Hadoop集群安装
创始人
2025-05-28 19:21:05
0次
文章目录
- 一、Hadoop
- 二、使用步骤
- 1.Hadoop 本地安装
- 1.1安装jdk
- 1.2.安装Hadoop
- 1.3.案例演示
- 2.Hadoop 伪分布模式
- 1.1安装jdk,hadoop(如上)
- 1.2搭建环境准备
- 1.3配置环境修改
- 1.4 启动集群
- 1.5 案例演示
- 3.Hadoop 分布式集群
- 3.1总纲
- 3.2搭建Hadoop3.x分布式集群
- 3.3配置Hadoop环境变量
- 附:
- 关闭防火墙
- 配置静态IP
- 修改主机名
- SSH免密登录
- 同步时间
提示
一、Hadoop
官网:https://hadoop.apache.org/ (项目名.apache.org)
二、使用步骤
1.Hadoop 本地安装
# 安装最新版本不兼容,查询官网需jdk8
Supported Java Versions
Apache Hadoop 3.3 and upper supports Java 8 and Java 11 (runtime only)
Please compile Hadoop with Java 8. Compiling Hadoop with Java 11 is not supported: HADOOP-16795 - Java 11 compile support OPEN
Apache Hadoop from 3.0.x to 3.2.x now supports only Java 8
Apache Hadoop from 2.7.x to 2.10.x support both Java 7 and 8
1.1安装jdk
https://blog.csdn.net/qq_35911309/article/details/107374801
jdk安装包:
https://www.oracle.com/cn/
https://www.oracle.com/java/technologies/downloads/
https://jdk.java.net/19/
jdk8下载
转至 http://java.com 并单击下载按钮
Not the right operating system? See all Java 8 Downloads for Desktop users.
卸载之前的jdk
#查看CentOS自带JDK是否已安装:
yum list installed | grep java
rpm -qa|grep jdk
# 卸载
rpm -e **** --nodeps
yum remove tzdata-java.noarch
上传解压jdk到指定路径
[root@192 software]#请修改版本tar -zxvf openjdk-19.0.2_linux-x64_bin.tar.gz -C /usr/local/
配置环境变量
vim /etc/profile 文件中加入:
# java_home 等号间不能有空格
export JAVA_HOME=/usr/local/jdk-19.0.2
export PATH=$JAVA_HOME/bin:$PATH
# 使配置生效:
source /etc/profile
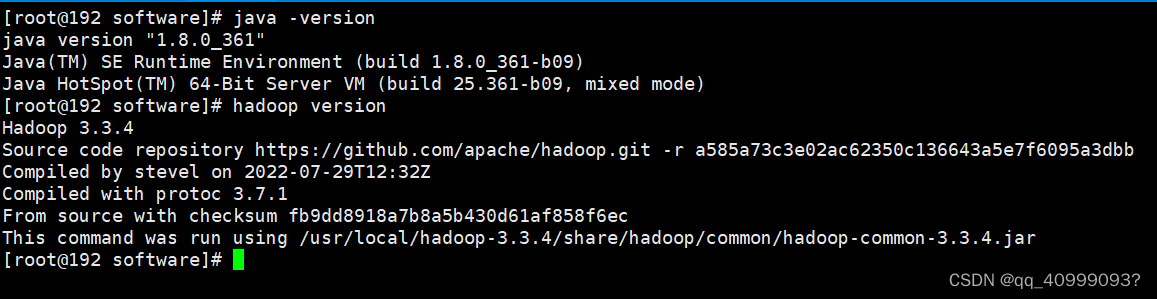
#查看jdk是否安装成功,输入指令
java -version
1.2.安装Hadoop
安装包: https://dlcdn.apache.org/hadoop/common
上传解压到指定路径
cd /opt/software/
tar -zxvf hadoop-3.3.4.tar.gz -C /usr/local/
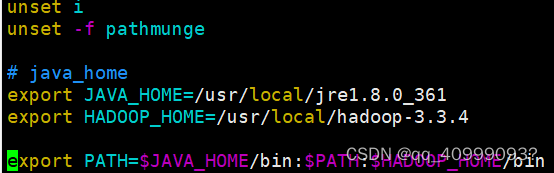
配置环境变量
vim /etc/profile 文件中加入
# java_home 等号间不能有空格
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$PATH:$HADOOP_HOME/sbin
# 使配置生效:
source /etc/profile
#查看hadoop是否安装成功,输入指令
hadoop version
1.3.案例演示
#新建目录input 存放文本文件
mkdir /home/*****/input
vim file1
for i in{1..100};do cat file1>>file2;done;
for i in{1..100};do cat file2>>file3;done;
# 执行wordcount(求字频统计)(output程序自动创建)
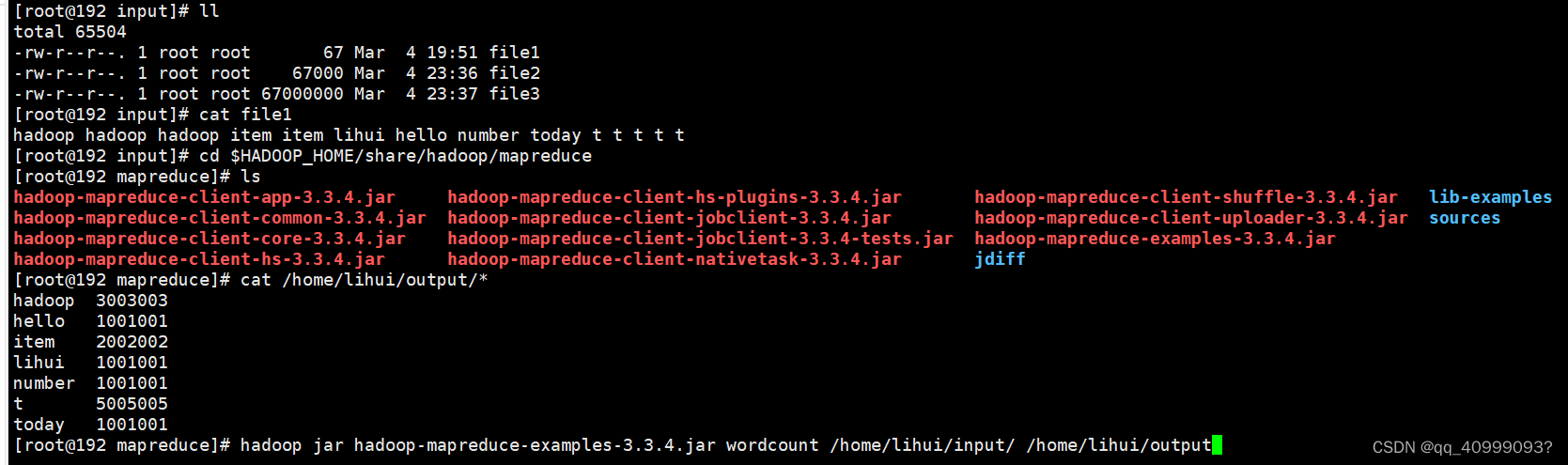
cd $HADOOP_HOME/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-3.3.4.jar wordcount /home/*****/input/ /home/*****/output
# 查看结果
cat /home/*****/output/*
# 执行pi(求pi值)
hadoop jar hadoop-mapreduce-examples-3.3.4.jar pi 10 10

2.Hadoop 伪分布模式
1.1安装jdk,hadoop(如上)
1.2搭建环境准备
防火墙关闭
systemctl status firewalld
systemctl stop firewalld
systemctl disable firewalld
vim /etc/selinux/config
······
SELINUX=disabled
······
静态IP和免密登录(如下)
修改HOST映射
vim /etc/hosts
------
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.101 localhost.localdomain
------
1.3配置环境修改
/usr/local/hadoop-3.3.4/etc/hadoop
core-site.xml
fs.defaultFS
hdfs://hadoop138:9820
hadoop.tmp.dir
/usr/local/hadoop-3.3.4/temp
hdfs-site.xml
dfs.replication
1
dfs.namenode.secondary.http-address
localhost.localdomain:9868
dfs.namenode.http-address
localhost.localdomain:9870
hadoop-env.sh
export export JAVA_HOME=/usr/local/jre1.8.0_361
#hadoop3
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
1.4 启动集群
格式化集群
# core-site.xml配置的hadoop.tmp.dir之前不存在。生成temp和log文件
hdfs namenode -format
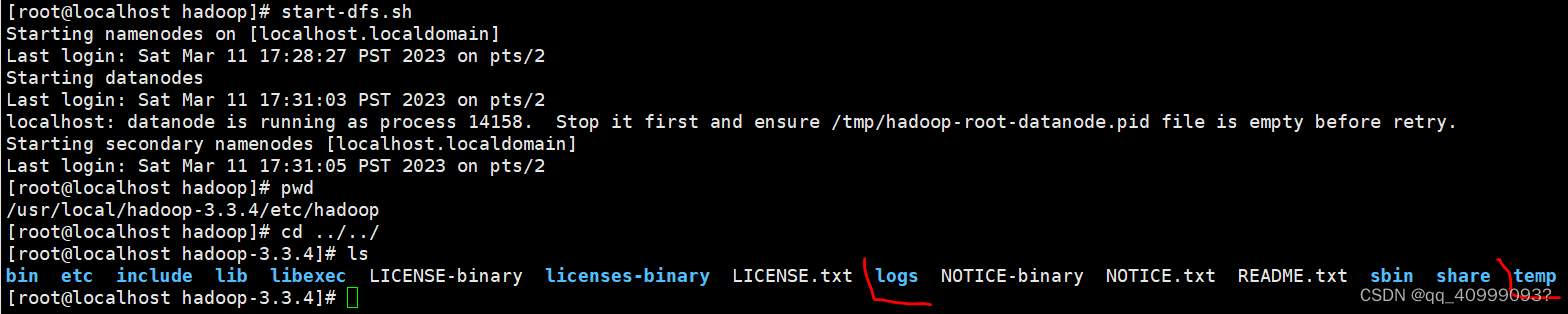
启动集群
start-dfs.sh
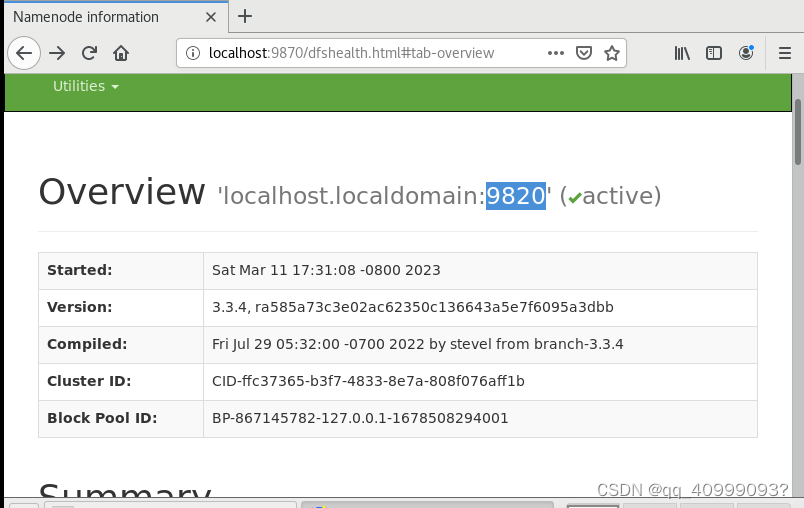
#hdfs监控界面
http://192.168.10.101:9870/
1.5 案例演示
1.数据准备
mkdir /home/*****/input
[root@localhost input]# echo "hello world hadoop">>file5
[root@localhost input]# echo "hello world hadoop">>file5
[root@localhost input]# echo "hello world hadoop">>file5
[root@localhost input]# echo "good good day lihui">>file6
2.上传到集群
#因为伪分布式集群也应当分布式的思想,分布式的存储,
#任务处理的数据HDFS数据,而并不是Linux本地的。
[root@localhost hadoop-3.3.4]# cd /home/lihui/
#上传
[root@localhost lihui]# hdfs dfs -put input/ /
#查看
[root@localhost hadoop-3.3.4]# hdfs dfs -ls -R /
cd $HADOOP_HOME/share/hadoop/mapreduce
#执行
[root@localhost mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.4.jar wordcount /input/ /output
#查看结果
[root@localhost mapreduce]# hdfs dfs -cat /output/*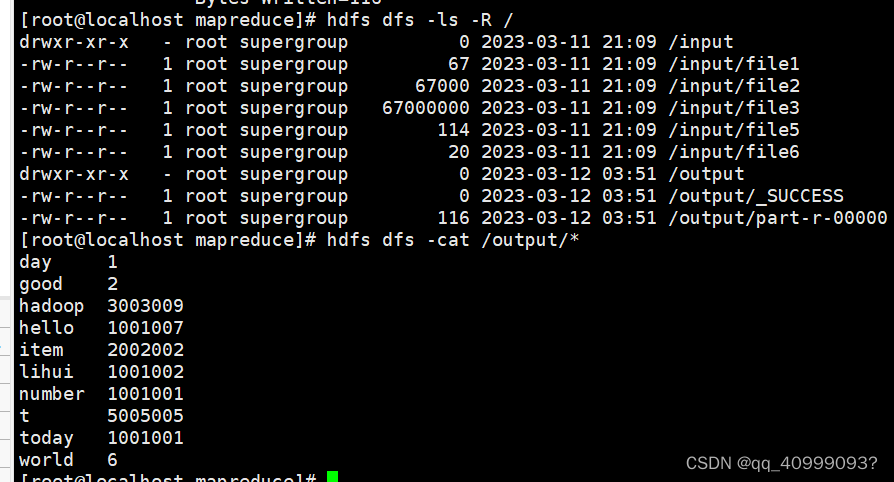
3.Hadoop 分布式集群
3.1总纲
三台机器的防火墙是关闭的
确保三台机器的网络配置畅通(NAT模式,静态IP,主机名的配置)
确保etc/hosts文件配置了ip和hostname的映射关系
确保配置了三台机器的免密登录认证
确保所有机器时间同步
jdk和hadoop环境变量配置
3.2搭建Hadoop3.x分布式集群
cd opt/softwares/
tar -zxvf hadoop-3.3.4.tar.gz -C /opt/modules/
vim /etc/profile
------
export JAVA_HOME=/opt/modules/jre1.8.0_361 #java_home
export HADOOP_HOME=/opt/modules/hadoop-3.3.4 #HADOOP_HOM
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
------
source /etc/profile
#验证
hadoop
3.3配置Hadoop环境变量
/etc/hadoop中修改文件:hadoop-env.sh mapred-env.sh yarn-env.sh
附:
关闭防火墙
systemctl status firewalld
systemctl stop firewalld
systemctl disable firewalld
# 最好也把selinux关闭,这是Linux的安全机制
vim /etc/selinux/config
······
SELINUX=disabled
······
配置静态IP
1.点击虚拟机->设置->网络适配器->网络连接选择NAT模式
2.点击编辑->虚拟网络编辑器->更改设置(此选项需要管理员权限)
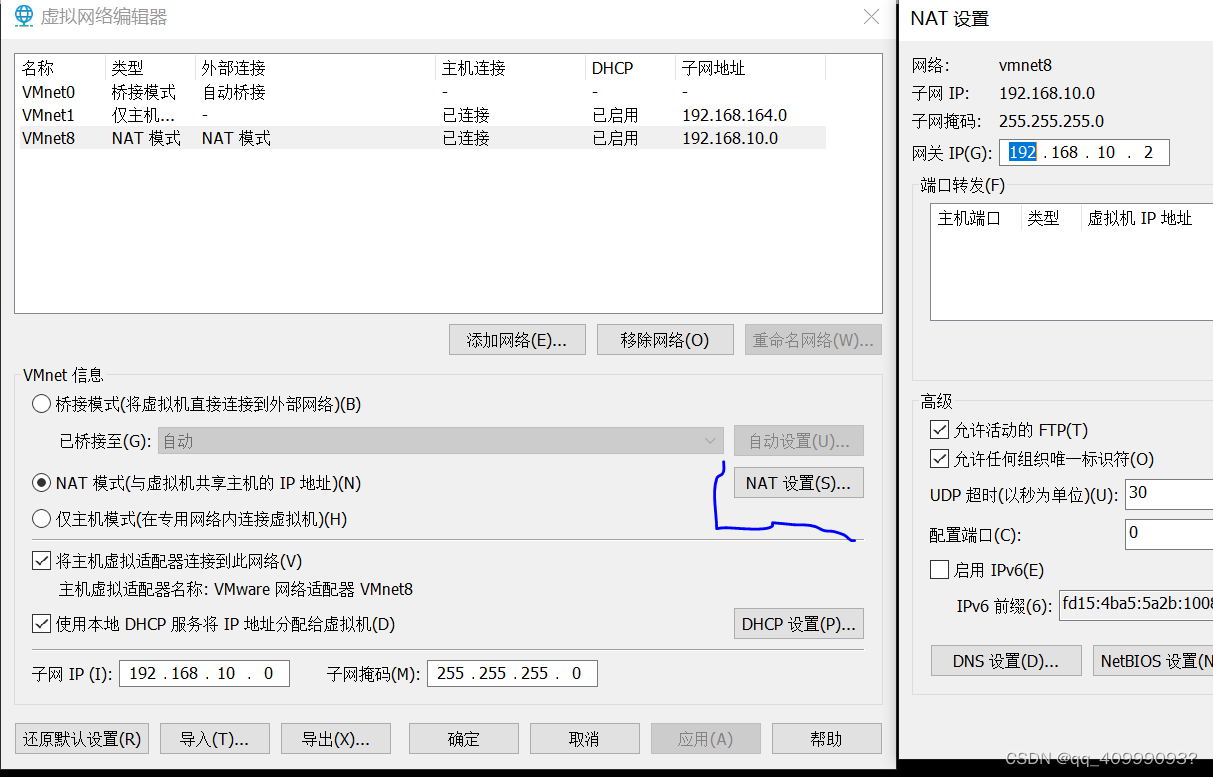
#打开终端,输入以下命令,修改网卡配置文件
cd /etc/sysconfig/network-scripts
vim ifcfg-ens32
#修改
BOOTPROTO=static #static 表示静态IP
ONBOOT=yes #yes表示开机启用本配置
#添加
IPADDR=92.169.10.102
NETMASK=255.255.255.0
GATEWAY=192.168.10.2
DNS1=8.8.8.8
DNS2=114.114.114.114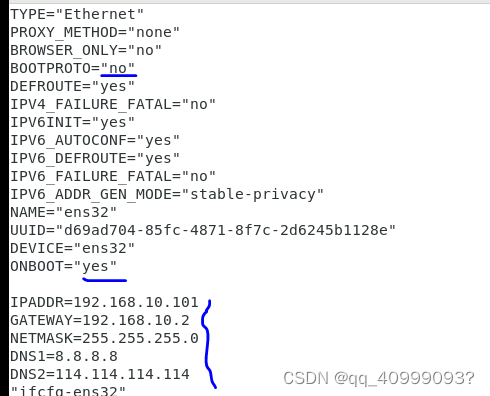
#重新启动网卡
systemctl restart network
#查看
ip addr
修改主机名
#查看主机名
hostname
#临时修改
hostname centos1
#永久修改(重启生效)HOSTNAME仅是本机的一个代号
vim /etc/hostname
······
centos1
······
#HOSTS文件只做IP的映射,映射到的名称可以是任意值
#建议将HOSTS中的映射写为对应机器的HOSTNAME,如此设置会具有良好的可读性,并避免不必要的混淆
vim /etc/hosts
······
192.168.10.132 centos1
······
SSH免密登录
#伪分布式
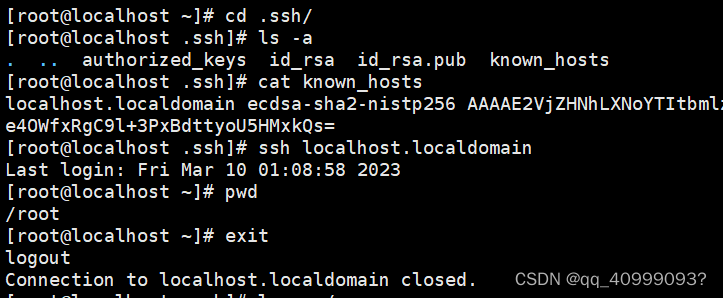
1、生成密钥文件:
ssh-keygen -t rsa
2、查看生成的密钥文件,
其中:id_rsa为私钥文件,id_rsa.pub为公钥文件
ls -a ~/.ssh
3.执行命令将公钥文件传输本机
ssh-copy-id localhost.localdomain
4.再次使用已经做免密处理的root用户登录,已经不需要密码了
ssh localhost.localdomain
vim /etc/hosts
······
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.101 centos1
192.168.10.102 centos2
192.168.10.105 centos5
······
scp /etc/hosts root@192.168.10.102:/etc/hosts
scp /etc/hosts root@192.168.10.105:/etc/hosts
#查看
ping centos2
#无密登录
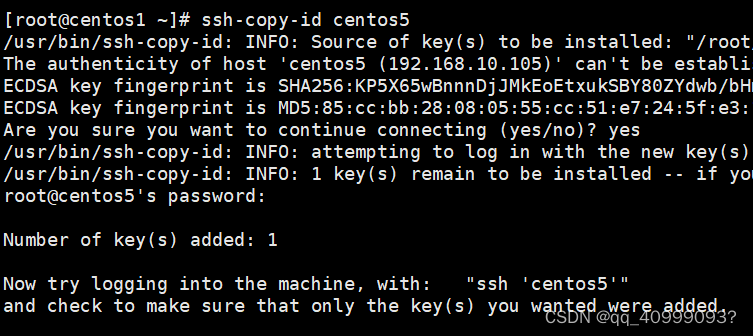
cd ~/.ssh/ #若没有该目录,请先执行一次ssh localhost命令
ssh-keygen -t rsa # 生成秘钥文件,都按回车键即可
ssh-copy-id centos5 # 分别在三个节点执行以下命令,公钥赋值到对方节点
ssh-copy-id centos1
ssh-copy-id centos1
同步时间
# 1.同步网络时间
yum install ntpdate
# 使用ntpd命令同步网络上的时间服务器
ntpdate ntp.aliyun.com #(报no server suitabl)
# 2.同步时间
#Linux自带了ntp服务 扮演一个time server的角色 配置文件就是/etc/ntp.conf
# 第一步,node1做time server,先把node1机器的时间调准了:
date # 查看
date -s "2023-03-15 11:40:35" #设置
把设置的时间写到硬件时间中去
clock -w
hwclock --systohc # date和hwclock -r 一致
查看系统硬件BIOS时钟
hwclock -r #查看
hwclock --set --date="06/18/14 14:55" (月/日/年时:分:秒)#设置(建议用上面方法同步)
# 3.修改文件(最终按此)
#在linux系统下修改CST东八区标准时间
rm -rf /etc/localtime
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime#第二步,然后将node1配置成一个time server,修改/etc/ntp.conf(未实)
/etc/ntp.conf
······#行本身是不响应任何的ntp更新请求,其实也就是禁用了本机的ntp server的功能,所以需要注释掉。
1. 注释掉原来的restrict default ignore这一行,
# 让192.168.1.0/24网段上的机器能和本机做时间同步
2. 加入:restrict 192.168.1.0 mask 255.255.255.0
3. 增加下面的,这是让本机的ntpd和本地硬件时间同步。
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
······
systemctl restart ntpd
下一篇:Graphics2D绘制图形详解
相关内容
热门资讯
保存时出现了1个错误,导致这篇...
当保存文章时出现错误时,可以通过以下步骤解决问题:查看错误信息:查看错误提示信息可以帮助我们了解具体...
汇川伺服电机位置控制模式参数配...
1. 基本控制参数设置 1)设置位置控制模式 2)绝对值位置线性模...
不能访问光猫的的管理页面
光猫是现代家庭宽带网络的重要组成部分,它可以提供高速稳定的网络连接。但是,有时候我们会遇到不能访问光...
不一致的条件格式
要解决不一致的条件格式问题,可以按照以下步骤进行:确定条件格式的规则:首先,需要明确条件格式的规则是...
本地主机上的图像未显示
问题描述:在本地主机上显示图像时,图像未能正常显示。解决方法:以下是一些可能的解决方法,具体取决于问...
表格列调整大小出现问题
问题描述:表格列调整大小出现问题,无法正常调整列宽。解决方法:检查表格的布局方式是否正确。确保表格使...
表格中数据未显示
当表格中的数据未显示时,可能是由于以下几个原因导致的:HTML代码问题:检查表格的HTML代码是否正...
Android|无法访问或保存...
这个问题可能是由于权限设置不正确导致的。您需要在应用程序清单文件中添加以下代码来请求适当的权限:此外...
银河麒麟V10SP1高级服务器...
银河麒麟高级服务器操作系统简介: 银河麒麟高级服务器操作系统V10是针对企业级关键业务...
【NI Multisim 14...
目录 序言 一、工具栏 🍊1.“标准”工具栏 🍊 2.视图工具...