QA_全网最系统的单细胞测序细胞互作/细胞通讯分析课程
创始人
2025-05-31 05:08:50
0次
课程介绍见全网最系统的单细胞测序细胞互作/细胞通讯分析课程
本网页的答疑记录来自课程学员群。
文章目录
- 1. 示例数据都提供吗?
- 2. 配套视频在哪里?
- 3. 单细胞预处理
- 4. cellphonedb的环境配置问题
- 5. cellphonedb的标准化问题
- 6. cellphonedb中多个亚基的受配体(complex)如何查询具体的基因?
- 7. 空间转录组绘图
- 8. cellchat中igraph的问题
1. 示例数据都提供吗?
所有代码用到的数据都会提供。
2. 配套视频在哪里?
在B站,UP主:TOP菌
3. 单细胞预处理
-
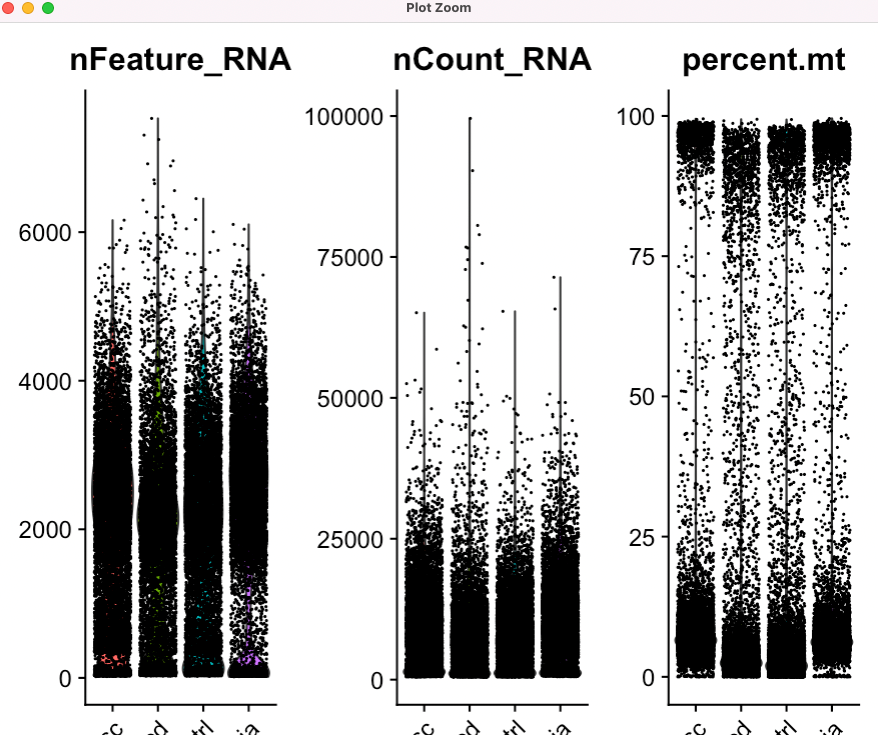
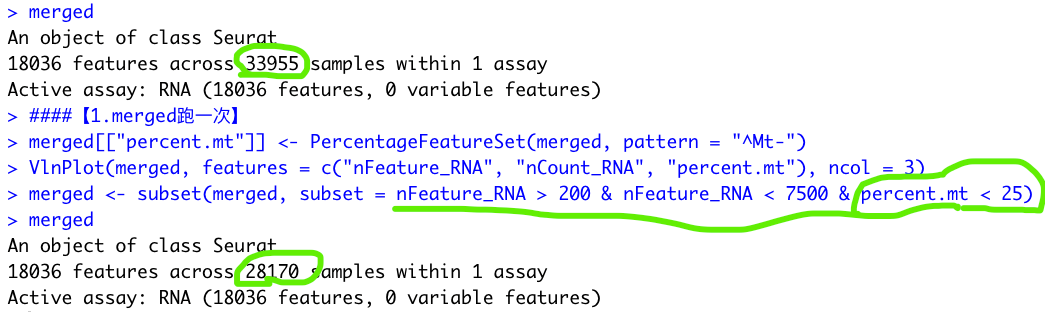
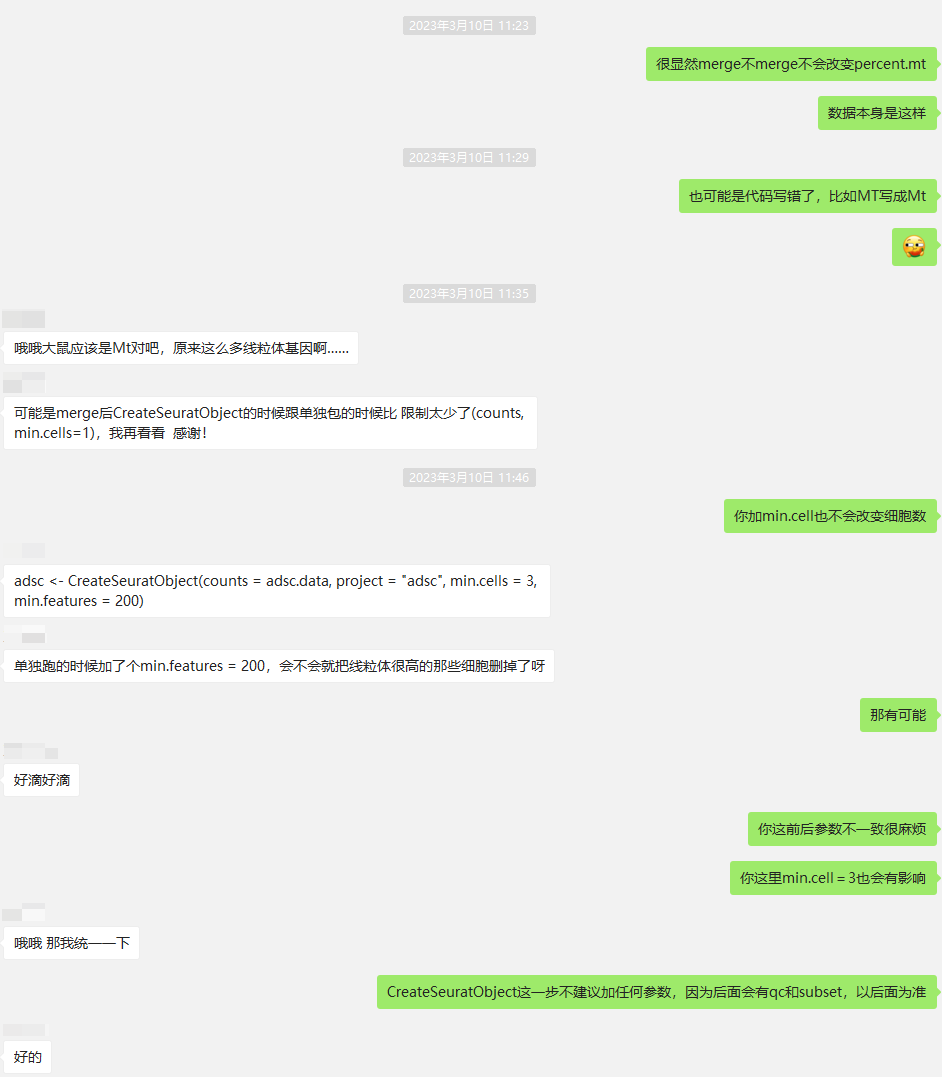
请教一下大家,最右面这个图,4个样本merge后线粒体基因怎么会这么高呀?各自分别跑的时候都没有这么高诶
-
请教大家一个问题,大家质控时,nFeature一般设置多少呀?这群细胞nFeature很低,差异基因很少,cellchat发出和接收的信号都很少,应该在质控时调整cutoff把这群去除嘛?
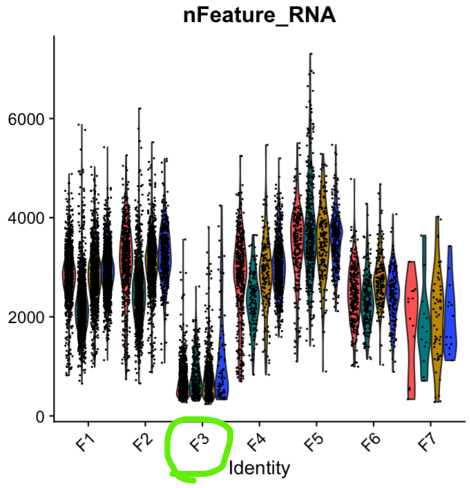
可以的,你的数据feature中位数应该挺高,可以适当增加阈值。可以设成五、六百。然后在scaledata那一步,试一下回归掉基因数,回归与否都试试。
- 我想问问 在回归的时候 判断某个因素是否需要回归 有没有什么依据可循 我看有的文章回归线粒体 有的回归nfeature
4. cellphonedb的环境配置问题
- 求助一个bash脚本运行问题:我把cellphonedb的环境也搭建好了,我单独在terminal中使用conda activate cellphonedb就可以激活环境,然后用bash 运行sh脚本;但是我想学课程的代码把激活环境的代码也放在sh脚本里,直接bash运行sh,然后就运行不了,不知道是什么原因呀
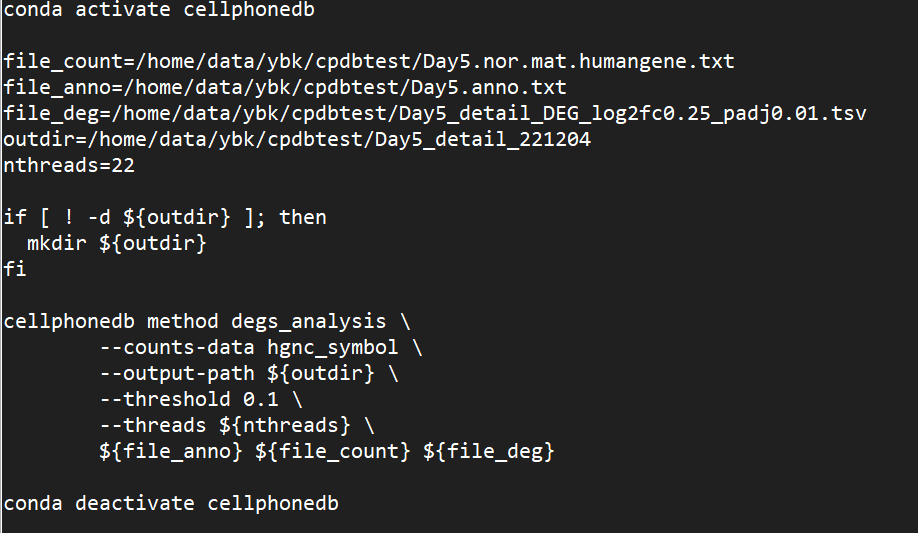
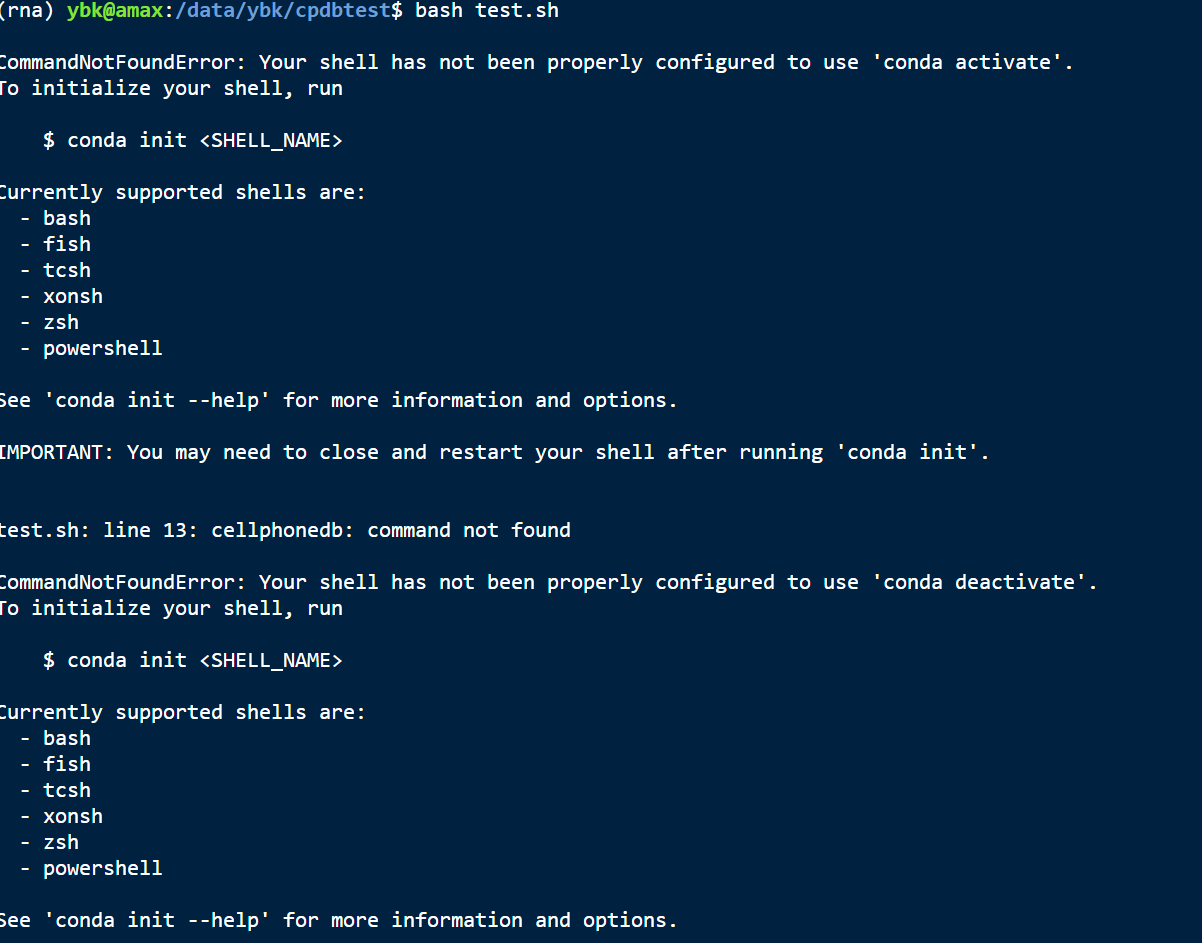
改成下面这种搭配就行了

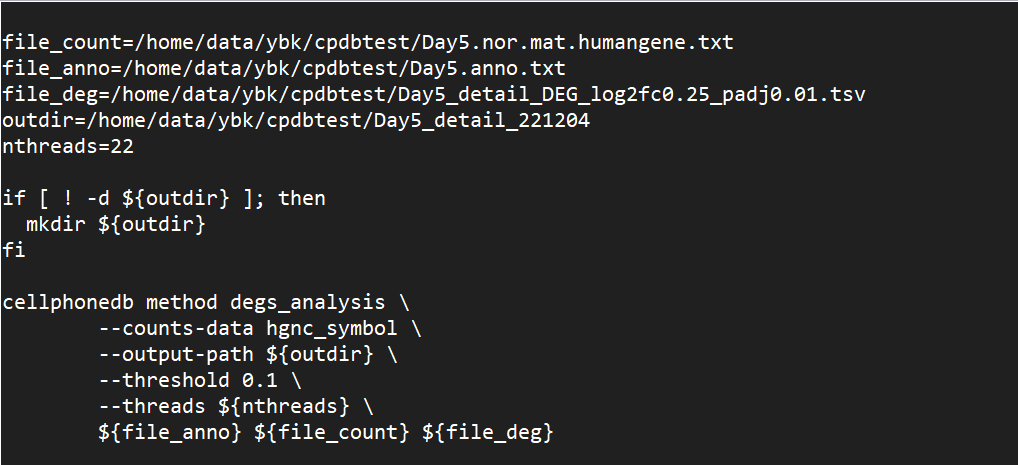
这个问题我不知道原因,也遇到几次。按照你第一种做法,把conda改成source,把activate改成绝对路径(在conda安装包的bin下面),我一般这样改能解决问题
- 想请教一下cellphoneDB安装不上是什么原因呀
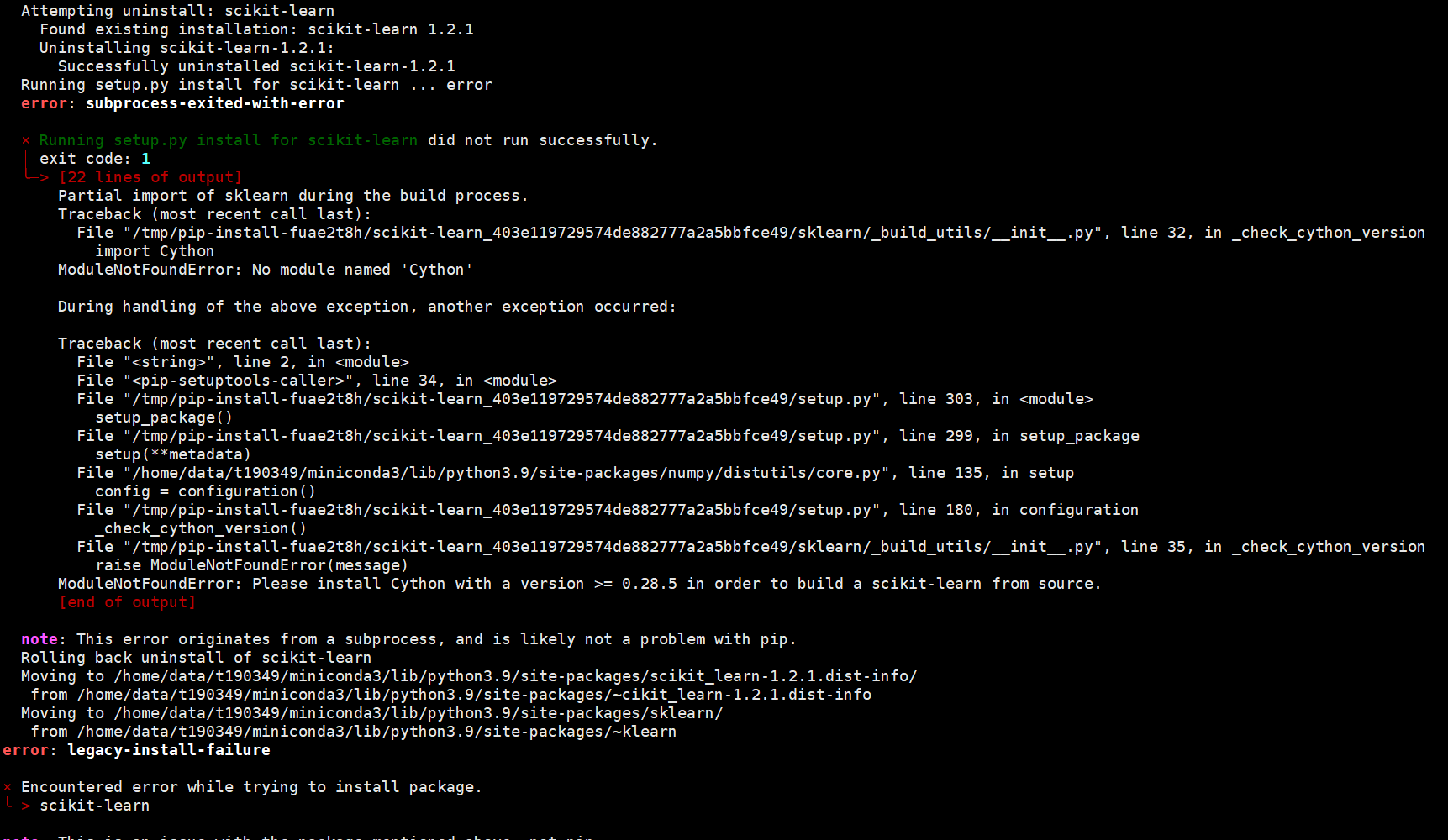
报错是这样

cellphonedb对版本有点严格。按照官网说明,在子环境中下载特定版本的Python。Python需要3.7左右。
- 请问一下,cellphoneDB占用内存大吗?运行久吗?

5. cellphonedb的标准化问题
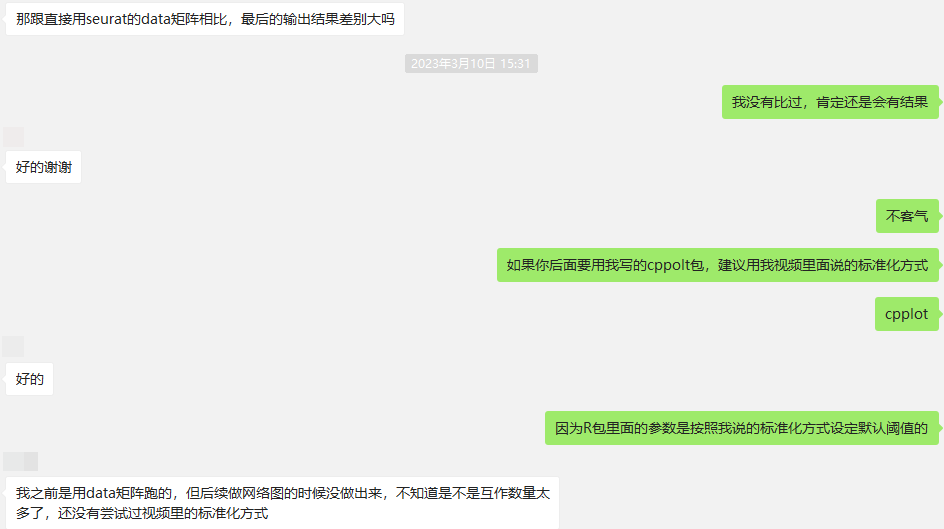
请问cellphonedb给的数据里有标准化之前的那个矩阵吗?
“1_cpdb测试”文件夹中没有直接提供原始count矩阵; 如果需要的话,“2_cellchat测试a”文件夹中有seurat对象的rds文件,可以尝试提取出count矩阵。
好的,所以是相当于对seurat的count矩阵进行标准化是吧?
是的
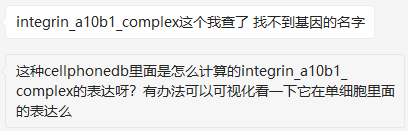
6. cellphonedb中多个亚基的受配体(complex)如何查询具体的基因?

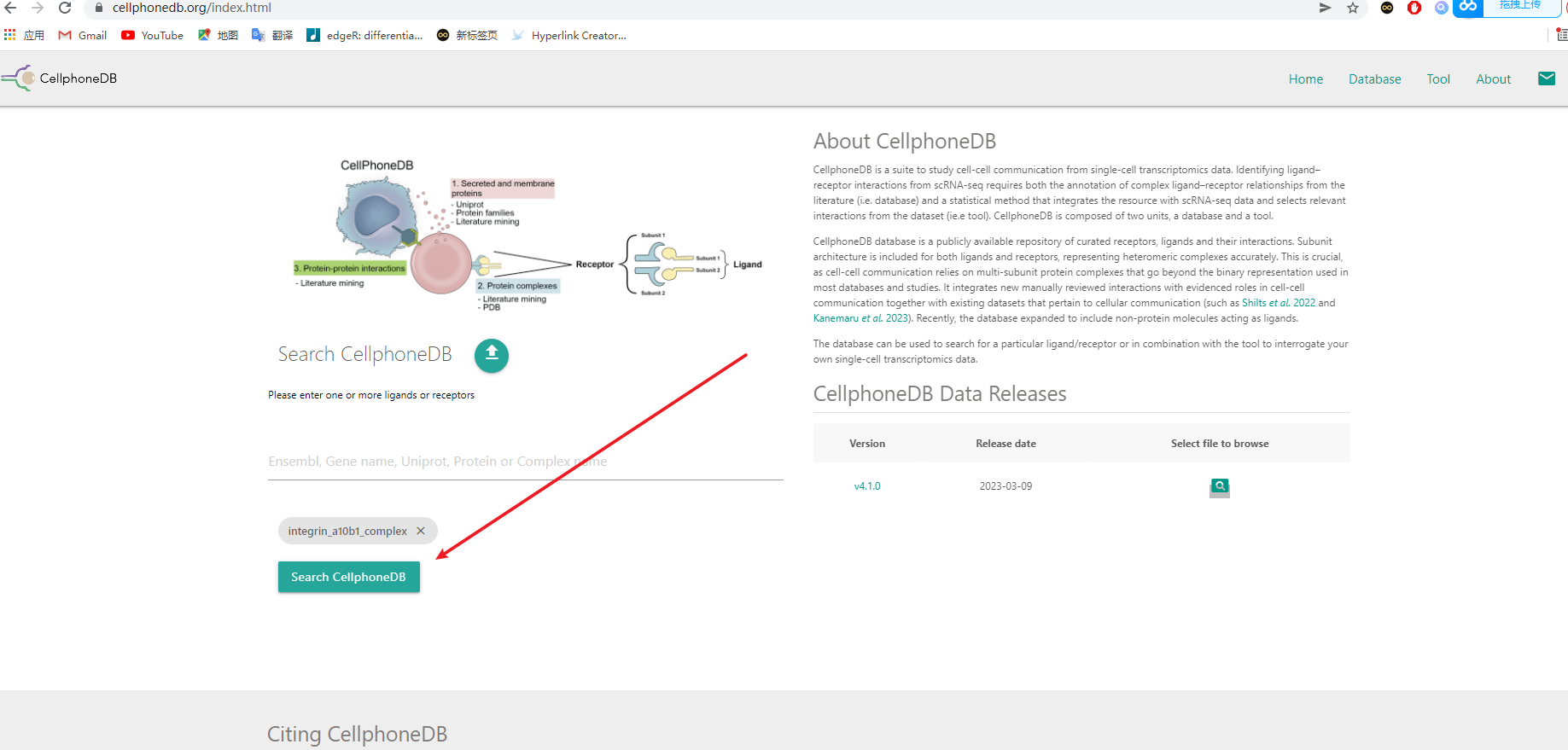
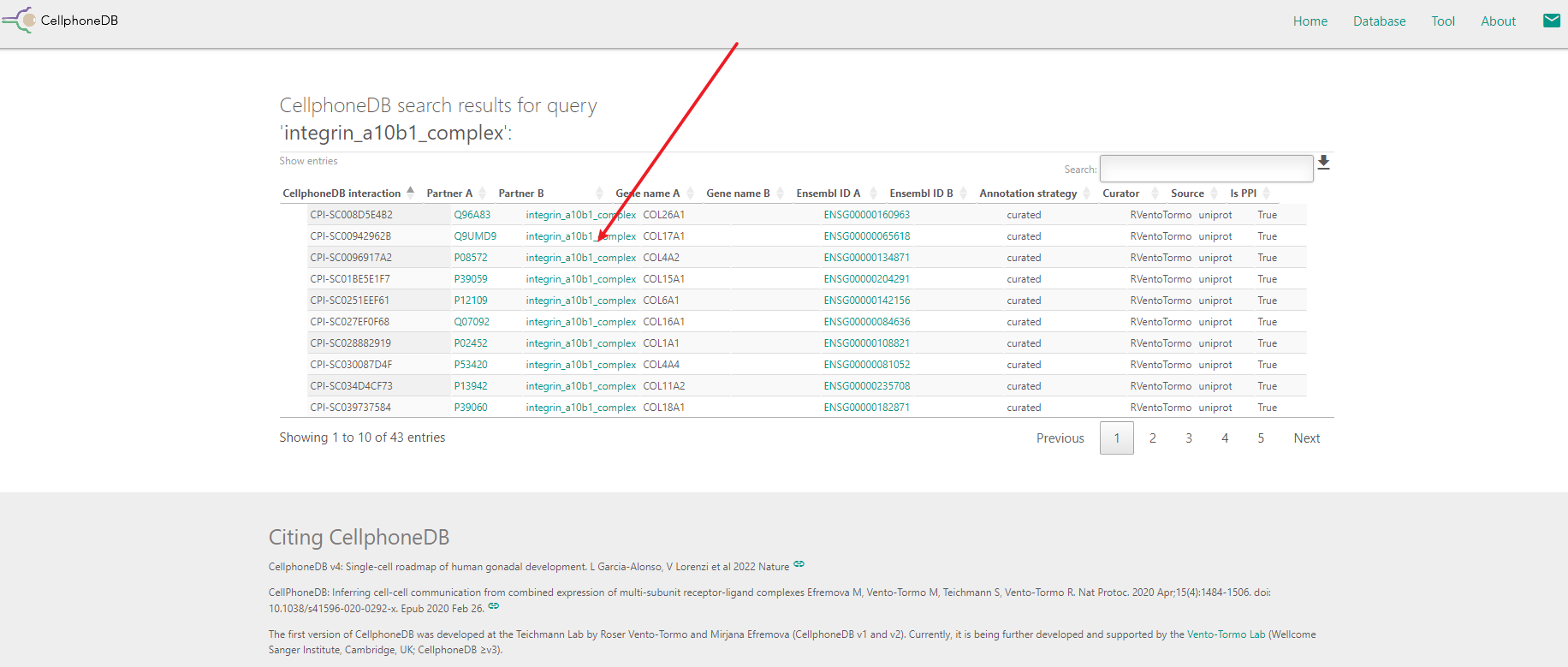
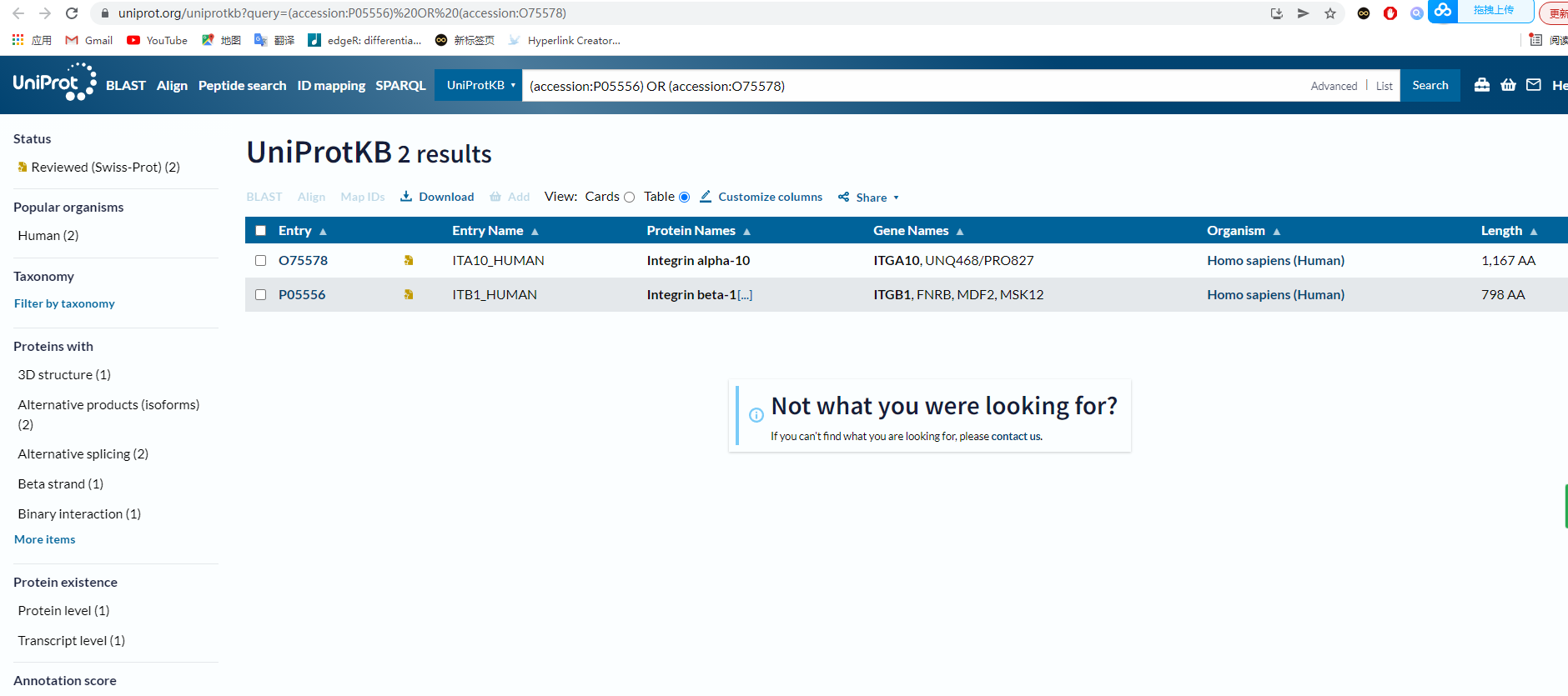
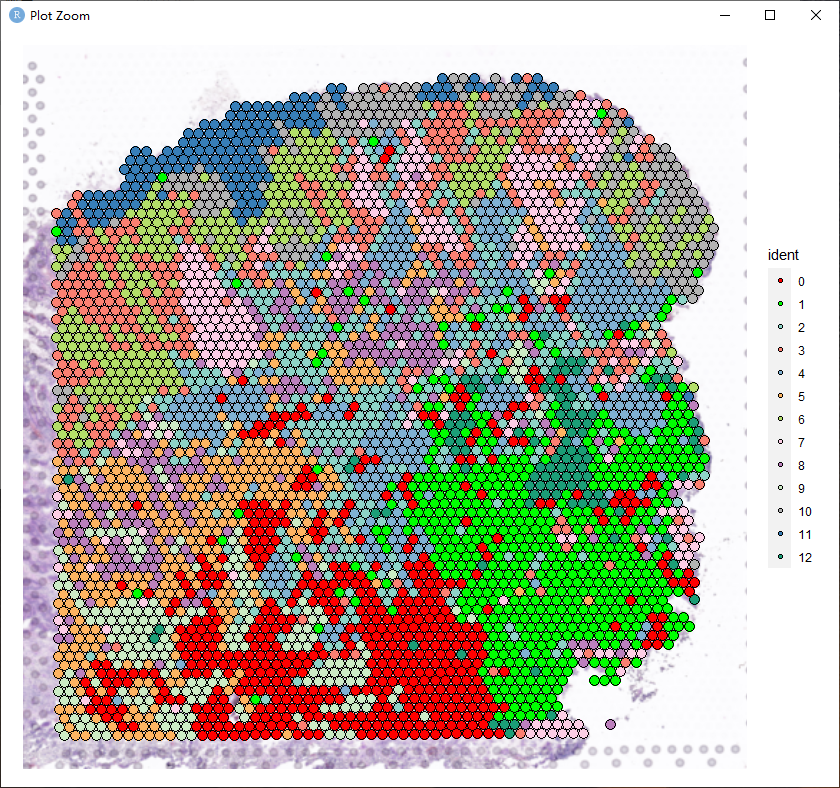
7. 空间转录组绘图
- 请问一下SpatialDimPlot如何修改默认颜色呀?参数cols=修改后画出来还是默认的配色
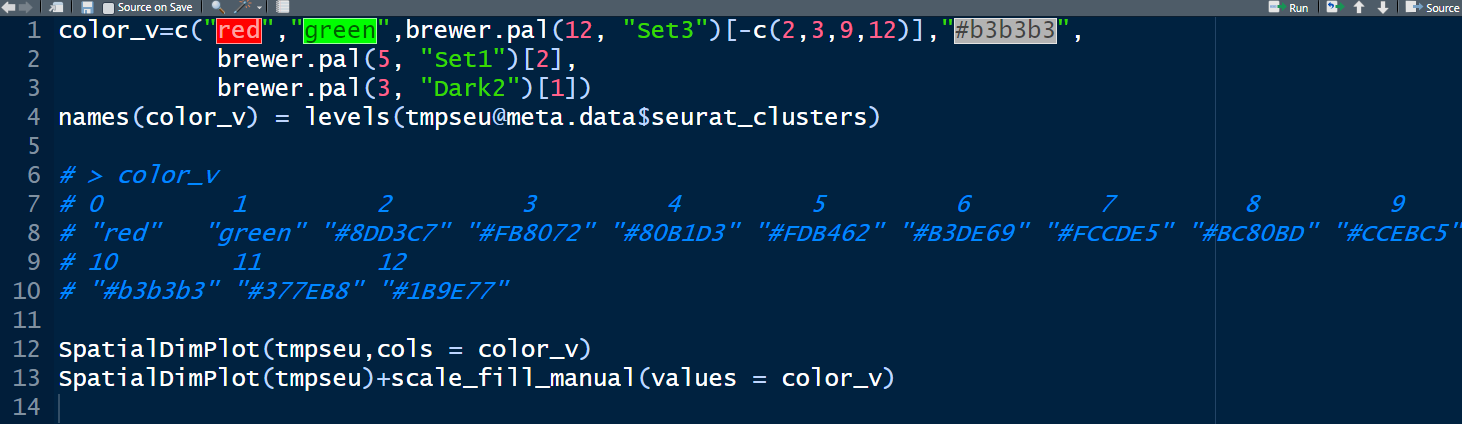
8. cellchat中igraph的问题
- 请问大家跑cellchat两组比较的代码时,到这几句代码有遇到这个报错的嘛,求问怎么解决的呀?

图中链接(https://blog.csdn.net/x_yAOTU/article/details/124085860)
相关内容
热门资讯
前端-session、jwt
目录: (1)session (2&#x...
linux入门---制作进度条
了解缓冲区 我们首先来看看下面的操作: 我们首先创建了一个文件并在这个文件里面添加了...
关于测试,我发现了哪些新大陆
关于测试 平常也只是听说过一些关于测试的术语,但并没有使用过测试工具。偶然看到编程老师...
前缀和与对数器与二分法
1. 前缀和 假设有一个数组,我们想大量频繁的去访问L到R这个区间的和,...
nodejs:本地安装nvm实...
一、背景-使用不同版本node的原因 vue3+ts、nuxt3版本,node...
JAVA集合知识整理
Java集合知识整理 HashMap相关 HashMap的底层数据结构:jdk1.8之...
无刷直流电机介绍及单片机控制实...
无刷直流电机介绍及单片机控制实例前言基本概念优势与劣势使用寿命基本结构使用单片机控制实例电子调速器&...
fwdiary(2) dp2
1.传纸条 AcWing 275. 传纸条 - AcWing 走两条路,走一条最大的...
常用的DOS命令
常用的DOS命令 DOS(Disk Operating System,磁...
<C++> 类和对象(下)
1.const成员函数将const修饰的“成员函数”称之为const成员函数,cons...