment
estimator = experiment.run()
# predict on test data without target values
pred = estimator.predict(test)
2.二阶特征筛选
通过特征筛选过滤掉无效特征或者噪音数据,能有效降低模型的复杂度。传统的特征筛选方法,一类是在训练之前通过相关性指标评估或者是基于模型的特征评估排序,然后根据阈值或者是排序选择n个特征用于训练,另一类是先训练模型然后根据模型本身提供的特征重要性来选择一部分特征重新训练。第一类方法有明显的缺陷就是特征的评估标准和实际用于训练的模型无关,也不会考虑特征之间的交互关系。第二类方法有明显的改进但也存在一个问题,就是模型提供是在训练数据上的重要性,并不能体现在评估数据或测试数据上特征的重要性。因此HyperGBM中引入了独特的二阶特征筛选策略来克服以上缺点。它的工作方式如下:首先执行一阶段AutoML过程,然后选择其中表现最好的n个模型使用permutation模式评估特征重要性,删除低于某一阈值的特征后,重新执行AutoML过程。
这里主要介绍一下permutation特征筛选:首先,基于已经训练好的模型在评估集上得到一个baseline评分,然后分别将每一列特征变成噪音数据后重新评估,评分等于或高于baseline评分说明该特征对模型没有增益甚至于是有损的,如果评分下降说明该特征是对模型有益的,用这个和baseline评分的差值做为特征筛选的参考值选择特征。
示例代码如下:
#create an experiment
experiment = make_experiment(train,target=target,
feature_reselection=True,
feature_reselection_estimator_size=10,
feature_reselection_threshold=1e-5,
)
3.K-fold Cross-validation
交叉验证被证明是模型选择和超参数优化中最有效的验证方式,示例代码如下:
#create an experiment
experiment = make_experiment(train,target=target,
cv=True,
num_folds=3,
)
4.Greedy Ensemble
Greedy Ensemble是使用基于voting的集成学习方法,实现原理可以参考:
https://www.sciencedirect.com/science/article/abs/pii/S0031320310005340
示例代码:
#create an experiment
experiment = make_experiment(train,target=target,
ensemble_size=20, # 0 to disable ensemble
)
以上四种方法可以组合起来使用。
上一篇:数据结构与算法(五):优先队列
下一篇:深度剖析指针(上)——“C”