Hadoop 组成
创始人
2025-05-28 06:02:12
0次
4 Hadoop 优势(4 高)
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。

2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
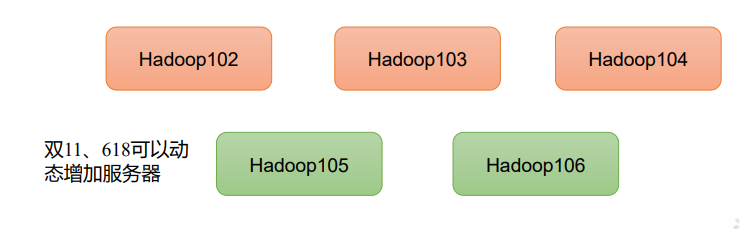
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
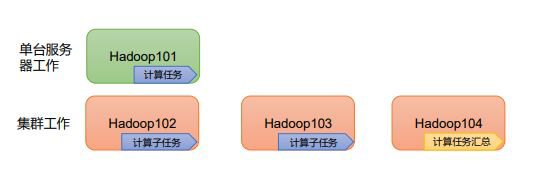
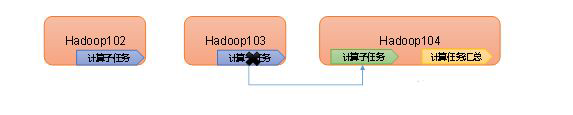
4)高容错性:能够自动将失败的任务重新分配。
5 Hadoop 组成(面试重点)
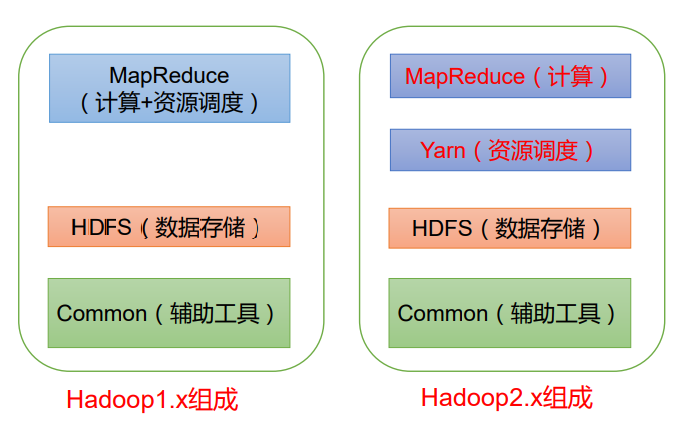
- 在 Hadoop1.x 时 代 ,Hadoop中 的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
- 在Hadoop2.x 时代,增加 了Yarn。Yarn只负责资源的调 度 ,MapReduce 只负责运算。
- 在Hadoop3.x 时代,在组成上没有变化。
5.1 HDFS 架构概述
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。
HDFS架构概述:
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。

2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。

3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
5.2 YARN 架构概述
Yet Another Resource Negotiator 简称 YARN ,另一种资源协调者,是 Hadoop 的资源管理器。
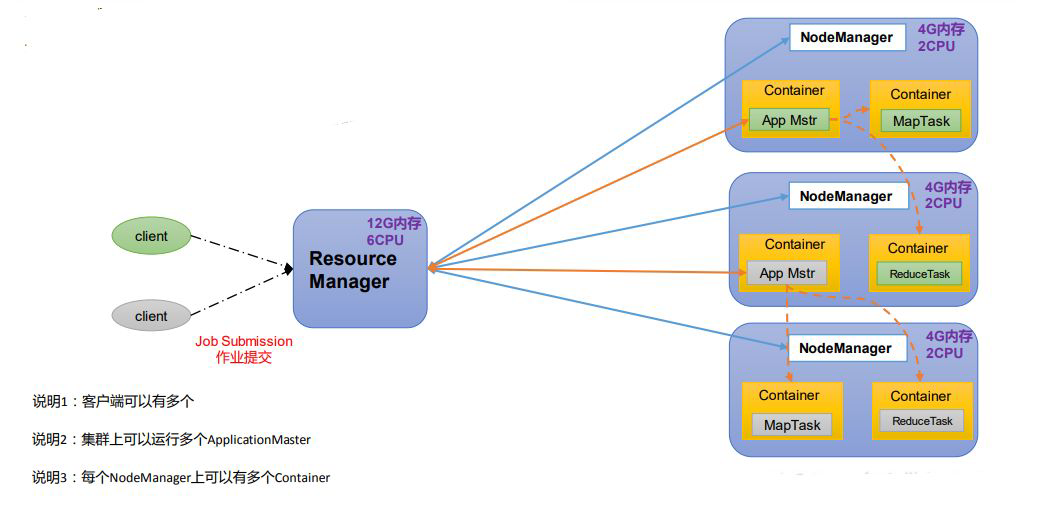
1)ResourceManager(RM):整个集群资源(内存、CPU等)的老大
3)ApplicationMaster(AM):单个任务运行的老大
2)NodeManager(N M):单个节点服务器资源老大
4)Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
5.3 MapReduce 架构概述
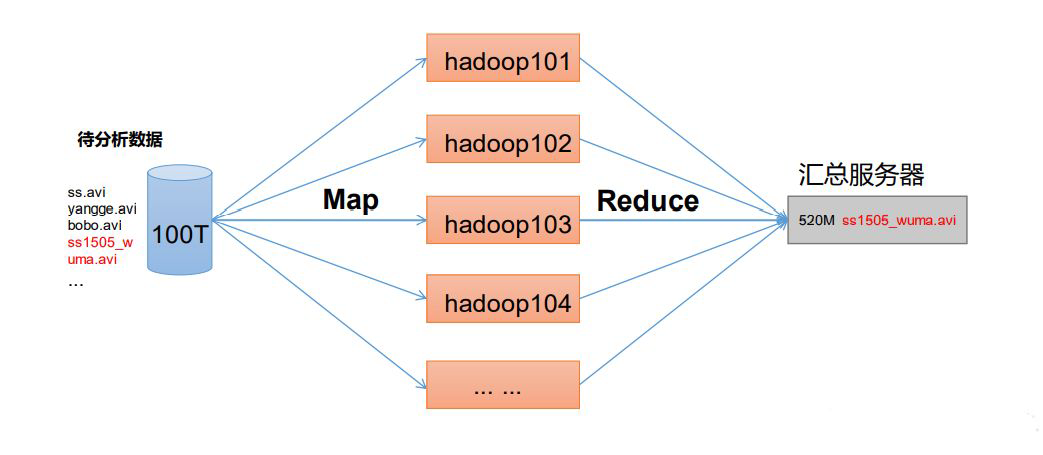
MapReduce:分布式的离线并行计算框架,对海量数据的处理。将计算过程分为Map和Reduce两个阶段,Map阶段并行处理输入数据,Reduce阶段对Map结果进行汇总。
Mapper:
- 1.第一阶段是把输入文件进行分片(inputSplit)得到block。有多少个block就对应启动多少maptask
- 2.第二阶段是对输入片中的记录按照一定的规则解析成键值对。键(key)表示每行首字符偏移值,值(value)表示本行文本内容。
- 3.第三阶段是调用map方法。解析出来的每个键值对,调用一次map方法。
- 4.第四阶段是按照一定规则对第三阶段输出的键值对进行分区。
- 5.第五阶段是对每个分区中的键值对进行排序。首先按照键进行排序,然后按照值。完成后将数据写入内存中,内存中这片区域叫做环形缓冲区。
Reduce:
- 1.第一阶段(copy)reduce任务从Mapper任务复制输出的键值对。
- 2.第二阶段(sort)合并排序是把复制到Reduce本地数据,全部合并。再对合并后的数据排序
- 3.第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
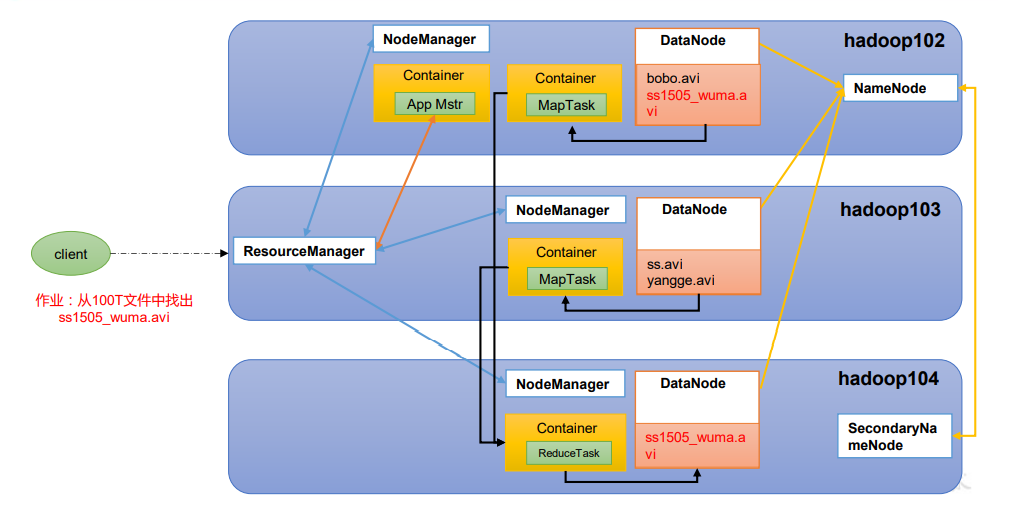
5.4 HDFS、YARN、MapReduce 三者关系
相关内容
热门资讯
前端-session、jwt
目录: (1)session (2&#x...
linux入门---制作进度条
了解缓冲区 我们首先来看看下面的操作: 我们首先创建了一个文件并在这个文件里面添加了...
关于测试,我发现了哪些新大陆
关于测试 平常也只是听说过一些关于测试的术语,但并没有使用过测试工具。偶然看到编程老师...
前缀和与对数器与二分法
1. 前缀和 假设有一个数组,我们想大量频繁的去访问L到R这个区间的和,...
nodejs:本地安装nvm实...
一、背景-使用不同版本node的原因 vue3+ts、nuxt3版本,node...
JAVA集合知识整理
Java集合知识整理 HashMap相关 HashMap的底层数据结构:jdk1.8之...
无刷直流电机介绍及单片机控制实...
无刷直流电机介绍及单片机控制实例前言基本概念优势与劣势使用寿命基本结构使用单片机控制实例电子调速器&...
fwdiary(2) dp2
1.传纸条 AcWing 275. 传纸条 - AcWing 走两条路,走一条最大的...
常用的DOS命令
常用的DOS命令 DOS(Disk Operating System,磁...
<C++> 类和对象(下)
1.const成员函数将const修饰的“成员函数”称之为const成员函数,cons...