Multi-Source Anomaly Detection in Distributed IT Systems
写这个系列的文章的目的是这学期老师要求我们一周至少读两篇论文,一学期下来至少30篇,然后写一篇综述,所以我权当做个笔记了,本来博客上是已经基本停笔了,做一些论文相关的工作还细致的写博客还是蛮耽误时间的,有那时间不如去弹弹吉他或者和对象或家里人通个电话。
另外,顺便吐槽一句,我做的方向是没有太多趣味性的,软件工程领域的一些系统信息(文本)的异常检测。我现在深深感受到一句话,“怎么选都会后悔”。真的是怎么选都会后悔。
我可能不会详细的阐述的某篇文章的整体思路,可能会对论文里涉及到的一些技术或术语进行记录,下面开始正题。
一.有限状态自动机
有限状态自动机(FSM "finite state machine" 或者FSA "finite state automaton" )是为研究有限内存的计算过程和某些语言类而抽象出的一种计算模型。有限状态自动机拥有有限数量的状态,每个状态可以迁移到零个或多个状态,输入字串决定执行哪个状态的迁移。有限状态自动机可以表示为一个有向图。有限状态自动机是自动机理论的研究对象。
二.日志的解析
对于一条条的日志,我们要做的就是提取日志的模板,提取日志的公共部分(即常量部分),然后空出变化的部分(即变量部分)。
eg:
日志一:i want to eat apple.
日志二:i want to eat orange.
那么提取到的模板就是“i want to eat <***>”
日志是时序有序的非结构化文本消息序列,L={L_i:i=1,2,3,...},L_i就是一条条的日志信息。
所有日志信息都对应一个词典 ,这有点像之前在NLP里学到的词典的那个概念。
,这有点像之前在NLP里学到的词典的那个概念。
L_i又是由一个个索引组成的,这些索引又是词典中对应的单词的索引。
![]()
而且本文对日志信息做了填充操作,填充符

三.调用链的解析
T_i代表某条调用链,S^i_m 代表一个span
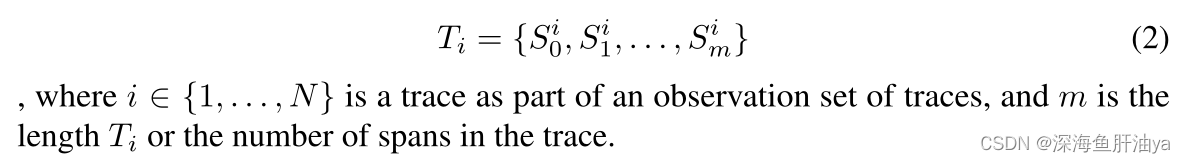
一个span表示处理服务中的外部请求时所执行的操作的信息(例如开始时间、结束时间、服务名称、HTTP路径)。
调用链也和日志一样,有个词典,然后每个span在词典中都有对应的索引,这样每条调用链都有一个自己对应的span模板序列。
观察到每个函数调用都是字符序列,构造了一个包含出现在给定跟踪集中的字符序列的字典
D_span words。也就是这个词典里面的元素不是单词,而是字符序列。
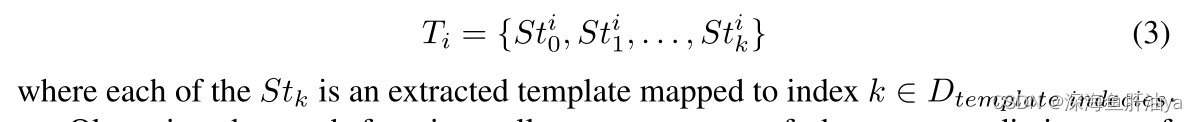

并且调用链的表示也会进行填充。
四.单模态异常检测
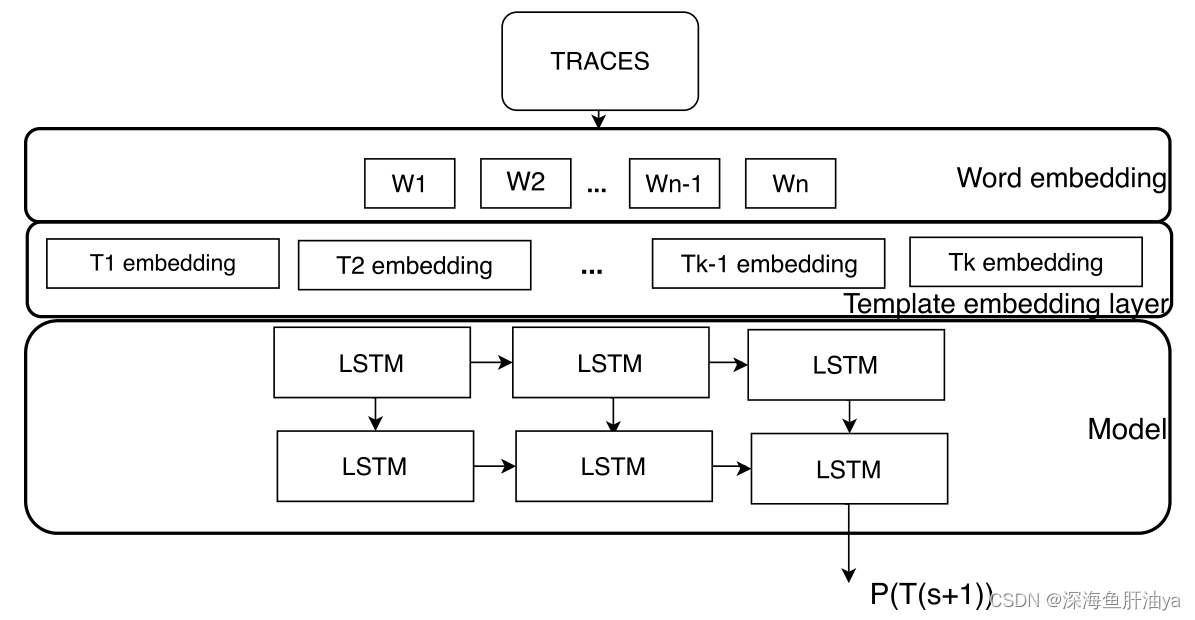
上面的图的模型结构也适应于日志数据。
五.多模态异常检测
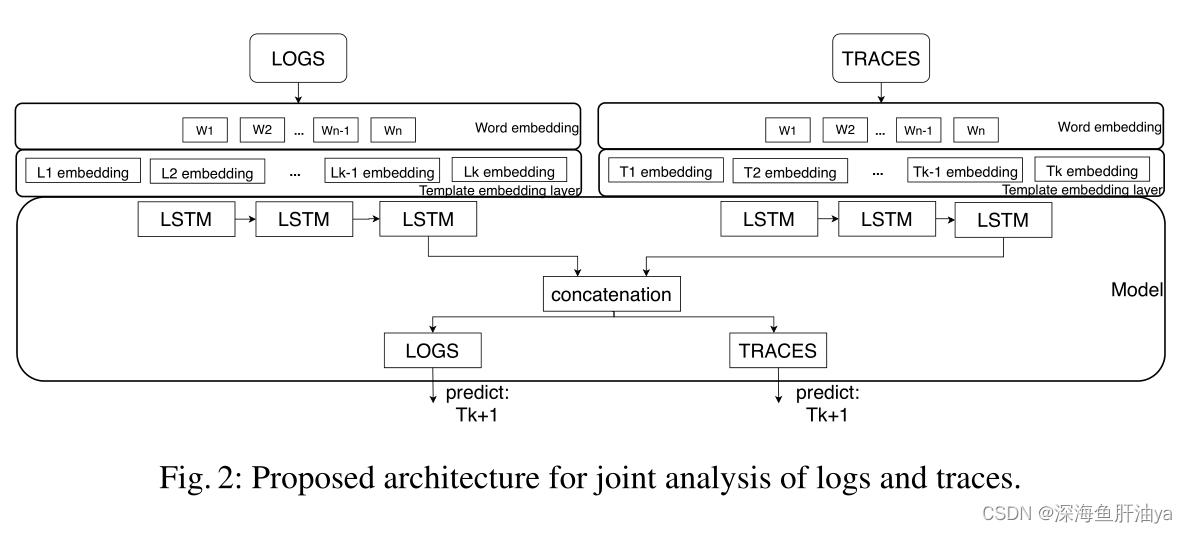
它由前一节中描述的两个模型组成。在提供的输入中,同时有两个模型的日志和跨度字典。然而,两个lstm的输出是相互连接的,并通过一个额外的线性层馈送。它提供了一个优势,包括来自两种模式的信息,以提高预测性能。然后,来自连接的共享信息通过两个线性层传递,一个层负责跟踪,另一个层负责日志。
这篇文章是21年的文章,但是无论是这篇文章的单模态还是多模态的处理方法,都是用到了LSTM,所以我个人觉得方法还是比较不够新颖,但是毕竟有多模态的处理思路,所以还是值得借鉴的。
具体实现细节没看懂啊,又是一篇不给源码的论文,纯纯是在耍流氓......
六.未来工作
1.In future work, we would investigate how adding additional information from the metric data can be incorporated into the model.
2.we would investigate transfer learning approaches based on the generated embeddings. Specifically, we are interested in investigating how the learned embeddings can be reused for other types of workloads with a final aim to reduce the deploy time of the machine learning model in production.
下一篇:第二课 词向量